
如何打造公司级机器学习平台 ——让数据智能不再是公司的噱头

继移动互联网后的又一波红利,是大数据人工智能。如何利用大数据人工智能为整个公司创造真实的利益,而不是对外营销的噱头?
如果说数据智能是一种生产力,那么最重要的两大因素是劳动者和生产资料。
1)数据智能的劳动者是算法工程师,数据分析师,数据科学家,一个公司数据劳动者的数量是衡量这个公司数据智能程度的一个重要指标。
谷歌内部的机器学习忍者计划就是不断提高机器学习工程师的数量,如大神jeff dean所说:”越多的人通过这种方式思考解决问题的方案,我们就会变得越好。”
迪恩估计,谷歌目前约有2.5万名工程师,但只有几千人精通机器学习技术,或许这个比例仅有10%。他希望最终精通机器学习技术的人能接近100%。
个人在百度的时候,也能感觉到公司对所有工程师算法能力培养的重视,百度学院里面有很多机器学习的培训课程。
2)数据智能的生产资料是平台工具以及平台工具所提供的计算资源。
对于数据智能的劳动者,是拎着AK47还是小米步枪上战场,其带来的效率是不一样。现在很火的Tensorflow是Google内部的一套综合性机器学习系统框架,后面才开源
出来,百度内部也有Paddle深度学习平台,其它大公司也都有。工程师有一个易用的机器学习平台,平时遇到问题也会比较容易想到用机器学习的思想和方法来解决问题,
所以机器学习平台对于培训内部工程师的机器学习能力,提升全员AI的能力有着非常重要的作用。
这里我们不过多的提及如何培养公司的工程师,而是主要探讨一个公司级的机器学习平台所要具备的特点。
对于平台工具提供的功能层级来说,从大的方向看可以分为带GUI的可视化编程和代码层级的编程。而代码层级的编程又可以分为三层:基于成熟算法包的编程;对现有算法的改进和性能优化;自研和创新的算法。
对于一个公司而言,大部分的任务其实都是基于现有成熟的算法,少部分任务需要自定义算法,或者在原有的算法上进行创新。而对于其中的机器学习任务,80%的时间在做特征工程,剩下的20%是参数调节和模型评估。
所以带有GUI的可视化编程能够满足大部分常规的机器学习任务,而且可视化编程可以加速AI平民化的进程,结合learning2learn,迁移学习等技术,可以让GUI可视化编程的工作流程更简洁高效。在GUI编程之外再暴露
一定底层的计算架构,让更高层次的工程师可以进行代码层级的工作,对于新研的算法又可以反过来丰富可视化的组件。
在这里我们主要介绍一些个人级和公司级搭建的带GUI的可视化机器学习平台,然后再来分析公司级的机器学习平台要做到哪些要点才能提高公司数据智能的效率。
个人级机器学习平台
这里的个人级机器学习平台主要指个人能够搭建的带GUI的机器学习工具,它们往往是单机的,能训练的样本和特征数有限。
orange
拖拽式的可视化编程的机器学习平台,安装友好,目前已有网页版的界面。使用参考如下界面:
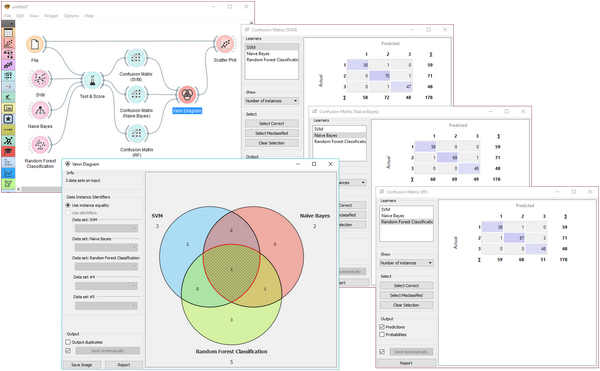


