
Machine Learning Handbook(3)

4 卷积神经网络
- 卷积:在泛函分析中,卷积是通过两个函数f和g生成第三个函数的一种数学算子,表征函数f与g经过翻转和平移的重叠部分的面积。
连续函数:
s(t) = (x * \omega)(t) = \int_{-\infty}^{\infty} x(a) \omega (t-a) da
离散函数:
s(t) = (x * \omega)(t) = \sum_{a=-\infty}^{\infty} x(a) \omega (t-a)
在卷积神经网络中,卷积的第一个参数(x)通常叫作输入,第二个参数(ω)通常叫作核函数。输出有时候被称作特征映射。
在机器学习应用中,输入通常是多维数组的数据,而核通常是由学习算法优化得到的多维数组的参数。我们把这些多维数组叫作张量(Tensor)。
S(i, j) = (I * K)(i, j) = \sum_m \sum_n I(m, n) K(i - m, j - n)
卷积是可交换的
S(i, j) = (K * I)(i, j) = \sum_m \sum_n I(i - m, j - n) K(m, n)
互相关函数(cross-correlation):和卷积运算几乎一样,但没有对核进行翻转
S(i, j) = (I * K)(i, j) = \sum_m \sum_n I(i + m, j + n) K(m, n)
许多机器学习的库实现的就是互相关函数但称之为卷积。
为什么卷积网络在图像识别任务中表现很好?
1. 参数共享:在图像某一部分有效的特征检测器对另一部分可能也有效。例如,边缘检测器可能对图像的很多部分都有用。参数共享需要较少的参数数量并且具有较鲁棒的平移不变性。
2. 稀疏连接:每个输出层只是少量输入的函数(尤其是,滤波器的尺寸)。这大幅降低了网络的参数数量,加快了训练速度。
- 池化:使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。实证研究表明最大池化在卷积神经网络中非常有效。通过对图像进行下采样,我们可以减少参数数量,使特征在缩放或方向变化时保持不变。
1. 一般池化(generic pooling),即作用于图像中不重叠区域,通常有平均池化、最大池化以及随机池化(stochastic pooling)等方法。其中,随机池化来自Zeiler等人ICLR 2013的论文Stochastic pooling for regularization of deep convolutional neural networks。
2. 重叠池化(overlapping pooling),来自Hinton等人的论文Imagenet classification with deep convolutional neural networks。
3. 空间金字塔池化(spatial pyramid pooling),来自Kaiming He等人的论文Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition。
- 填充(Padding):通常用于保证卷积过程中输入和输出张量的维度是一样的。它还可以使图像边缘附近的帧对输出的贡献和图像中心附近的帧一样。
- 步幅(Stride):步幅控制着过滤器围绕输入内容进行卷积计算的方式。例如,过滤器通过每次移动一个单元的方式对输入内容进行卷积。过滤器移动的距离就是步幅。在该例子中,步幅被默认设置为1。步幅的设置通常要确保输出内容是一个整数而非分数。
- 残差网络(ResNet):从LeNet-5,AlexNet,VGG-16到最新的网络架构设计来看,高效网络架构中层的通道规模不断扩大,宽度和高度不断下降。
为什么残差网络如此有效?
对于普通的网络来说,由于梯度下降或梯度爆炸,训练误差并不是随着层数增加而单调递减的。而残差网络具备前馈跳过连接(Feed-Forward Skipped Connection),可以在性能不出现下降的情况下训练大型网络。
- NIN:指的是一个使用了 1 x 1 尺寸的过滤器的卷积层。
来自Min Lin等人的论文Network In Network。
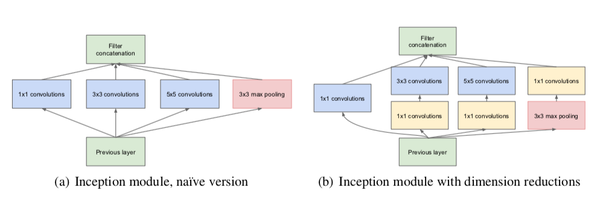
- Inception:将1x1,3x3,5x5的conv和3x3的pooling,堆叠在一起,一方面增加了网络的宽度,另一方面增加了网络对尺度的适应性。

