
最近论文的单目视觉3-D目标检测方法(附)


补充几个CVPR‘2021的工作。。。
再提醒一下,之前的工作讨论见:
A1 "Ground-aware Monocular 3D Object Detection for Autonomous Driving",arXiv 2102.00690,2,2021
该文之前曾单独介绍,略过。
A2 “MonoRUn: Monocular 3D Object Detection by Reconstruction and Uncertainty Propagation”,arXiv 2103.12605,3,2021
该文在以前介绍过,因为是自监督方法的原因:
A3 “M3DSSD: Monocular 3D Single Stage Object Detector“, arXiv 2103.13164,3,2021


本文的方法Monocular 3D Single Stage object Detector (M3DSSD),带feature alignment 和asymmetric non-local attention。采用一种两步feature alignment方法:1)shape alignment 确保特征图receptive field 聚焦 事先定义的高可信度锚框;2)center alignment针对2D/3D中心。另外,提出asymmetric non-local attention 模块,带 multiscale sampling 去提取depth-wise features。
代码:https://github.com/mumianyuxin/M3DSSD
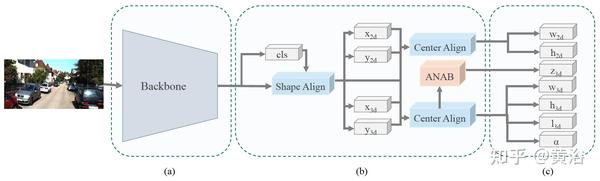
如图是M3DSSD结构:(a) 主干 DLA-102;(b) two-step feature alignment, classification head, 2D/3D center regression heads, 以及深度预测的ANAB(Asymmetric Non-local Attention Block); (c) 其他 regression heads。

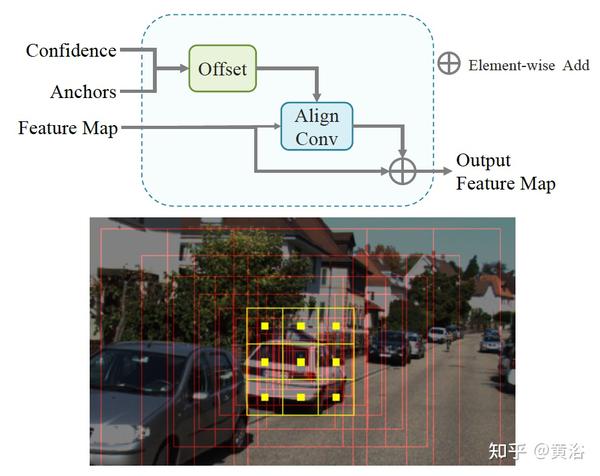
下图是shape alignment:

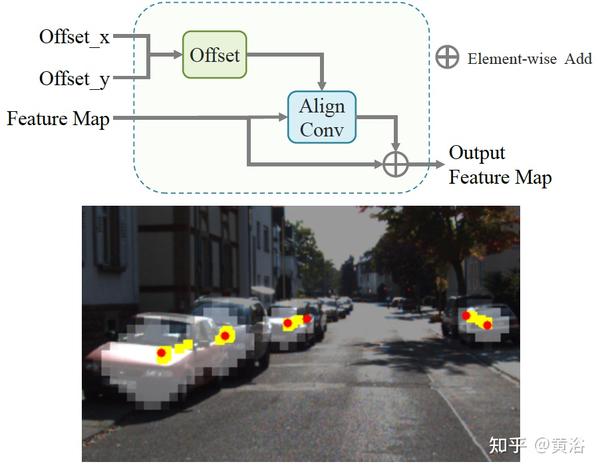
下图是center alignment:

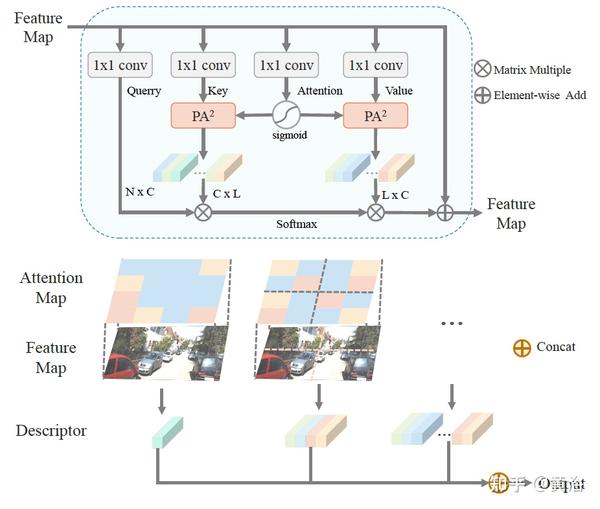
下图是ANAB模块:键和查询分支共享相同的attention图,迫使key和value集中在同一位置。 其中下部分是Pyramid Average Pooling with Attention (PA2)各种分辨率生成不同级的 descriptors。

