【结合知识的预训练一K-BERT】K-BERT_Enabling Language Representation with Knowledge Graph

引入:预训练的语言模型最近在很多NLP任务中获得了很不错的效果,比如BERT以及基于BERT衍生的一系列算法如RoBERTa,他们都是在大规模的公开数据源使用语言模型进行预训练然后基于下游任务进行微调来将语言转化成向量。然而,由于数据源具有差异性,针对一些特殊领域,直接使用预训练语言模型进行微调效果并不好,如果能将这些领域的知识结合到预训练过程中,将会提升语言模型在该领域下的语言表达能力。该论文尝试将特殊领域的知识图谱与预训练语言模型结合,并解决在结合过程中产生的知识噪音和空间异构等问题,提出了一种新的预训练模型K-BERT。这篇论文被发表在了2020年度的Association for the Advancement of Artificial Intelligence(AAAI)会议上。
K-BERT: Enabling Language Representation with Knowledge Graph论文的
源码被公布在了github上,有兴趣的同学可以进行实验并研究实现细节
- Definition
1.1 HES
1.2 KN - Contribution
- Content
3.1. knowledge layer
3.2. embedding layer
3.3. seeing layer
3.4. mask-transformer - Experiments
4.1. 预训练数据集
4.2. 知识图谱数据集
4.3. 开源任务
4.4. 特殊领域任务
4.5. 消融实验
1. Definition
1.1 HES
全称Heterogeneous Embedding Space,一般地,文本中的词语和知识图谱中的实体,这两者的向量表达是通过不同方式进行获取,并且是孤立的,这就会让他们的向量空间不连续,这种问题叫做HES。
1.2 KN
全称Knowledge Noise,将太多的知识引入到一句话中,将会导致这句话失去他本身的含义,这种问题叫做KN。
2. Contribution
该论文提出K-BERT模型,将知识图谱与预训练语言模型进行结合,并且解决了在结合过程中产生了HES和KN问题,由于微妙的结合方式,使得K-BERT相较于BERT不仅在特殊领域上具有优势,在其他一般领域上也具有优势。
3. Content
总体上来讲,如下图所示,K-BERT一共可以分为4个模块,即knowledge layer, embedding layer, seeing layer 和mask-transformer。输入一个句子,knowledge layer首先将与这个句子相关的知识图谱三元组找出来,并将这些知识融入到句子中,构造一个包含知识的句子树。然后将句子树同时作为embedding layer和seeing layer的输入,分别产生一个向量表达和可视矩阵(visible matrix),其中可视矩阵是用来控制每个字的可视范围,这可以有效解决大量知识引入造成的KN问题,最后使用mask-transformer进行训练。接下来详细介绍这几个部分的内容。
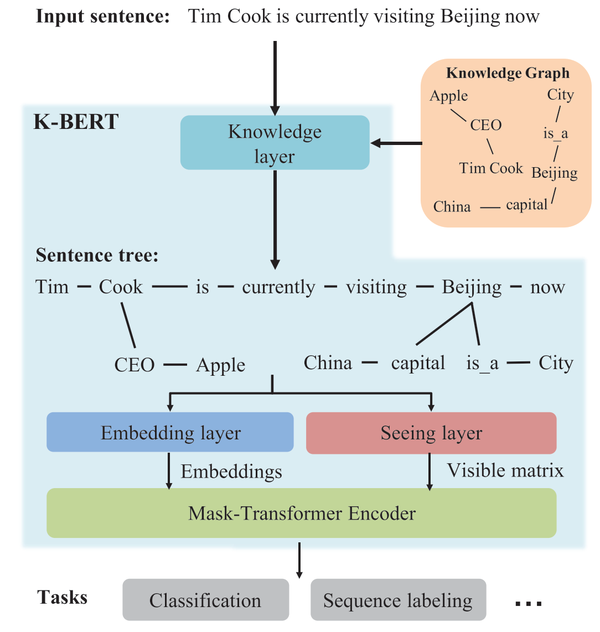
3.1. knowledge layer
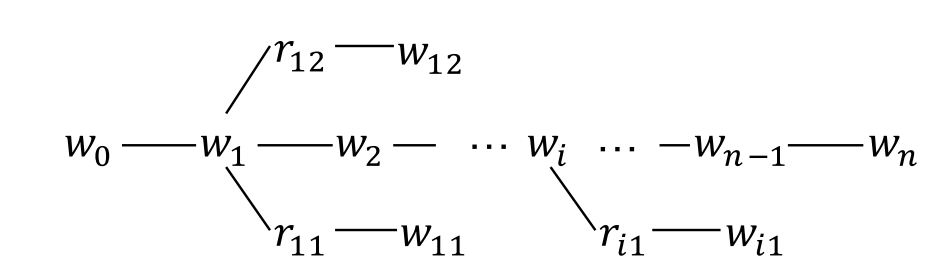
知识层的目的是将输入的句子结合知识图谱转化为知识树。假设模型输入一个句子s=(w_0,w_1,...,w_n)和一个知识图谱,如下图所示,知识层会输出一个句子树s=(w_0,w_1,...,w_i(r_{i0},w_{i0},...,r_{ik},w_{ik}),...,w_n),其中w_i(r_{i0},w_{i0},...,r_{ik},w_{ik})是知识图谱中所有包含实体w_i的三元组。需要注意的是,句子树可以有多个分支,但是深度只能为1,即找到的所有三元组必须包含句子中的实体,不会迭代进行二跳寻找。
