监督2、AAAI19 具有置信度学习的困难感知注意力网络

Difficulty-Aware Attention Network with Confidence Learning for Medical Image Segmentation (北卡沈老师组文章)
背景
1、关于网络训练中样本的问题:
一个数据集中常规的样本(易分割)比较多,当然也有难分割的样本,但量比较少;因此网络训练过程中倾向于学习容易分割的样本。简而言之:通常网络在难样本上的结果比较差(这是肯定的呀)。然后很容易想到以下两个问题:
- 怎么知道这个样本是难的?
- 如果是难样本,我们让它对网络的贡献大一点。(本文是针对每个样本中找到比较难的区域,然后作为空间权重乘以到交叉熵损失上,就可以啦)
2、GAN作为分割损失函数的发展:
然后GAN的判别器可以作为全局的损失函数使用,最简单的就是让生成的分割图和label图输入到判别器中,让判别器判断0还是1;最后达到判别器分辨不出。此外,判别器还可以当做patch或者加局部区域的损失函数使用,这在图片翻译中(cgan、cyclegan)中常常用到,也就是判别器输出的不是scalar而是一个尺度稍微小一点的特征图,如果是标签图结果就让它得到的特征图全是1,如果输出的是生成图则特征图结果就全是0。最极端的就是让判别器作为像素损失函数来使用,例如下面的文章。(A Refined Equilibrium Generative Adversarial Network for Retinal Vessel Segmentation 2019)
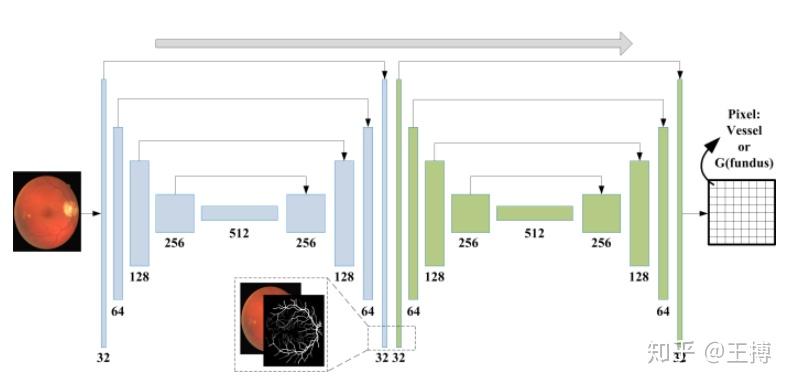

前后两个网络是对称的;左侧是G生成器,它将视网膜眼底图像作为输入并输出视网膜血管的血管概率图;右侧传统D判别器有所不同,D的输出是一个可能性图,其大小与视网膜图像相同,这意味着它可以区分每个像素中的FG(眼底)和血管。这种结构赋予D识别细节差异的能力,将加强对抗训练,以迫使G得到更逼真的血管图像(即FG(眼底)≈血管)。
之前的GAN的判别器的训练是:真实为0;假的为1;直接做分类任务;这里的训练是:输入真实标签图,输出的图所有像素全部标为1;输入生成标签图,输出的图所有像素全部标为0;
本文的方法
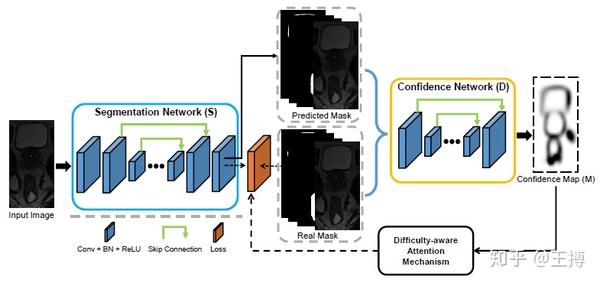

两个网络:分割网络S和置信网络D
1、分割网络
分割网络就是增强版的U-Net:残差卷积块、最下面使用空洞卷积、跳层连接中使用转换模块、然后跳层连接的特征和解码器上采样的特征使用通道注意力模块。(建议大家做相关工作的,如果不是单纯为了发paper的话,不要再魔改U-Net了,作为魔改多年的我,吃了几篇文章的红利,喜提千分点,再看到相关paper就是直接pass,本文虽然加模块但是不是主要工作)
分割网络的训练,用的是类别权重dice和带空间权重的交叉熵;(大家对于这些也不要太关注,就是为了发paper好看点,普通交叉熵+dice难道不香吗)
2、置信网络
置信网络,其实就是上面提到的输出尺度和输入大小一样的通道为1的输出图,每个像素点0表示生成的分割图,1表示真实的label图。这里把这个输出图叫做confidence map 置信度图。因为如果输出图中该像素值大的话,说明这个点越像真实的label,也就是表示这个点与真实图像素点的相关性。
因此这个鉴别器(即置信网络)具有两个作用:提供对抗性学习来训练分割网络(即对抗性学习),同时得到正确分割每个局部区域的置信度(即置信学习)
鉴别器的训练就是对抗损失:使用BCEloss让真实标签结果全是1,生成分割图经过鉴别器的结果全是0. 然后再进一步训练生成器(分割网络)的时候,也需要加上对抗损失:固定鉴别器,让生成器的结果全是1.
我们学到了置信度图,有啥用呢?
3、Difficulty-Aware Attention Mechanism(难度感知注意机制)
前面我们学习到了置信度图M,表示每个像素点是不是接近标签,那么(1-M)就是每个像素点的困难程度,我们将它作为空间权重乘以到前面分割网络训练时候的dice和交叉熵损失上。