- 数据扩充:随机裁剪,水平翻转,垂直轴对称调换等。
详细描述见上面第3部分正则化。
- 迁移学习:即所谓的有监督预训练(Supervised Pre-training)。使用GPU从头开始训练大型神经网络,如Inception可能需要数周时间。因此,我们需要下载预训练网络中的权重,仅仅重训练最后的softmax层(或最后几层),以减少训练时间。原因在于相对靠前的层倾向于和图像中更大的概念相关——如边缘和曲线。
比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,比如我们先对ImageNet图片数据集先进行网络的图片分类训练。这个数据库有大量的标注数据。
- 目标定位
- 特征点检测
- 动态识别
1. 滑动窗口(sliding windows):每一幅静态的图片里,定义一个像滤镜一样的窗口,在这个窗口从左到右,从上到下不断的扫描,每个窗口都会做一个判断,每个小窗口都有对应的图片,来判断这里面有没有我想要的物品。
2. YOLO(You Only Look Once):把图片按照网格(Grid)分析,分成了很多小网格,在每个网格里判断物品的重心(Center)会在哪里。同样它也会判断小网格里面有没有目标物体,如果有的话就会提供一个很高的概率。当把这些发现有物品的小窗口全部合在一起,变成一个大的窗口时,就需要设一个相应的域值,域值超过一定数值,说明物品确实存在于小窗口中。把小窗口全部连接起来,就会得到大一点的图片,同样再通过CNN做一次判断,判断这是不是对概率有所提高或者降低,这样就可以知道通过每个小图拼凑起来的大图应该是个完整的物品。
- Bounding Box预测
- 非极大值抑制
- Anchor Boxes
- RPN网络
- 人脸识别:人脸识别是one-shot学习问题,通常,你只有一张图像来识别这个人。解决的办法是学习一个相似性函数,给出两个图像之间的差异程度。所以,如果图像是同一个人,函数的输出值较小,而不同的人则相反。
- 零次学习(Zero-Shot Learning):也被称为零数据学习,指的是没有标注样本的迁移任务。
- 一次学习(One-Shot Learning):指的是只有一个标注样本的迁移任务。
- Siamese网络:人脸识别中的一种方法,该神经网络的训练目标是:如果输入图像是同一个人的,则编码距离相对较小。具体来说,Siamese网络使用二元或三元(++-)输入,训练模型使相似样本之间的距离尽可能小,而不相似样本之间的距离尽可能大。该方法将两个人的图像输入到同一个网络中,然后比较它们的输出。如果输出类似,则是同一个人。
- Triplet损失:这个想法的核心在于图片的三个维度,即Anchor(A)、Positive(P)和Negative(N)在训练过后,A和P的输出距离大大小于A和N的输出距离。
5 序列模型
序列模型(如RNN和LSTM)极大地改变了序列学习,序列模型可通过注意力机制获得增强。序列模型在语音识别、音乐生成、情感分类、DNA序列分析、机器翻译、视频活动识别、命名实体识别等方面有很多应用。
- 循环神经网络(RNN):出现于上世纪80年代,最近由于网络设计的推进和GPU计算能力的提升,循环神经网络变得越来越流行。这种网络尤其对序列数据非常有用,因为每个神经元或者单元能用它的内部存储来保存之前输入的相关信息。在语言的案例中,"I had washed my house"这句话的意思与"I had my house washed"大不相同。这就能让网络获取对该表达更深的理解。RNN有很多应用,在自然语言处理(NLP)领域表现良好。
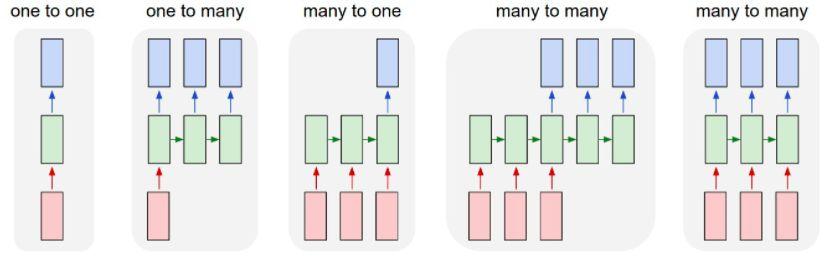

