多智能体强化学习 ICML2019论文(1)

Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning


原文传送门:
http://proceedings.mlr.press/v97/jaques19a.html
特色:
本文提出一种机制去计算其它智能体的影响力。智能体对其它智能体的影响力,被认为是有回报的,相当于去奖励智能体在他们的行为之间的高互信息,从而来提高协调与合作,从而对通信协议有一个更好的学习,并且影响力的奖励是使用一种分布式的方式来计算的,能够有效解决突发通信的问题。
动机:
为了实现分布式的计算,并且解决突发通信协调问题
方法:
提出了一种统一的方法来实现MARL中的协调和沟通,方法是通过给智能体一个内在的奖励,从而来对其他智能体的行为产生因果影响。
本文使用反事实推理评估因果影响。在每一步,一个智能体模拟它可能采取的行为、反事实的行动,并评估它们对另一个智能体行为的影响。导致另一方的行为发生相对较大变化的行为被认为是非常有影响力的,并且会得到回报。
(本文直接从像素点训练递归神经网络策略)
通过实验证明了影响力对学习协调是有利的。每个智能体独立训练,每个智能体有一个MOA(对其它智能体建模),训练预测其它智能体的行为,然后,智能体可以模拟反事实行为,并使用自己的内部MOA来预测这些行为将如何影响其他智能体,从而计算自己的内在影响报酬,这种方法是不需要一个集中控制或使用另外一个智能体的奖励。
Sequential Social Dilemmas :具有博弈论收益结构的部分可观测、时空扩展的多智能体博弈
在这些ssd中,一组agent获得的集体奖励清楚地表明了这些agent如何学会合作
影响代理不仅要学会协调他们的行为以获得高回报,他们还必须学会合作。
修改了智能体的奖励为:


在k智能体的作用下,j智能体的边际策略和j的条件策略之间的差异是衡量k对j的因果影响的一个指标


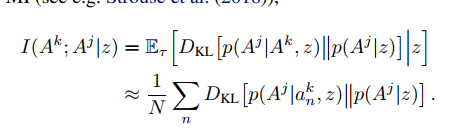

这一个指标与k和j智能体互相信息有关(MI),最大化他们行动之间的相互信息,通过Monte-Carlo 评估 互信息 I(a^k;a^j|s)
通过在每个代理的操作之间引入显式的依赖关系,social影响可以减少策略梯度的差异,这是因为智能体接收到的梯度的条件方差将小于或等于边缘方差。
实验
在通信情况下的:一个是在环境中的策略,一个是发出沟通信息的策略,
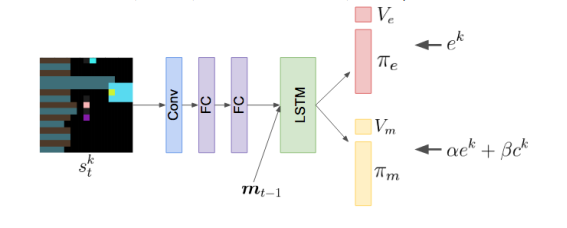

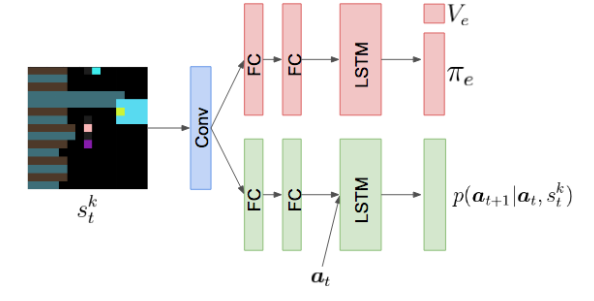
MOA的结构:(需要知道在反事实的情况下另一个行为的概率,)
是训练来预测所有其他智能体的下一步行动鉴于他们之前的行动,和当前智能体的状态,换一句话来说,每个代理都可以“想象”它在每一步可能采取的反事实行动,并使用其内部MOA来预测对其他代理的影响

我们只在一个代理(k)试图影响(j)的时候在其视野内给出影响奖励,因为当j对k可见时,
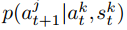
的估计更准确
总结
本文提出一种影响力奖励,来最大化智能体之间的互信息,来产生协调与合作。在通信中,通信的策略和环境的策略是分开的,是否可以一起,会更好。