优势
1)组件易于上手,许多操作凭直觉即可甚至不需要文档
2)数据在组件中流动,并带有非常多的可视化,方便实验和探索
3)有扩展功能,可以添加任务需求的组件
4)同时提供各种算法的python 库,用户可以在编码层级使用
缺点
1)支持的数据源不够多(对于个人级的实验是足够的):
2)无server版,多没有人协作功能
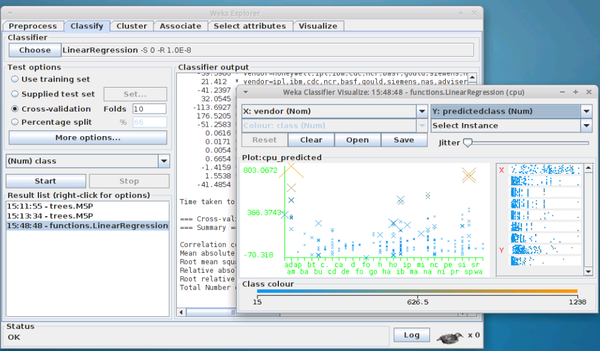
weka
早期所用的开源机器学习工具首选
有explore模式:

Knowledge Flow模式:
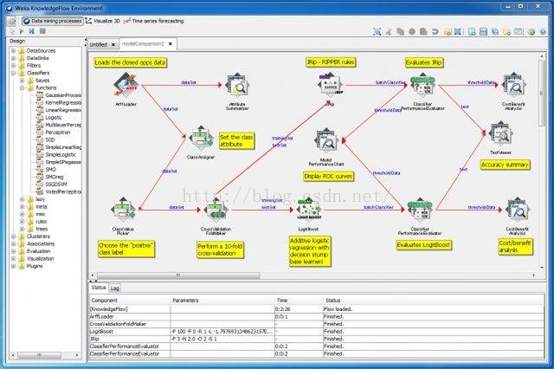

优点
1) 操作简便,运行速度快,尤其适合小规模的机器学习建模
2) 多种编程级别需求支持:命令行,编程api
3) Explore和knowadge flow 模式
缺点
1) 不支持协作
2)单机,不支持分布式
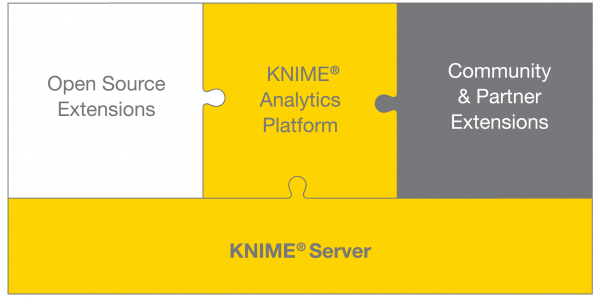
KNIME
KNIME是一个集数据集成、处理、分析和开发于一体的开源数据分析平台
优点
1) 基于Eclipse 平台开发,并且通过其模块化的API 可轻松进行扩展
2) 可集成所有的分析模版到众所周知的WEKA 数据挖掘环境中,并有额外的插件模块允许R-脚本运行,还提供了广大统计例程库接口
3) 提供超过1000 个数据分析例程
4) 机器学习建模工作流程不仅可以通过交互式用户界面运行而且可以执行批处理模式,使数据分析过程可以很容易地定期集成到本地工作运行的管理中去
5) KNIME提供了大量的行业应用模板和定制化的算子,便于特定应用行业的数据分析,譬如生物医药行业
缺点
1) 开源的KNIME分析平台不支持共享协作,需要付费购买KNIME Server 来支持,不过总的来说已经是很强大的个人机器学习平台,并且能够通过付费来到公司级平台能力

其它平台
还有一些其它优秀的机器学习平台,如rapidminer:


甚至一些统计类软件也提供gui的机器学习工具如:
spss

r语言的rattle

这里不一一详说,剩下的大家有兴趣的可以自己体验一番。
为何要公司级的机器学习平台
既然开源的个人机器学习实验平台能满足一般个人的需求,为何还需要公司级的机器学习平台???
- 数据生产闭环
个人平台的数据在机器学习生命周期中的流通如下:


公司级平台:


由此看见公司级的平台可以把数据控制在平台内,形成数据的生产闭环。
在闭环内可以通过日志监控和权限管理,使数据更安全。
同时不用来回手动传输数据,模型,使得整个流程更高效便捷。
- 计算资源共享
- 个人平台
1.每个人使用一套计算资源,资源利用率低
2.个人费时搭建维护
* 公司级平台
1.公司提供平台的计算资源,资源池共享,利用率高
2.公司维护平台功能
- 提高算法生产能力
1.比个人平台更多的计算能力
2.支持更大的样本,更多的特征:公司级提供万级到亿级特征,百万到亿万级样本的能力
3.实验和训练速度更快
- 生产资源的共享
- 个人级平台
1.每个人需要使用特征的时候都要重新去开发
2.特征计算的算子程序,每次都要重写
3.可以通用的模型也要自己去code和调参数
* 公司级平台
1.特征共享,能够查找已有特征
2.算子共享
- 组件/code重用
3.模型共享
- 参数迁移
- 组件/code重用
- 生产资源的管理
公司级机器学习平台对于资源可以更好的管理,提供个人级平台提供不了的如下功能:
1.权限
2.版本
3.查找(方便使用)
4.生命血缘
- AutoML,模型融合等AI平民化工具
个人平台很难提供,因为计算力的问题
公司级平台可以提供这类工具,加速AI平民化,提高公司数据智能效率
- 模型服务的发布、管理、测试、回滚
- 个人级平台
需要自己做线上线下特征的一致性适配
模型的部署服务需要自己写server
未提供模型版本的管理和回滚,需要自己实现
* 公司级平台
容易在work flow中制作特征一致性映射工具
可以在闭环内提供方便的模型的发布、管理、测试、回滚
- 协作
个人级平台基本不能提供协作功能,公司级平台除了前面对特征,算子,模型算法的共享以外,还能提供协作
大模型分割为子模型和特征,可以分工完成
对每个子模型和特征可以备注交流
对模型的权限管理,共享协作锁机制,版本迭代回滚
- 日志、监控、可视化分析
公司级平台能够方便的提供操作日志、任务状态日志、线上模型性能日志以及对应日志的可视化分析
国内几大公司的MLAAS(machine learning as a service) 现状分析
国内除BAT以外,还有第四范式等都在提供可视化的机器学习平台服务,这里我分别来看看他们的平台是否都已经做到了公司级机器学习平台的需求。
百度 BML
百度的BML强调的底层的分布式和并行能力,是其多年机器学习底层累计的输出,至于比spark等分布式计算能强大多少,我们暂时评判不了,其机器学习流程:
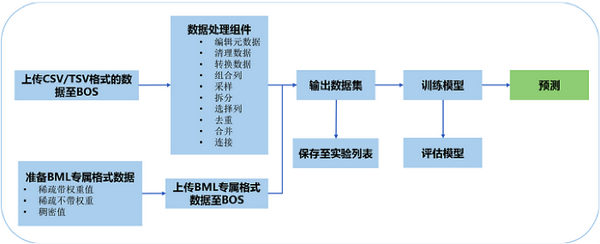