下面举一个例子:
a^{(t)} = b + Wh^{(t-1)} + Ux^{(t)}
h^{(t)} = tanh(a^{(t)})
o^{(t)} = c + Vh^{(t)}
\hat{y}^{(t)} = softmax(o^{(t)})
L(\{x^{(1)}, ..., x^{(\tau)}\}, \{y^{(1)}, ..., y^{(\tau)}\}) = \sum_t L^{(t)} = -\sum_t \log p_{model}(y^{(t)} | \{x^{(1)}, ..., x^{(t)}\})
- 双向RNN:双向RNN和深度RNN是构建强大序列模型的有效方法。缺点是在处理之前需要整个序列。
- LSTM:使用传统的通过时间反向传播(BPTT)或实时循环学习(Real Time Recurrent Learning, RTRL),在时间中反向流动的误差信号往往会爆炸(explode)或者消失(vanish)。但LSTM可以通过遗忘和保留记忆的机制减少这些问题。LSTM单元一般会输出两种状态到下一个单元,即单元状态和隐藏状态。记忆块负责记忆各个隐藏状态或前面时间步的事件,这种记忆方式一般通过三种门控机制来实现,即输入门、遗忘门和输出门。
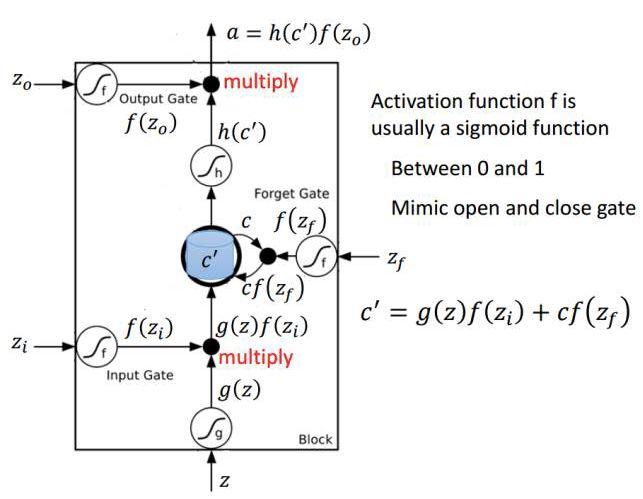

f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
\tilde{C}_t = tanh(W_C \cdot [h_{t-1}, x_t] + b_C)
C_t = f_t * C_{t-1} + i_t * \tilde{C}_t
o_t = \sigma(W_o [h_{t-1}, x_t] + b_o)
h_t = o_t * tanh(C_t)
- 通过时间反向传播(BPTT):与前馈神经网络类似,LSTM网络的训练同样采用的是误差的反向传播算法(BP),不过因为LSTM处理的是序列数据,所以在使用BP的时候需要将整个时间序列上的误差传播回来。
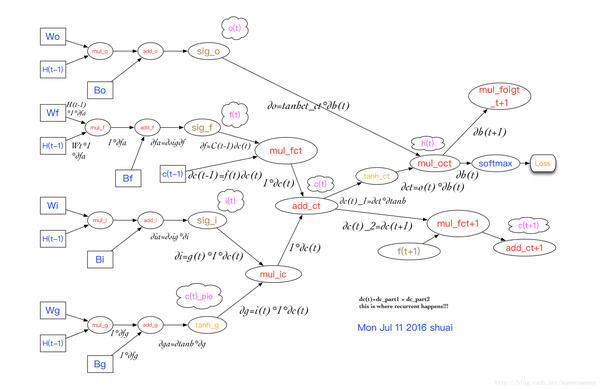

- GRU:旨在解决标准RNN中出现的梯度消失问题。GRU有两个门,即一个重置门(reset gate)和一个更新门(update gate)。从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为1,更新门设置为0,那么我们将再次获得标准RNN模型。


