[论文简介] 不确定图数据的高效关键字搜索

- 原论文:Efficient Keyword Search on Uncertain Graph Data
- 出版:TKDE 2013
摘要
作为一种流行的搜索机制,关键字搜索已应用于检索文档,文本,图甚至关系数据库中的有用数据。但是,到目前为止,即使不确定图已经在许多实际应用中广泛使用,例如不确定性图数据已广泛用于许多实际应用中,例如道路网络建模,社交网络中的影响力检测以及PPI网络上的数据分析,但到目前为止,仍没有关于关键词搜索的工作。
因此,在本文中,作者研究了不确定图数据上的前k个关键字搜索问题。遵循对确定性图进行关键字搜索的类似答案定义,如果1)它包含所有关键字,则将不确定图中的子树视为关键字查询的答案。 2)根据关键字匹配,得分较高(由用户或应用程序定义); 3)不确定性低。如[1],[2],[3]中所述,在确定性图上进行关键字搜索已经是一个难题。由于存在不确定性,因此在不确定图上进行关键字搜索要困难得多。因此,为了提高搜索效率,作者采用了基于概率关键字索引 PKIndex 的过滤和验证策略。对于每个关键字,都会离线计算基于路径的前k个概率,并将这些值以最佳的压缩方式附加到 PKIndex。在过滤阶段,执行存在概率修剪、基于路径的概率修剪和基于树的概率修剪,这些阶段会过滤掉大多数错误的子树。在验证中,作者提出了一种采样算法来验证候选者。大量的实验结果证明了所提出算法的有效性。
方法与贡献
存在概率修剪
该方法的原则是,过滤掉低于阈值的 top-k 分数概率,并且树的存在概率低于其子树存在概率。
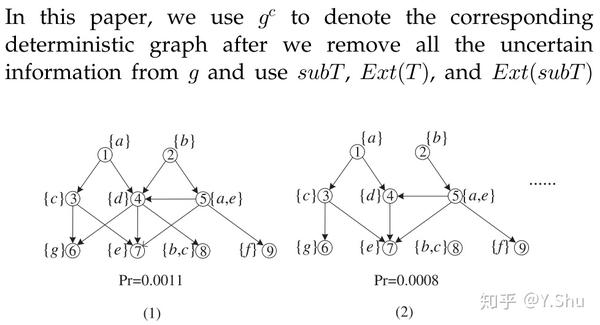



基于路径的概率修剪
作者提出概率关键字索引(probabilistic keyword index, PKIndex)用于基于路径的概率修剪。具体而言,对于每一个不同的关键字 w,存储图中所有到达关键字 w 的最短路径。每个路径 P 都有一个分数,该分数使用相同的排序函数对返回的子树进行计算。 因此,对于每个关键字 w,PKIndex 存储可以达到 w 的路径 P 的前 k 个得分概率。 基于预先计算的 top-k 得分概率,我们可以如下进行路径修剪:
为节省 PKIndex 的空间开销,将 top-k 概率 (0, 1] 的域分为几个区间,因此只有少数 k 值能支持基于路径的概率修剪。另外,也应该存储一个非常大的 k,即 n 来支持基于路径的修剪。作者还根据成本模型优化分区以获取最大的修剪作用。另外,路径可能具有结构上的重叠,因此,路径的概率分布是相关的。 显然,现有技术无法应用于计算路径的 top-k 分数概率。 在作者的方法中,首先建立一个图模型来捕获路径的相关概率分布。 然后,构建一个遍历图模型的随机修复过程,以计算路径的 top-k 分数概率。


基于树的概率修剪
使用泊松二项分布计算子树集合的概率上界。top-k 分数概率小于子树集合的概率上界。