目标中心图像投影:


从检测器输出计算目标边框如下:


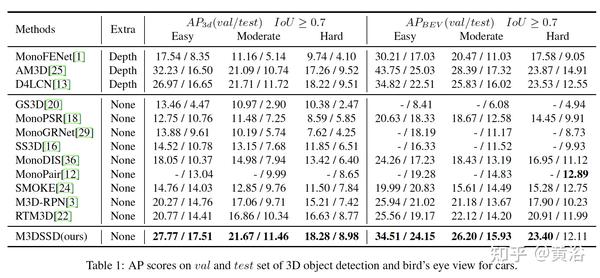
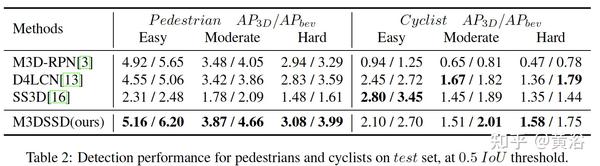
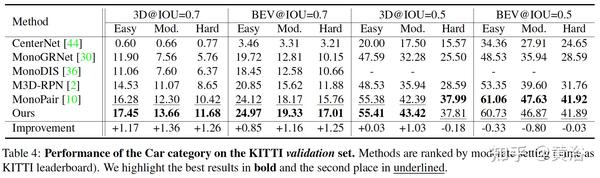
一些实验结果比较:


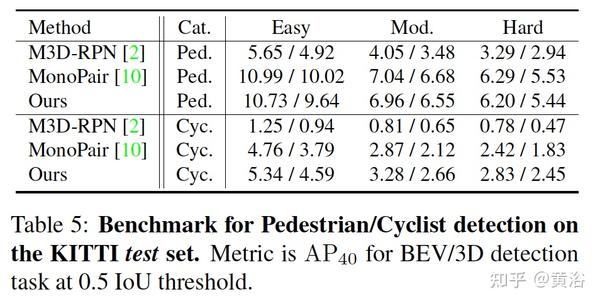
A4 “Delving into Localization Errors for Monocular 3D Object Detection“,arXiv 2103.16237,3,2021

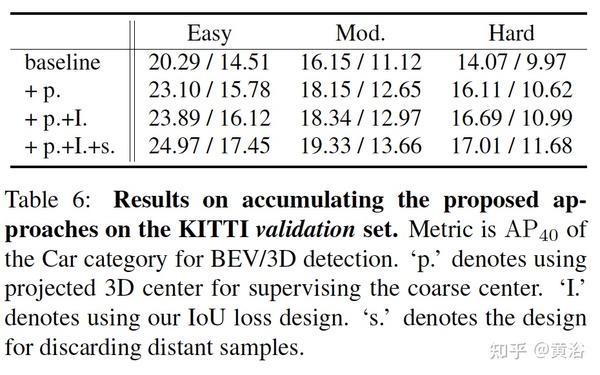
本文方法强调子任务目标定位误差对检测的影响,调查后面的原因和带来的问题,并提出三个改进:1)2D边框中心和目标中心的偏差是一个主要原因;2)远距离目标定位精度差,训练集可去除这些数据;3)提出一个 针对目标大小的3D IoU oriented loss,动态调整样本级的权重,这个不受定位误差的影响。
将上传代码:https://github.com/xinzhuma/monodle
文中的基准检测模型是Centernet,主干DLA-34,然后作者用真值分别取代子任务的预测输出,即中心投影、深度、3D位置、朝向和大小等。2D检测,输出分类的heatmap和粗估计的目标中心,还有与真实2D边框中心的偏差,边框大小等。3D检测,预测3D中心投影和2D粗估计中心的偏差,其他包括3D边框大小和朝向等。
损失函数共包括7项:1个前景/背景分类、2个2D检测(中心和大小)、4个3D检测(中心、深度、大小和朝向)。朝向角的loss也采用multi-bin,3D大小的loss采用一个新定义函数。
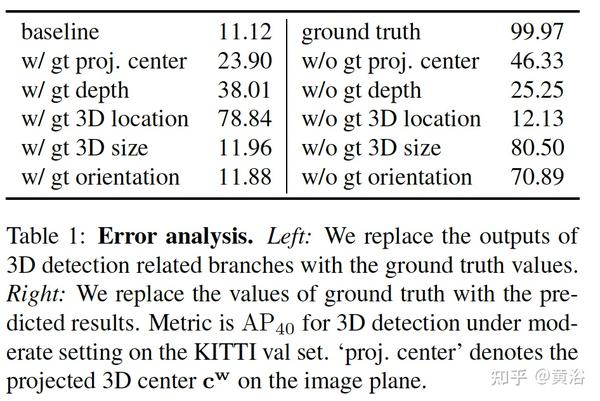
误差分析见下表:看出来各个中间预测值对最后检测结果的影响。