z = \sigma(x_t U^z + s_{t-1} W^z)
r = \sigma(x_t U^r + s_{t-1} W^r)
h = tanh(x_t U^h + (s_{t-1} \circ r) W^h)
s_t = (1 - z) \circ h + z \circ s_{t-1}
- 词表征(Word Representation):词表征在自然语言处理中是必不可少的部分,从早期的独热编码到现在流行的词嵌入,研究者一直在寻找高效的词表征方法。
- Word2Vec:Word2Vec方法由两部分组成。首先是将高维one-hot形式表示的单词映射成低维向量。例如将10,000列的矩阵转换为300列的矩阵,这一过程被称为词嵌入。第二个目标是在保留单词上下文的同时,从一定程度上保留其意义。Word2Vec实现这两个目标的方法有Skip-Gram和 CBOW等,Skip-Gram会输入一个词,然后尝试估计其它词出现在该词附近的概率。还有一种与此相反的被称为连续词袋模型(Continuous Bag Of Words,CBOW),它将一些上下文词语作为输入,并通过评估概率找出最适合(概率最大)该上下文的词。
- 负采样(Negative Sampling):通过使每一个训练样本仅仅改变一小部分的权重而不是所有权重,常用于Word2Vec模型中。
- GloVe:Jeffrey Pennington等人在GloVe: Global Vectors for Word Representation一文中提出的另一种词表征方法。
J = \sum_{i=1}^N \sum_{j=1}^N f(X_{i, j})(v_i^T v_j + b_i + b_j -\log(X_{i, j}))^2
- 注意力机制(Attention Mechanism):旨在解决编码器-解码器架构的缺陷。我们通常是使用基于上下文的注意力生成注意力分布。参与的RNN会生成一个描述它想关注内容的查询。每一个条目和这个查询做点乘来产生一个分数,这个分数描述这个条目与查询的匹配程度。这些分数被输入一个softmax来生成注意力分布。
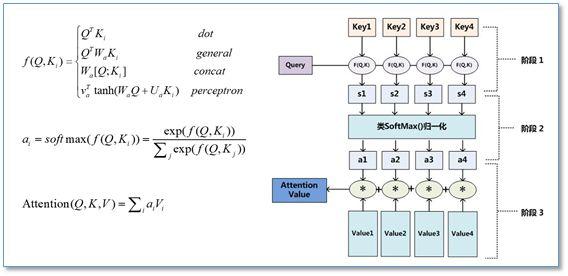

- Self-Attention:来自Google团队NIPS 2017的论文Attention is All You Need。
- 概率图模型(Probabilistic Graphical Model, PGM):由图灵奖得主Judea Pearl提出。PGM利用图来表示与模型有关的变量的联合概率分布。基本的概率图模型包括贝叶斯网络、马尔可夫网络和隐马尔可夫网络(HMM)。这里推荐Daphne Koller的专著Probabilistic Graphical Models: Principles and Techniques。
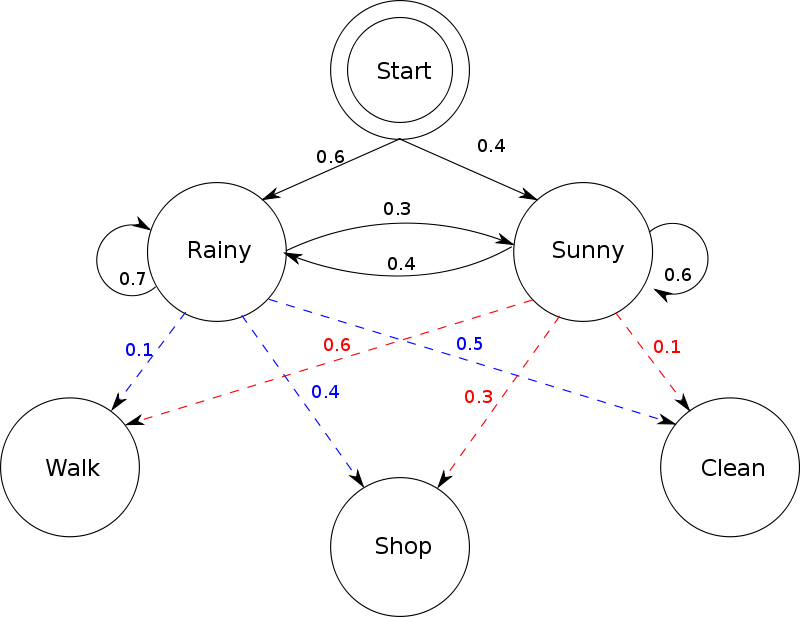
- Hidden Markov Model(HMM):是一种generative model。HMM可以描述为一条隐藏的马尔可夫链生成的状态随机序列(state sequence)Q=( q_1, q_2, ..., q_T)是不可观测的,并记所有可能状态的集合为 S={ S_1, S_2, ..., S_N};由它们产生一个可观测的观测随机序列(observation sequence)O=( o_1, o_2, ..., o_T),并记所有可能观测的集合为 V={ v_1, v_2, ..., v_M}。因此,实际上HMM是个双重随机过程(doubly embedded stochastic process),一个是状态转移,另一个是由状态释放出观测值。在序列标注(Sequence labelling)任务中,模型就是需要对状态序列进行标注。
贝叶斯公式:
P(Q|O) = \frac{P(O, Q)}{P(O)} = \frac{P(O|Q) P(Q)}{P(O)}
对于给定序列O来说,P(O)是确定的,所以HMM的任务是建模P(O, Q)。
一阶马尔可夫链:
P(q_t|q_1, o_1, ..., q_{t-1}, o_{t-1}) = P(q_t|q_{t-1})
P(q_1, q_2, ..., q_t) = P(q_1)P(q_2|q_1)P(q_3|q_1, q_2) ... P(q_t|q_1, ..., q_{t-1}) = P(q_1)P(q_2|q_1)P(q_3|q_2) ... P(q_t|q_{t-1})
状态转移概率矩阵A = [a_{ij}]_{N \times N}和初始状态概率向量 \pi = (\pi_1, ..., \pi_N):
a_{ij} = P(q_t = S_j|q_{t-1} = S_i), \sum_{j=1}^N a_{ij} = 1, 1 \le i \le N
\pi_i = P(q_1 = S_i), \sum_{i=1}^N \pi_i = 1
观测序列服从观测独立性假设,也就是说每一时刻的观测值o_T只依赖于该时刻的状态值q_T:
P(o_t|q_1, o_1, ..., q_T, o_T) = P(o_t|q_t)
由此引出释放概率矩阵B = [b_j(k)]_{N \times M}:
b_j(k) = P(o_t = v_k|q_t = S_j), \sum_{k=1}^M b_j(k) = 1, q \le j \le N
从上可以看出,HMM有三组参数,即π,A以及B。所以我们可以用λ = (π, A, B)来表示一个HMM。
P(O|Q, \lambda) = b_{q_1}(o_1)b_{q_2}(o_2)...b_{q_T}(o_T)
P(Q|\lambda) = \pi_{q_1}a_{q_1q_2}a_{q_2q_3}...a_{q_{T-1}q_T}
推出
P(O, Q|\lambda) = \pi_{q_1}b_{q_1}(o_1)a_{q_1q_2}b_{q_2}(o_2)a_{q_2q_3}...a_{q_{T-1}q_T}b_{q_T}(o_T) = \pi_{q_1}b_{q_1}(o_1)\prod_{t=2}^Ta_{q_{t-1}q_t}b_{q_t}(o_t)