3.2. embedding layer
投影层的目的是将句子树进行embedding。和BERT类似,K-BERT也是由三个部分求和得到,如下图所示,这三个部分分别是token embedding,position embedding和segment embedding。但是和BERT不同的是,BERT的输入是一个句子序列,但是K-BERT是一个句子树,因此,K-BERT做了一些调整。
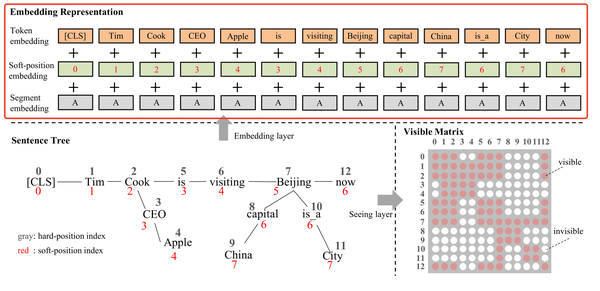
a)针对token embedding,K-BERT和BERT一致,但是由于输入为句子树,K-BERT将句子树做了一些转换,如上图中的句子树,K-BERT将其转化为一个序列:“Tim Cook CEO Apple is visiting Beijing capital China is a City now”。很明显这种转换方式丢失了句子的结构信息,但是这个问题可以通过soft position和visible matrix联合解决。
b) 针对position embedding,如上图所示,一个完整的句子仍然按照他本身的单词位置赋予对应的position,对于分支,按照深度进行累加。因此在计算自注意力时,单词"is"仍然在单词"cook"后面,这样仍然捕获了句子的结构信息,这种position embedding的方式在论文中被叫做soft position embedding。虽然这种方式会导致单词"is"和单词"CEO"的地位等同,但是这个问题可以通过visible matrix解决。
c) 针对segment embedding,K-BERT使用embedding的方式和BERT一致。
3.3. seeing layer
可视层构建了一个可视矩阵。和投影层一样可视层的输入也是句子树,如下图所示,可视层通过构建的可视矩阵限制了模型的可视范围。比如单词'China'只修饰'Beijing',而和单词'Apple'没有任何关系。
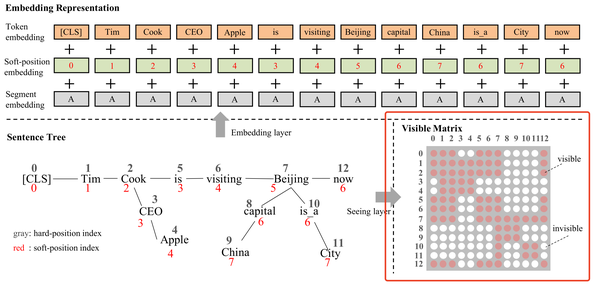
论文通过以下公式构建可视矩阵:
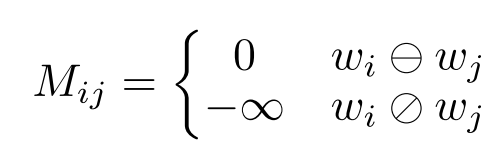
即当单词w_i和单词w_j是在同一个分支时,他们可见(M_{ij} = 0),反之他们不可见(M_{ij} = -\infty)。
3.4. mask-transformer
3.3节构建的可视矩阵在一定程度上反映了句子树的结构信息,和BERT的mask机制不同的是,K-BERT输入的是一个矩阵M,而BERT可以理解为输入的是一个向量。因此K-BERT将MASK机制进行了转化,如下图所示:

其中,h^i是第i层的隐藏层状态,W_q,W_k,W_v是训练参数,M是可视矩阵。可以看到的是,在句子树中,如果单词w_i和单词w_j不可见,M对应的位置为-\infty,那么他们的权重为0,通过这种方式达到了让二者不可见的目的。此外,这种方式还可以将图谱中的知识融入到语言模型中。比如例句中,[CLS]是无法看到[Apple]单词的,然而[CLS]是可以通过单词[Cook]间接看到[Apple]。
4. Experiments
论文在12个中文自然语言处理任务中进行了实验,其中有8个是一般领域的任务,4个是特殊领域的任务。
4.1. 预训练数据集
论文使用了两个中文数据语料进行预训练,分别是WikiZh和WebtextZh。其中WikiZh是中文的维基百科,他包含了100万个中文字词,1200万个句子约1.2G。另外,这个语料也在用来训练中文的BERT模型。WebtextZh是一个大规模,高质量的中文问答语料,包含410万个中文字词约3.7G。此外,每一个字词在WebtextZh中均属于一个主题,该预料包含有28000个主题。