下表是一个预测中心移动造成定位误差的分析:
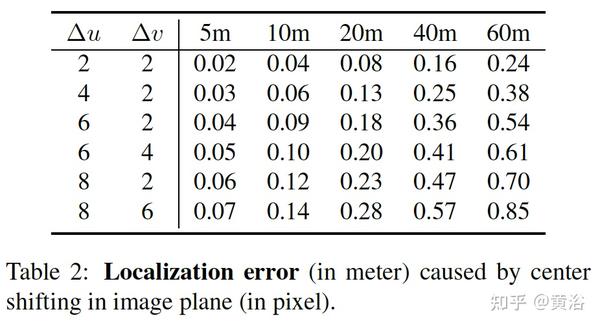

对目标中心估计,提出:1)投影的3D中心作为估计2D粗略中心分支的真值;2)迫使模型同时从2D检测中学习特征(不同于前面的SMOKE方法)。
针对如何为样本生成目标级训练权重,提出两种方案:
- hard coding:去除远距离(60米)样本数据。
- soft coding:权重计算基于S-形函数。
KITTI dataset的平均车辆大小是 [1:53m; 1:63m; 3:53m]。本文提出3D大小估计的IoU oriented optimization,其中梯度计算的比例关系
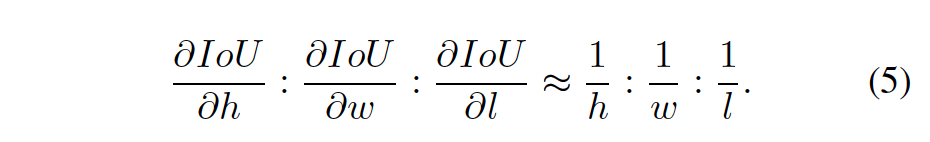

为此调整权重计算,得到新loss函数定义
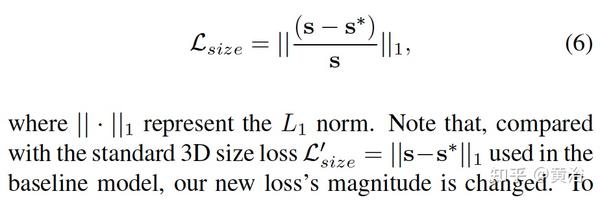

两个新旧loss之比成为补偿权重,所以新loss函数类似于标准loss的重新分配。
实验结果比较如下:
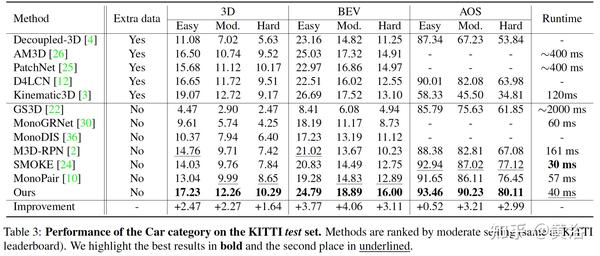




