
深度学习邂逅物理:受限玻尔兹曼机原理解析

编译:weakish
【编者按】物理学硕士、深度学习开发者Artem Oppermann介绍了受限玻尔兹曼机的原理。近几年来,随着受限玻尔兹曼机在协同过滤上的大放异彩,这一基于能量的神经网络很受欢迎。
目录
0. 导言
1. 受限玻尔兹曼机
- 1.1 架构
- 1.2 能量模型
- 1.3 概率模型
2. 基于受限玻尔兹曼机实现协同过滤
- 2.1 识别数据中的潜在因子
- 2.2 将潜在因子用于预测
3. 训练
- 3.1 吉布斯采样
- 3.2 对比发散
0. 导言
受限玻尔兹曼机(RBM)是一种属于能量模型的神经网络。本文的读者对受限玻尔兹曼机可能不像前馈神经网络或卷积神经网络那样熟悉。然而,随着RBM在Netflix Prize(知名的协同过滤算法挑战)上大放异彩(当前最先进的表现,击败了大多数竞争者),最近几年这类神经网络很受欢迎。
1. 受限玻尔兹曼机
1.1 架构
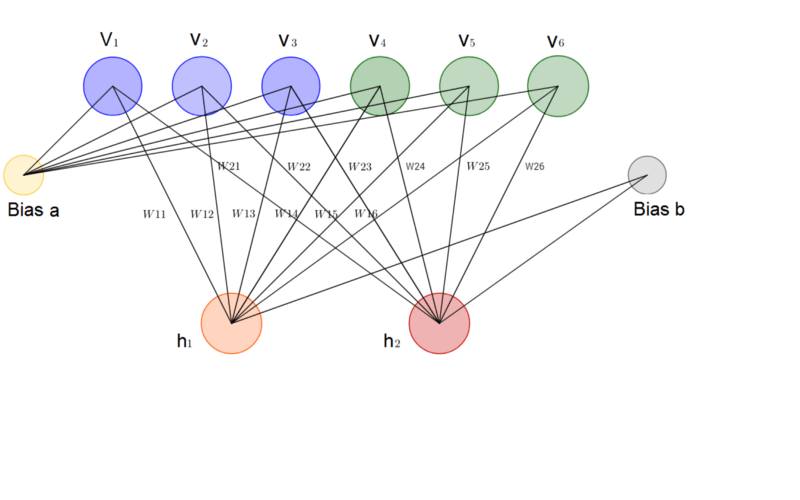
在我看来,RBM是所有神经网络中最简单的架构之一。如下图所示,一个受限玻尔兹曼机包含一个输入层(v_1, …, v_6) ,一个隐藏层 (h_1, h_2) ,以及相应的偏置向量 a, b 。 显然,RBM没有输出层。不过之后我们会看到,RBM不需要输出层,因为RBM进行预测的方式和通常的前馈神经网络不同。
1.2 能量模型
乍看起来,能量这一术语和深度学习没什么关系。相反,能量是一个物理概念,例如,重力势能描述了具有质量的物体因重力而具有的相对其他质量体的潜在能量。不过,有些深度学习架构使用能量来衡量模型的质量。

深度学习模型的目的之一是编码变量间的依赖关系。给变量的每种配置分配一个标量作为能量,可以描述这一依赖关系。能量较高意味着变量配置的兼容性不好。能量模型总是尝试最小化一个预先定义的能量函数。
RBM的能量函数定义为:
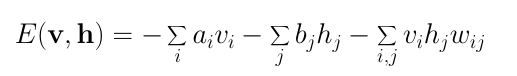