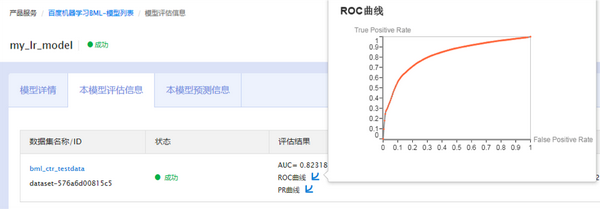

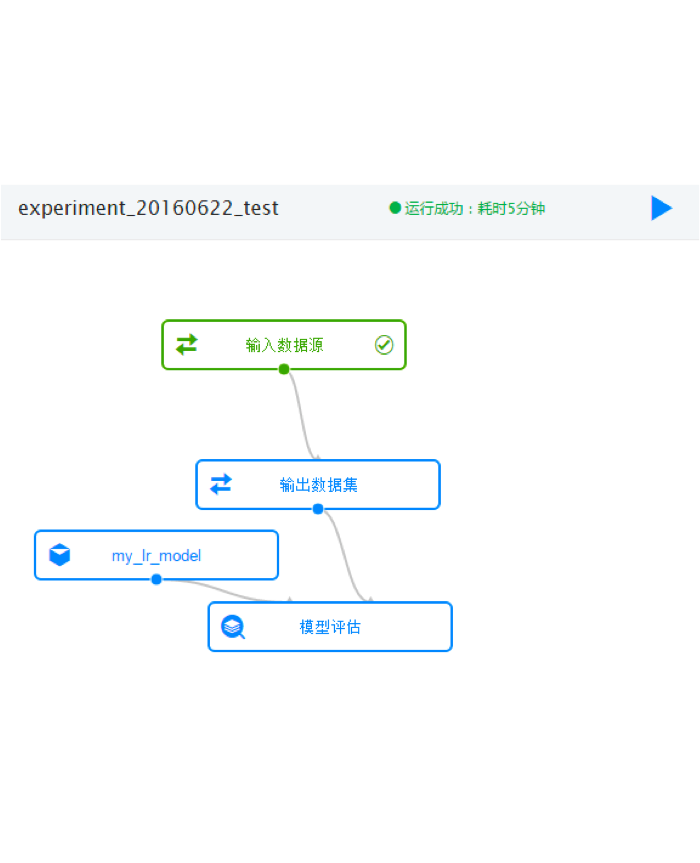

可以看出数据源只支持文件,无特征共享,无共享协作, 无算子共享, 无版本管理,无编程级的需求支持只能是说提供了一个性能较高的个人级实验平台。
阿里 PAI
派平台明显比BML更好,支持可视化操作,深度学习多平台架构,Notebook/代码级,在线/离线部署

阿里云的存储支持可以使企业实现数据闭环,但是目前没看到无特征共享, 无算子共享, 无共享协作等功能,阿里底层的性能也是自己研发和优化的,对大样本和大特征的支持很友好。
腾讯 TML
腾讯的TML起步较晚,具体提供的功能与BML差不多,更偏向于具体领域场景任务的工具提供,在此不多做说明。

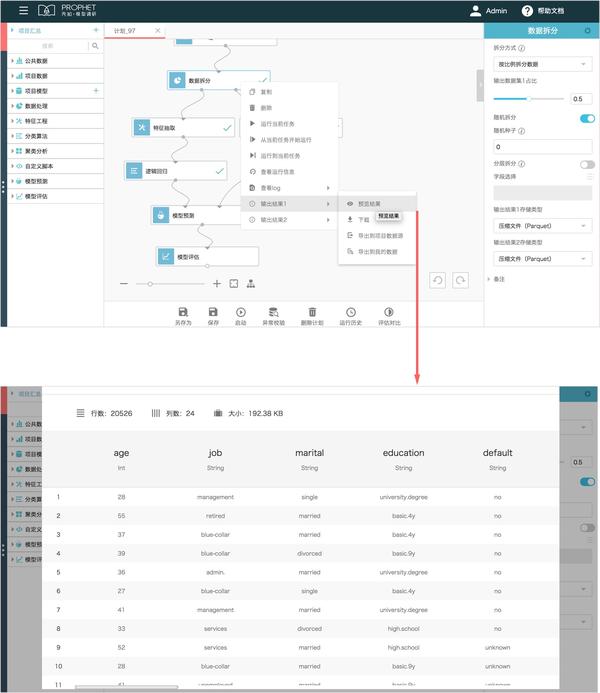
第四范式 先知
先知平台的总体体验不错,支持了一定程度的自定义算子(sparksql,pyspark),提供sdk,支持编程级的需求任务,不过对于数据闭环需要付费搭建属于企业自己的私有云。对于共享协作也未完整支持。

总结
由此可见,即使大公司提供的MLAAS也没达到真正的公司级需求。要达到公司级的机器学习平台需求,产生真正的生产力,一般是需要自己的私有云机器学习平台的。本文提供了建立公司级机器学习平台思路,也欢迎有公司级机器学习平台需求,想要公司快速实现数据智能生产力的朋友一起探讨。
最后求赞,求分享。