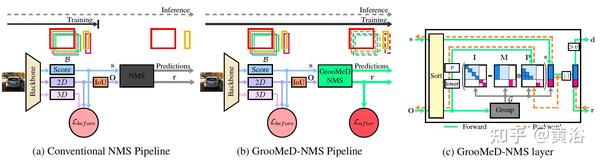
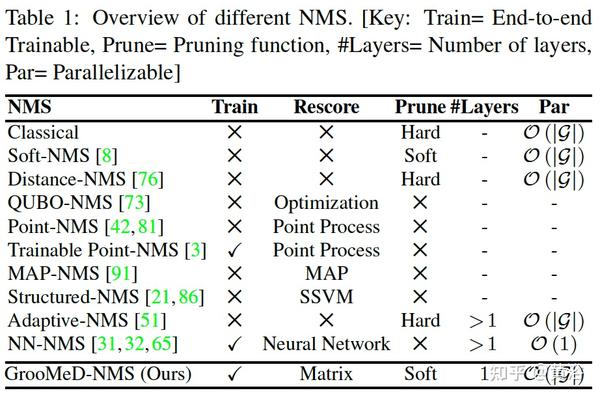
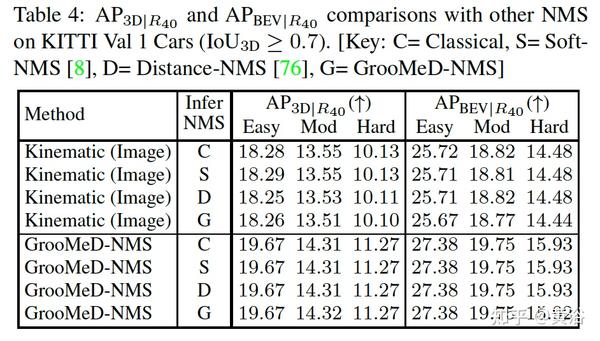
A5 “GrooMeD-NMS: Grouped Mathematically Differentiable NMS for Monocular 3D Object Detection“,arXiv 2103.17202,3, 2021


提出一个在训练中特别考虑NMS的方法GrooMeD(Grouped Mathematically Differentiable)- NMS。NMS被公式化为矩阵操作,以无监督形式group-and-mask这些边框得到一个NMS的闭式解表达。
如图是GrooMeD概览:(a)传统目标检测在训练和推理之间存在不匹配,仅在推理中使用NMS。 (b)为解决这个问题,提出了一个GrooMeD-NMS层,在应用NMS时对网络进行端到端训练。 s和r分别表示NMS之前和之后方框B的得分。 O表示包含B IoU2D重叠的矩阵。L-before表示NMS之前损失,而L-after表示NMS之后损失。 (c)当NMS之后未选择与目标对应的最佳定位框,GrooMeD-NMS层以可微分的方式计算得分r,给出L-after的梯度。

传统NMS算法:


采用argmax(第6行),无法并行也不可微分。而GrooMeD-NMS算法:
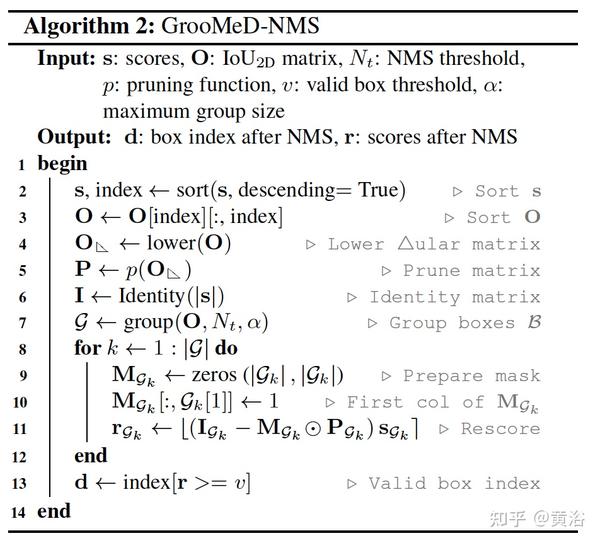

首先取代argmax,换成sorting(hard和soft),文章采用“Softsort: A continuous relaxation for the argsort operator.Softsort: A continuous relaxation for the argsort operator“的算法。
NMS的rescoring过程,写成矩阵形式:
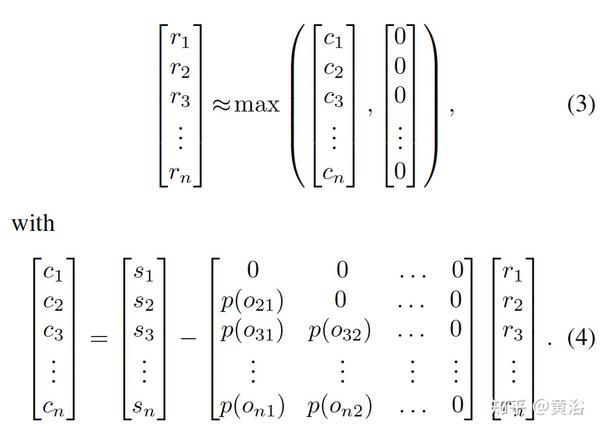