由定义可知,能量函数的值取决于变量/输入状态、隐藏状态、权重和偏置的配置。RBM的训练包括为给定的输入值寻找使能量达到最小值的参数。
1.3 概率模型
受限玻尔兹曼机是一个概率模型。这一模型并不分配离散值,而是分配概率。在每一时刻RBM位于一个特定的状态。该状态指输入层 v 和隐藏层 h 的神经元值。观察到 v 和 h 的特定状态的概率由以下联合分布给出:
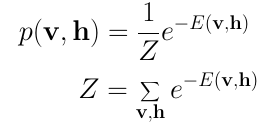
这里 Z 被称为配分函数(partition function),该函数累加所有输入向量和隐藏向量的可能组合。
这是受限玻尔兹曼机和物理学第二个相遇的地方。在物理学中,这一联合分布称为玻尔兹曼分布,它给出一个微粒能够在能量E的状态下被观测到的概率。就像在物理中一样,我们分配一个观测到状态 v 和 h 的概率,这一概率取决于整个模型的能量。不幸的是,由于配分函数 Z 中 v 和 h 所有可能的组合数目十分巨大,计算这一联合分布十分困难。而给定状态 v 计算状态 h 的条件概率,以及给定状态 h 计算状态 v 的条件概率则要容易得多:
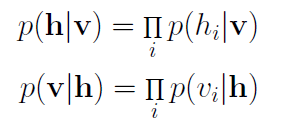
RBM中的每个神经元只可能是二元状态0或1中的一种。我们最关心的因子是隐藏层或输入层地神经元位于状态1(激活)的概率。给定一个输入向量 v ,单个隐藏神经元 j 激活的概率为:
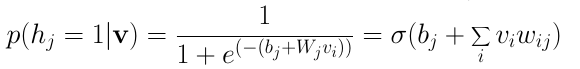

其中, σ 为sigmoid函数。以上等式可由对之前的条件概率等式应用贝叶斯定理推导得出,这里不详细介绍其中的推导过程。
类似地,单个输入神经元 i 为1的概率为:
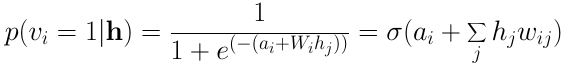

2. 基于受限玻尔兹曼机实现协同过滤
2.1 识别数据中的潜在因子
让我们假定,我们找了一些人,让他们给一批电影打分(一星到五星)。在经典因子分析背景下,每部电影可以通过一组潜在因子来解释。例如,《哈利波特》和《速度与激情》可能分别与奇幻、动作这两个潜在因子有密切的关系。另一方面,喜欢《玩具总动员》和《机器人总动员》的用户可能和皮克斯这个潜在因子密切相关。RBM可以用来分析和找出这些潜在因子。经过一些epoch的训练,神经网络多次见到数据集中的每个用户的所有评分。此时模型应该已经基于用户的偏好和所有用户的协同口味学习到了隐藏的潜在因子。
隐藏因子分析以二元的方式进行。用户并不向模型提交具体的评分(例如,一到五星),而是简单地告知喜欢(评分为1)还是不喜欢(评分为0)某部特定的电影。二元评分值表示输入层的输入。给定这些输入,RBM接着尝试找出数据中可以解释电影选择的潜在因子。每个隐藏神经元表示一个潜在因子。给定一个包含数以千计的电影的大规模数据集,我们相当确定用户仅仅观看和评价了其中一小部分电影。另外,有必要给尚未评分的电影分配一个值,例如,-1.0,这样在训练阶段网络可以识别未评分的电影,并忽略相应的权重。
让我们看一个例子。一个用户喜欢《指环王》和《哈利波特》,但不喜欢《黑客帝国》《搏击俱乐部》《泰坦尼克》。用户还没有看过《霍比特人》,所以相应的评分为-1. 给定这些输入,玻尔兹曼机可能识别出三个对应电影类型的隐藏因子戏剧、奇幻、科幻。
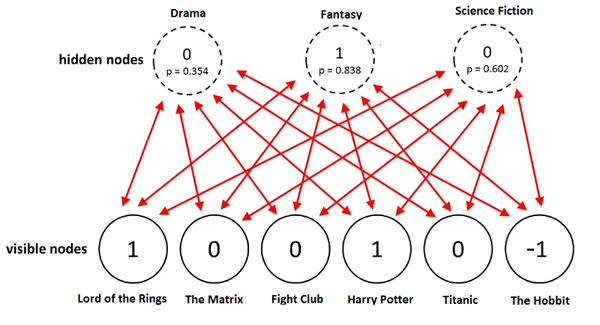

