
Bayesian Non-Parametrics for Pattern Recognition


模式识别 (Pattern Recognition) 主要通过比较。
比较就好比拿到了一个新的水果,然后我们发现它长得跟各种苹果很像,所以我们把它分类成苹果。
比较这个概念需要我们先定义相似(similarity),我们可以说两样东西相似是因为距离更近。但是距离这个概念实际上是很难定义的,0和1相比0和2更像,我们可以说这是因为在数轴上,0和1靠的更近 (Euclidean distance)。但是当我们说苹果相比香蕉更像西瓜的时候,我们的依据是什么呢?是形状?又或者是颜色?
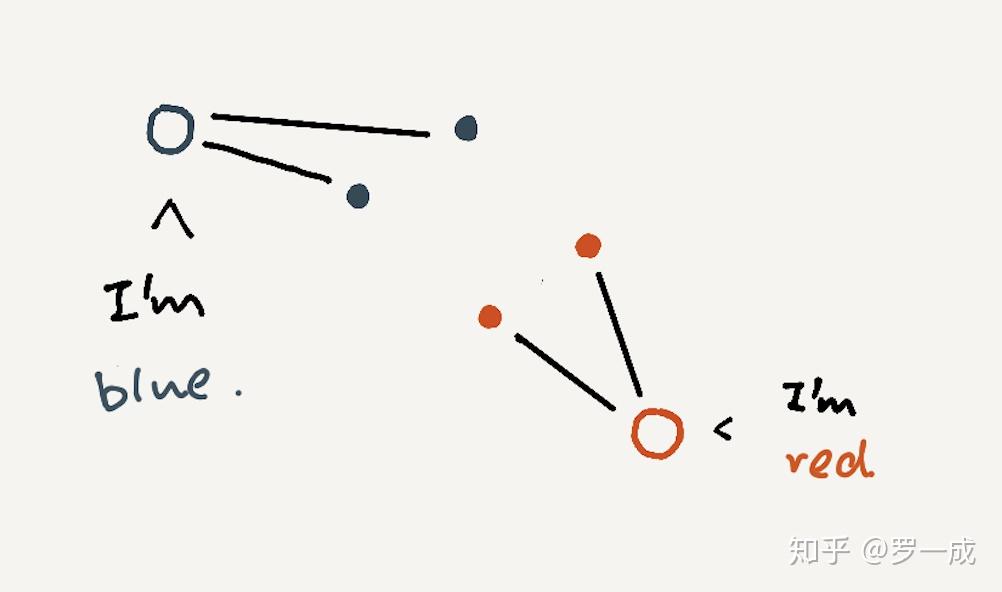
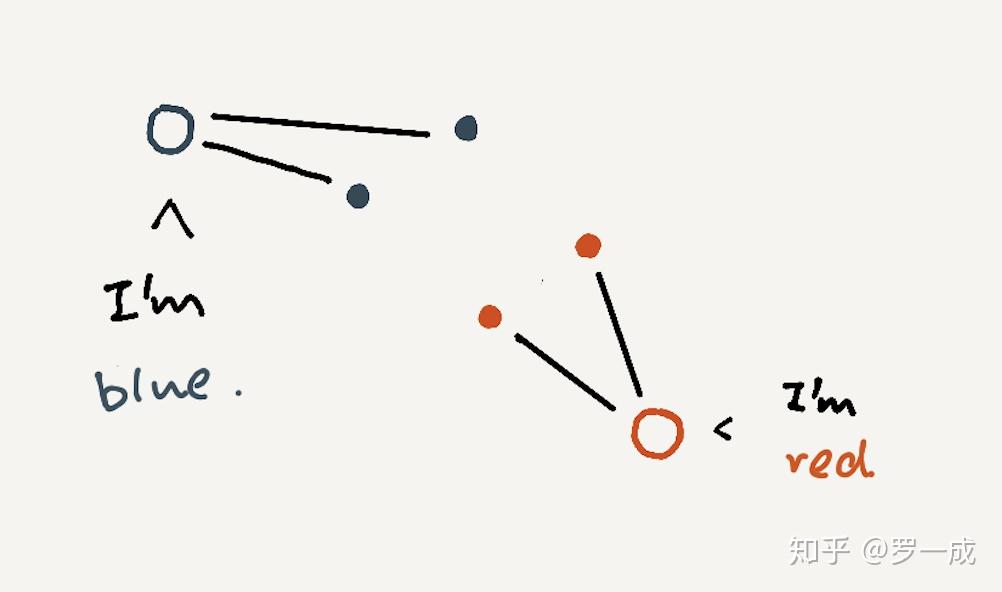
事实上,如果我们知道相似应该怎么定义,模式识别会变得容易,我们甚至知道怎么要模式识别最优。然而当我们不清楚如何定义的相似度的时候,问题就变得复杂起来。为了解决这个问题,我们开始1. 特征工程,也许某些特征会让相似度定义起来简单。2. Kernel tricks,这体现在诸如GP,SVM这类的算法上面,我们通过kernel使得物体在RKHS里面线性可分(SVM)。
然而即便我们知道如何定义相似程度了,模式识别也比想象中还要再困难一点点。
考虑以下这种情况:一个东西如果跟我们之前看到的东西都不太一样,比较是没有意义的。


