如何消除特定卷积的冗余计算

这篇文章分享OPEN AI LAB研究院四月份左右的一个研究工作。主要是研究如何消除特定卷积的冗余计算,从而达到加速的目的。《Exploiting Convolution Computation Reuse in Compiler Workflow》
传统编译器的公共子表达式消除(CSE)是空间上去除冗余计算。这篇文章的思路是,尝试在时间/循环遍历上(loop iteration)上去寻找冗余计算的情况,通过重写计算的pipeline,来减少冗余计算,从而达到加速目的。
公共子表达式消除(CSE)
公共子表达式消除(Common subexpression elimation)是一个经典的编译优化技术,它检测出代码中含有相同表达式的语句,然后用一个中间变量替换该共同表达式,该变量储存该表达式的计算结果的值,以达到减少冗余计算的目的。CSE 在LLVM, GCC中均有实现。
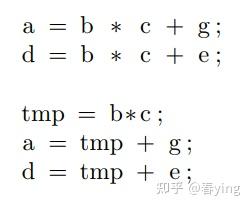
卷积计算
二维卷积的计算为


对于输入X 和权重 K 的值都是任意的(random value)情况来说,卷积计算过程是没有冗余计算的。
我们想要研究在什么情况下,卷积的计算过程有冗余的计算。
从卷积的表达式可以看出,在不同的iteration, 卷积的计算表达式是共同的,但数据依赖于iteration index。假设 iteration i, iteration j, 要想这两个迭代有冗余计算,表达式的输入数据必须有重复的值。对卷积计算来说,一般输入数据的值的run-time的时候才确定,也就在complie-time阶段,input的值的未知,而kernel权重的数据一般在compile-time就可以确定。
因此,问题变成,我们探索不同的kernel pattern, 使得循环迭代过程有冗余的计算可以抽取出来。
情况1:kernel的值 invariant alone one axis
kernel的值沿着某个维度有不变性,可以用以下表达式来表示
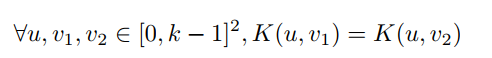

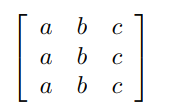
在这种情况下,我们可以通过定义一个中间变量Temp

因为Kernel的值沿着v维度具有不变性,有
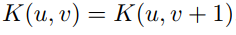
因此, 对于相继的两个输出点 Y(i, j)与 Y(i, j+1), 中间变量Temp的计算结果是可以复用的,下面的推导可以看出,Temp(i,j)的v从1到k-1部分都可复用。
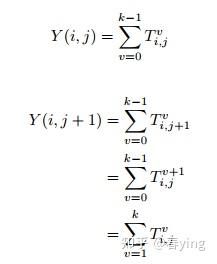
我们对比了前后两种计算,origine的按照原公式的计算,以及通过增加临时变量的计算方法,整体计算量从 O(k的平方)降到O(k),k是kernel的单边size。


情况二,kernel的值 proportional alone one axis
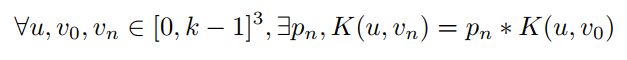

直观来说
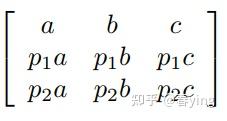
这种情况下的计算复用和上一种情况的推导是类似的,多出的一步是,在计算output的过程中,复用Tmp计算结果,要乘上不同的比例系数pn.


因此,在特定卷积kernel的情况下,卷积去除冗余计算本质上和传统编译器的公共子表达式消除是类似的。不同之处在于,单个卷积的表达式看不出共同部分,需要对相继的loop iteration 展开才可以看出共同的计算部分,并且,不同于公共子表达式消除,这个中间变量也不是一个标量,而是一个带有iteration index的一个表达式。
那么,可能会问的一个问题是如何找到这个中间变量temp从表达式。以2x2的blur模糊计算为例, 展开表达式就可以找到temp的表达式了。
out(x, y) = input(x, y) + input(x+1, y) + input(x,y+1) + input(x+1,y+1)
out(x,y-1) = input(x,y-1)+ input(x+1,y-1) + input(x,y) + input(x+1,y)
common expr = temp(x, y) = input(x, y) + input(x+1, y)
在Halide上的实验
以blur计算为例,在使用halide语言描述计算过程的时候,使用了两种方式描述blur计算过程。一种是根据定义的计算描述,一种是增加temp变量来计算中间计算结果,使得整体可去除冗余计算。然后用Halide的auto-scheduler进行自动调优。
以下是在x86 cpu上测得的结果。第一行的(256x256, 512x5112, 1024x1024)为input的尺寸大小, kernel 的大小分别为5x5, 7x7, 9x9。
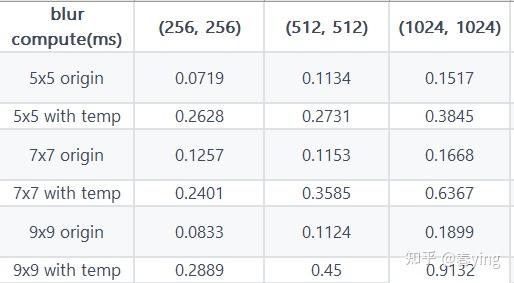

可以看出,通过改写计算表达式(增加temp中间表达式),能够消除冗余计算,减少实际计算量,后续再通过auto-scheduler自动进行并行化,向量化,从而使得整体性能得到加速。
在科学计算的应用
在科学计算中,有限元(Finite Element Method)是一种常见的求解偏微分方程(PDE)的数值求解方法。其中通过有限差分来近似微分计算。下图[1]是科学计算中常见的模板计算(stencil computation), 相同颜色代表kernel在那个点的值相同。
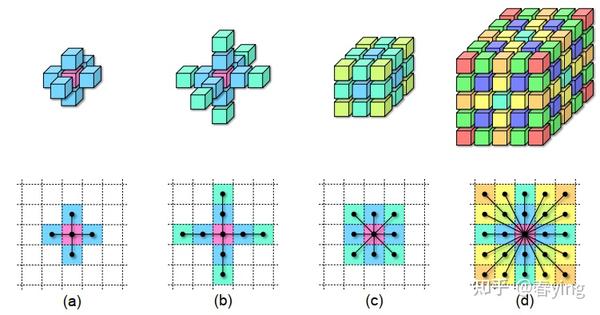

在论文[1]中,对该计算进行重写,本质是为了消除冗余计算。从kernel的颜色可以看出,kernel第一列和第三列的值完全一样,因此可以设置个中间变量来计算该列的计算结果,在计算output值的时候,就可以复用中间变量的计算结果。详情可以看“情况1:kernel的值 invariant alone one axis”的分析。


展望
关于这个技术方向的展望(在编译器里自动化实现),个人认为可以结合多面体polyhedral model技术中对loopnest的分析(尤其是acess matrix的分析),进行一个optimization pass/transformation,自动抽取共同表达式,改写原始的表达式 从而达到在loop iteration中消除冗余计算,加速计算的目的。当然,前提是kernel的值在compile-time已知。
相关论文:
[1]. Basu P, Hall M, Williams S, et al. Compiler-directed transformation for higher-order stencils[C]//2015 IEEE International Parallel and Distributed Processing Symposium. IEEE, 2015: 313-323.
更多文章见自动优化专栏,分享自动优化,编译优化,图优化相关技术:
也欢迎关注OPEN AI LAB的开源推理框架Tengine:
