GRAPH ATTENTION NETWORKS(GAT)图注意力网络
Posted on 2019-09-19 22:04 balabalaxiaomoxian 阅读(3370) 评论(0) 编辑 收藏 举报

摘要:
我们提出一个图注意力网络,一个新的用来操作图结构数据的神经网络结构,它利用“蒙面”的自我注意力层来解决基于图卷积以及和它类似结构的短板。通过堆叠一些层,这些层的节点能够参与其邻居节点的特征,我们可以为该节点的不同邻居指定不同的权重,此过程不需要任何计算密集的矩阵操作(例如转置)或者事先预知图的结构。
1.INTRODUCTION
CNN已经成功的营造用在解决图像分类,语义分割,机器学习方面的问题,这些方面的潜在数据表示都是类表格结构
然而,很多有趣的任务涉及的数据结构不能被表示为类表格结构并且分布在一个非常规的空间,像社交网络。这样的数据结构可以被表示为图结构
在文献中有过扩展神经网络来处理任意形状图的几次尝试。早期工作使用递归神经网络用有向无环图来处理图领域的数据表示。Gori和Scarselli等人提出图神经网络(GNN)作为一种递归神经网络(RNN)的泛化,GNN能够直接处理更多种类的图,例如有环图,有向图,无向图。
作者通过与之前一些研究的对比提出:之前在一个特定图结构上的模型不能够直接应用在另外一个不同结构的图上。于是,作者介绍了注意力机制。注意力机制的最大的特点是:它允许不同大小的输入,集中在众多输入中最相关的部分并用此来做决定。当一个注意力机制使用在计算单一序列的节点表示时,它通常指的时自我注意力机制。自我注意力机制被证明在处理机器学习,语句表示学习方面是有效的。
通过对之前研究的了解,作者提出基于注意力机制结构用来给图结构的数据进行节点分类的方法。这个方法使用自我注意力机制通过该节点的邻居节点计算该节点的隐藏表示。这种注意力架构有几种特点:(1)这种操作是有效的,因为它并行计算邻居节点对(2)通过给邻居节点指定任意的权重,来应用在拥有不同度的节点的图上。(3)该模型可以直接应用在推理学习问题上,包括一些任务其模型不得不生成完全不可见的图。作者验证该方法在四个基准线上:Cora,Citeseer,Pubmed citation networks,inductiv protein-protein interaction dataset,并达到了目前最高水平。
2.GAT ARCHITECTURE
2.1GRAPH ATTENTIONAL LAYER
我们以单个图注意力层为例开始,因为单层贯穿于我们实验所用的GAT架构。
我们该层的输入是a set of node features,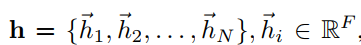 N代表节点数目,F为每个节点的特征数。该层产生a new set of node features
N代表节点数目,F为每个节点的特征数。该层产生a new set of node features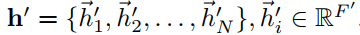 作为输出。
作为输出。
为了去获得足够的把输入的特征转化为更高层次的特征的表现力,至少需要一个可学习的线性转换。为此目的,作为一个初始化步骤,一个共享的参数为一个权重矩阵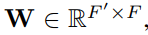
的线性转换应用在每个节点上。然后我们在节点上使用自我注意地机制,一个共享的注意力机制a,以此用来计算注意力因子
上面的公式表示节点 j 的特征对于节点 i 的重要性。在其最通用的表述中,j 将是 i 的第一阶邻居。为了使不同节点的因子容易比较,我们使用柔性最大值函数均一化(1)式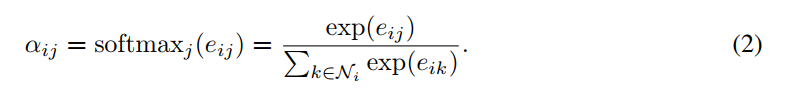
在我们的实验中,注意力机制 a 是一个单层的前馈神经网络,参数为权重向量 a,使用LeakyReLU非线性化(使用负斜率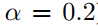 )。完全扩展后,由图1左图描述的注意力机制所计算的因子表述为:
)。完全扩展后,由图1左图描述的注意力机制所计算的因子表述为: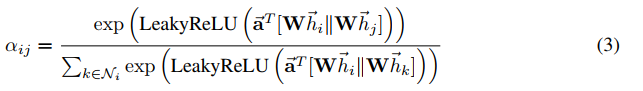 ||意为一些列相关操作
||意为一些列相关操作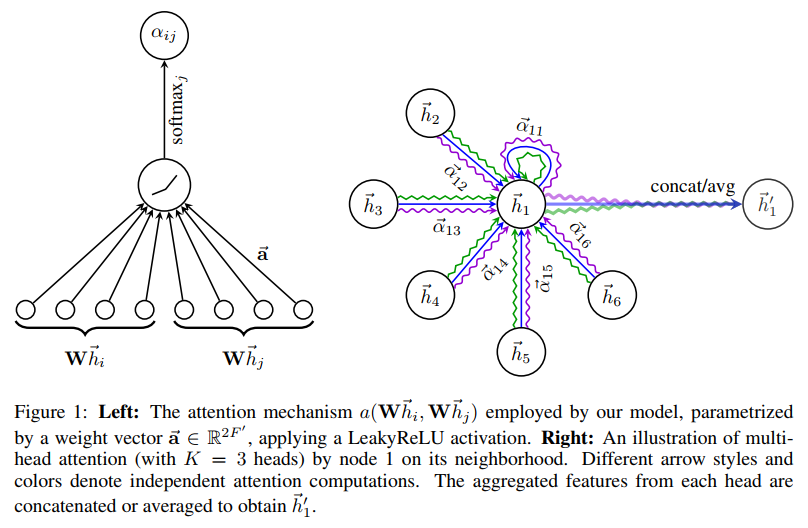
一旦获得均一化的注意力因子,它将用来计算与之相关的特征的线性组合,结果作为每个节点的最终输出。如(4)
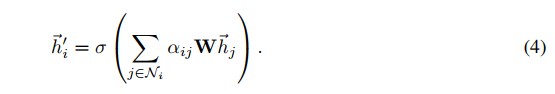
为了稳定自我注意力机制的学习过程,我们已经发现扩展我们的机制,使用多头注意力机制有显著效果,和Vaswani等人2017年的做法相似。特别的,K个独立的注意力机制用来执行公式(4),并且他们的特征是相关的,结果如右图的输出特征表达式: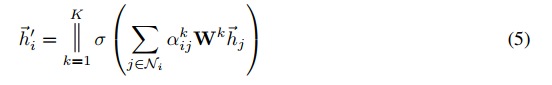
特别的,如果我们使用多头注意力机制在神经网络的最后一层上,相关操作不再是机制的,我们使用平均值,并且延迟使用最后的非线性化(对于分类问题使用一个柔性最大值或者逻辑sigmoid函数)