4.2. 知识图谱数据集
论文使用了三个中文知识图谱CN-DBpedia,HowNet和MedicalKG。其中CN-DBpedia是由复旦大学构建的大规模的开源的百科知识图谱。论文去掉了长度小于2以及包含特殊字符的实体,最后使用的数据集包含了约517万个三元组。HowNet是一个大规模的语言知识图谱,主要是一些中文词语的概念,和CN-DBpedia的删除逻辑一致,最后使用的数据集包含有52576个三元组。MedicalKG是论文自己构建的医药知识图谱,其中主要包括(症状、疾病、部位和治疗)(symptoms, diseases, parts, and treatments)四种类型,该知识图谱一共有13864个三元组。
4.3. 开源任务
论文首先在8个开源任务上对K-BERT和BERT进行了比较,其中Book review, Chnsenticorp, Shopping和Weibo是单句子分类任务,XNLI,LCQMC是双句子分类任务,NLPCC-DBQA是机器问答任务,MSRA-NER是命名实体识别任务。实验将数据集分成了train,dev和test三个部分,基于train部分进行微调,然后在dev和test部分进行了验证实验。下面表格可以看出实验结果。


从实验结果中可以得出三个结论:
a.知识图谱的引入在情感分析任务中没有显著的提升,因为情感分析任务可以从带有情感的一些字词直接完成。
b.在语义相似性任务中,语言知识图谱(HowNet)的引入比维基百科知识图谱的引入更有效。
c.在自动问答任务和命名实体识别任务中,维基百科知识图谱的引入比语言知识图的引入更合适。
因此,根据不同的下游任务选择合适的知识图谱很重要。
4.4. 特殊领域任务
K-BERT的诞生主要是用来解决特殊领域场景下的词向量表达问题的,从实验结果也可以看出K-BERT较BERT在这些特殊领域下的优势。论文基于百度知道爬取了金融领域和法律领域的问题和回答,构建了这两个领域的问答任务,另外,论文还在金融领域和医疗领域下的命名实体识别任务进行了对比。实验结果如下表所示。

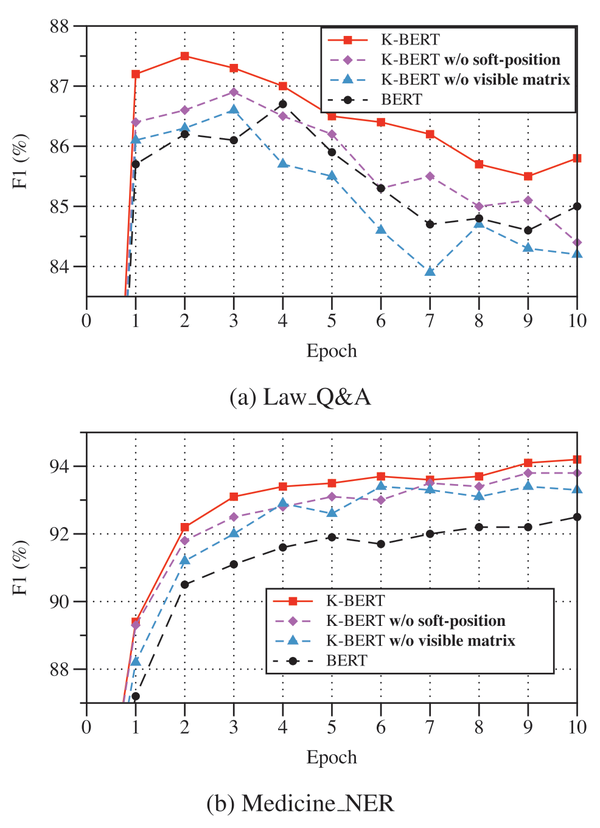
4.5. 消融实验
论文基于法律领域的问答任务和医疗领域的命名实体识别任务做了消融实验,从如下试验结果可以证明论文提出的soft-position和visible matrix的有效性,
- [1] Liu W, Zhou P, Zhao Z, et al. K-bert: Enabling language representation with knowledge graph[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(03): 2901-2908.
- [3] Y. Lin, Z. Liu, H. Luan, M. Sun, S. Rao, and S. Liu. Modeling relation paths for representation learning of knowledge bases. Technical report, arXiv:1506.00379, 2015.
- [4] L. Guo, Z. Sun, and W. Hu. Learning to exploit long-term relational dependencies in knowl- edge graphs. In ICML, 2019.
- [5] T. Elsken, Jan H. Metzen, and F. Hutter. Neural architecture search: A survey. JMLR, 20(55):1– 21, 2019.