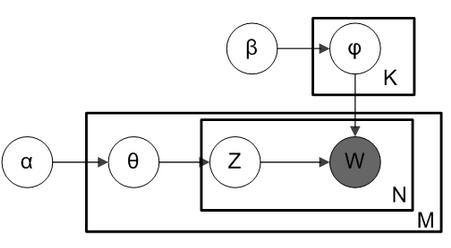
- Latent Dirichlet Allocation(LDA):来自David M. Blei,Andew Y. Ng and Michael I. Jordan 发表于NIPS 2001的文章Latent Dirichlet Allocation。目前在文本挖掘领域包括文本主题识别、文本分类以及文本相似度计算方面都有应用。
LDA是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
它是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出;同时是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可;此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。

- Matrix Decomposition:包括特征分解,Jordan分解,Schur分解,SVD;LU分解,Cholesky分解,QR分解等。矩阵分解(matrix factorization)技术常用于推荐系统等问题中,Probabilistic Matrix Factorization(PMF)便是其中一种重要的技术。
- Conditional Random Field(CRF):应该是机器学习领域比较难的一个算法模型了,难点在于其定义之多(涉及到概率图模型、团、最大团等)以及数学上近乎完美(涉及到概率、期望计算、最优化等),但其在自然语言处理方面应用效果还是比较好的。
设X与Y是随机变量,P(Y|X)是在给定X的条件下Y的条件概率分布。若随机变量Y构成一个由无向图G=(V, E)表示的马尔可夫随机场,即
P(Y_{\nu}|X, Y_{\omega}, \omega \ne \nu) = P(Y_{\nu}|X, Y_{\omega}, \omega \sim \nu)
对任意结点ν成立,则称条件概率分布P(Y|X)为条件随机场。式中ω~ν表示在图G=(V, E)中与结点ν有边连接的所有结点ω,ω≠ν表示结点ν以外的所有结点, Y_{\nu}, Y_u与Y_{\omega} 为结点ν,u与ω对应的随机变量。
李军
04/03/2018 写于上海