简记为
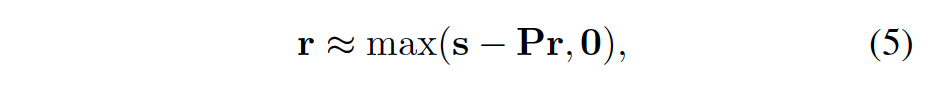

P称为Prune Matrix,p是pruning function,基于IoU2D overlaps计算如何给边框打分。为避免迭代,最后解改为
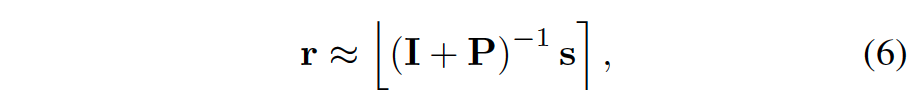

其中I是单位矩阵。
基于IoU2D overlaps对图像的边框进行分组,这样得到新公式:k是分组#
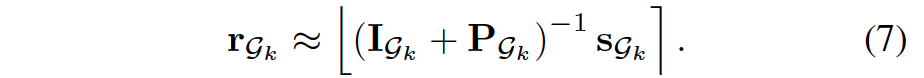

具体算法如下:


选择高分的边框类似masking操作,这样可简化上面公式的求逆操作,最后公式变为:
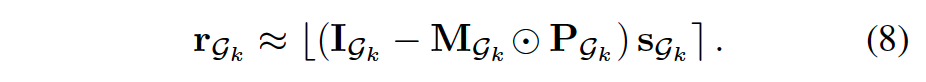

其中M为masking二值矩阵。
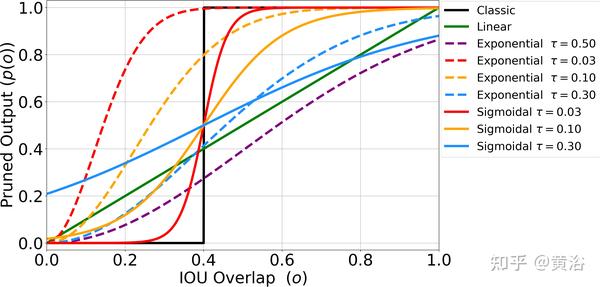
对pruning function的选择,如图所示:有多个选择线性、指数型和S-形。

和传统NMS的方法比较如下:

采用的检测方法基准是M3D-RPN(ICCV‘19论文“M3D-RPN: Monocular 3D region proposal network for object detection“),采用binning 和 self-balancing confidence(ECCV‘20论文“Kinematic 3D object detection in monocular video“)作为边框打分。选择最佳边框的目标设置是


其中gIoU3D(Generalized intersection over union-3D)计算
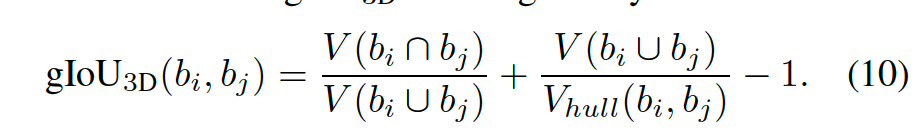

需要计算3D边框的V和Vhull。V是gIoU3D,Vhull 是在BEV的gIoU2D。
修正的AP-loss,即Image-wise AP-Loss,可作为L-after计算:
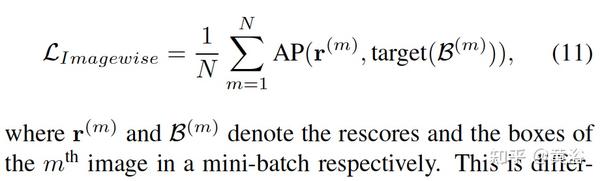