因此我们需要的实际上是这样一个模型:
1. 当输入跟我们见到过的某些输入很相似的时候,我们能够比较确定的预测结果。
2. 当输入跟我们见过的东西完全不同的时候,我们最好能说我不太确定。
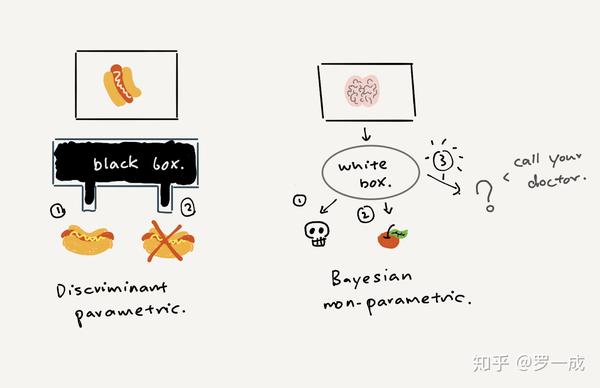

我们不只希望机器能够替我们做预测,更重要的是,在有些场合,比方说金融,医疗,机器人领域,有时候无知与不确定比错的离谱更重要 (better to be uncertain than to be certainly wrong)。因此建模而没有不确定性是没用的 (modeling is useless without uncertainty)。
一个非参数模型很好的捕捉了作比较的这个过程,要预测是猫是狗,我们只需要跟所有我们见过的猫猫狗狗都比较一下就可以了。
这是智能吗? 我想人类的智慧只是这么点,那还真的挺无趣的。
参数模型可能会出现问题,原因在于参数模型一般对于我们判别的过程有很强的假设。参数模型同时用了一个非线性函数逼近了比较的这一过程。
那么我们为什么还更偏向于使用神经网络这样的参数模型呢?所有的问题最后还是回到了算力上面:参数模型近似比较的过程来换取更快的inference time。
当然non-parametrics也可以变快,变快的方法是通过压缩。Sparse GP在对Full GP进行压缩时,采取的做法是假设了条件独立。用了条件独立,我们只需要在判别的时候,跟一小部分例子作比较就好了。
Parametric model 也可以变得更准确,我们把神经网络造的更深一点参数更多一点,这样我们的模型的capacity就更大也许近似就更精确了。
接下来的这个系列的文章, 我们不妨去了解更多的细节,如何去找一个好的相似度量(metric),如何压缩GP,如何压缩neural net,为什么infinite width neural network等于一个GP。我们不妨去参考一下那些很重要文献。之所以写这一系列文章,一是为了锻炼作者本身的写作水平(中文和英文的),绘画水平,分享作者近几年的一些心路历程。更重要的,则是希望不断地去提炼,去总结,去质疑,去拷问。许多的问题虽不热门但却有趣,简单却也深刻。文章不求恢复论文中的每一个细节,但希望能够挖掘隐藏在结论背后的那些真知灼见,引发大家的思考。