给定电影,RBM为每个隐藏神经元分配一个概率 p(h|v) 。使用概率 p 从伯努利分布中取样得到最终的神经元的二元值。
在这个例子中,只有表示类型奇幻的隐藏神经元被激活。给定这些电影评分,受限玻尔兹曼机能够正确识别用户最喜欢奇幻类型的电影。
2.2 将潜在因子用于预测
训练之后,我们的目标是预测没看过的电影的二元评分。给定特定用户的训练数据,网络能够基于用户的偏好识别潜在因子。由于潜在因子由隐藏神经元表示,我们可以使用 p(v|h) 从伯努利分布取样,以找出哪个输入神经元处于激活状态。
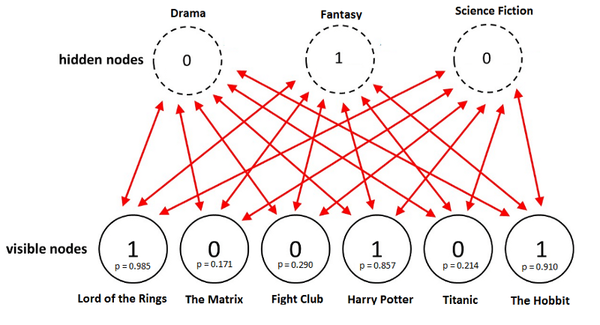

上图中,网络成功地识别出奇幻为用户偏爱的电影类型,并预测用户会喜欢《霍比特人》。
总结一下,从训练到预测的全过程如下:
- 基于所有用户的数据训练网络。
- 在推理时刻,获取某个特定用户的训练数据。
- 基于这一数据得出激活的隐藏神经元。
- 基于隐藏神经元的值得出激活的输入神经元。
- 输入神经元的新值显示了用户将对没看过的电影作出的评价。
3. 训练
受限玻尔兹曼机的训练过程和基于梯度下降的常规神经网络的训练过程不同。本文不会详细介绍具体的训练过程(感兴趣的读者可以阅读受限玻尔兹曼机的原始论文),相反,我们将简单地概览一下其中的两个主要的训练步骤。
3.1 吉布斯采样
训练的第一个关键步骤称为吉布斯采样(Gibbs Sampling)。给定输入向量 v ,我们使用前面提到的 p(h|v) 公式预测隐藏值 h 。得到了隐藏值之后,我们又使用前面提到的 p(v|h) 公式预测新输入值 v 。这一过程辗转重复 k 次。经过 k 个迭代后,我们得到了输入向量 v_k ,这是基于原始输入值 v_0 的重建值。
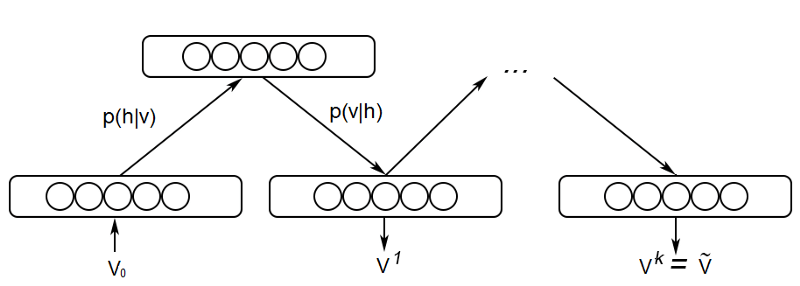

3.2 对比发散
在对比发散(Contrastive Divergence)这一步骤中,模型更新权重矩阵。使用向量 v_0 和 v_k 计算隐藏值 h_0 和 h_k 的激活概率。这些概率的外积和输入向量 v_0 、 v_k 的差别为更新矩阵(update matrix):
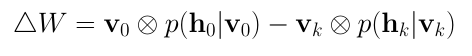

基于更新矩阵,使用梯度上升(gradient ascent)方法更新权重:

参考
- https://www.cs.toronto.edu/~rsalakhu/papers/rbmcf.pdf (受限玻尔兹曼机的原始论文)
- https://www.cs.toronto.edu/~hinton/absps/guideTR.pdf (受限玻尔兹曼机训练指南)