总loss函数包括L-before和L-after两个。
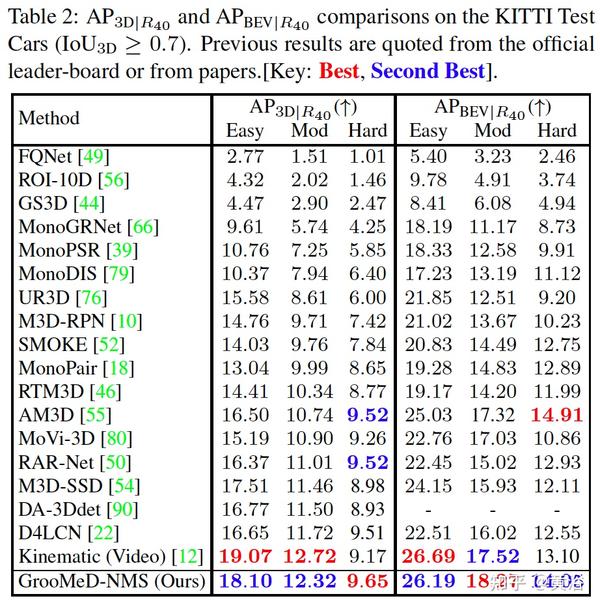
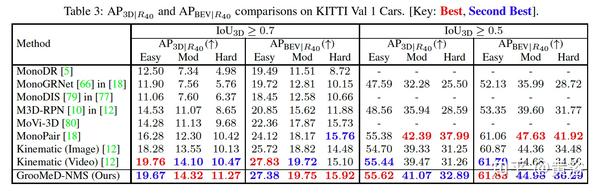
实验结果比较如下:



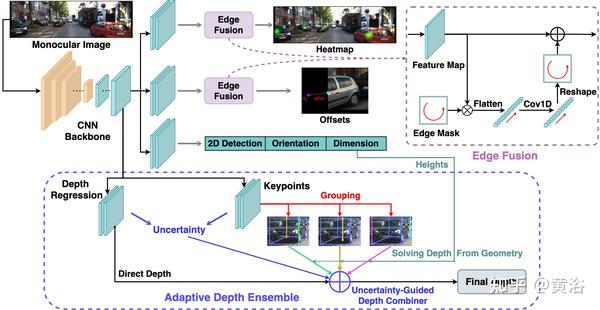
A6 “Objects are Different: Flexible Monocular 3D Object Detection”,arXiv 2104.02323,4,2021


该方法将truncated objects解耦,并采用多种方法结合来估计目标深度。具体说,就是为预测长尾分布的truncated objects,对特征图边缘做解耦,这样不影响普通目标的优化。文章将目标深度估计公式化为直接回归目标深度的不确定性引导集成(uncertainty-guided ensemble)形式,并从keypoints的不同分组估计求解。
代码将会上线:https://github.com/zhangyp15/MonoFlex
如图模型框架示意图:首先,CNN主干从单目图像提取特征图作为多个预测头的输入。 图像级定位涉及热图和偏移,其中边缘融合(edge fusion)模块将特征学习与截断目标(truncated objects)预测解耦。 自适应深度集成(adaptive depth ensemble)采用四种方法进行深度估计,并同时预测其不确定性,从而形成不确定性加权的预测。

同样,目标3D位置来自于深度估计z和3D中心的图像投影(u,v):
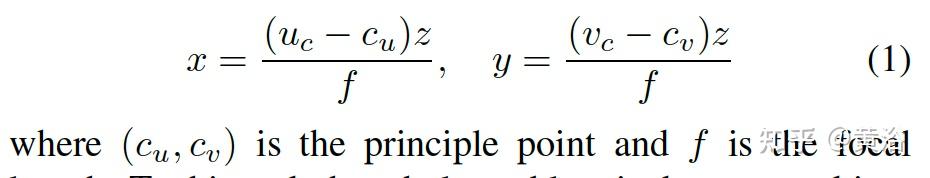

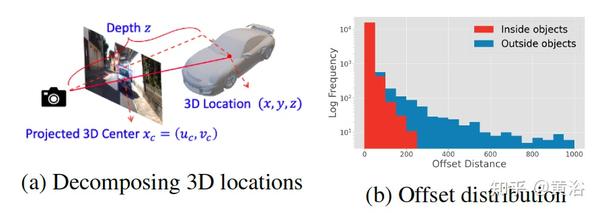
文章把目标分为两个组,取决于其3D中心投影在图像内还是图像外。如图展示的是目标3D位置分解示意图及其偏差分布:(a)3D位置将转换为投影中心和目标深度; (b)从2D中心到投影3D中心的偏移量c分布; 图像内和图像外目标表现出完全不同的分布。

为此作者提议将图像内和图像外目标的表示和偏差学习分解开。
图像内目标的偏差容易,比以前统一表示方法的偏差,delta=xc-xb,要小好多,即(S是下采样比)
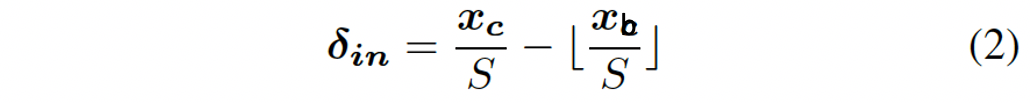

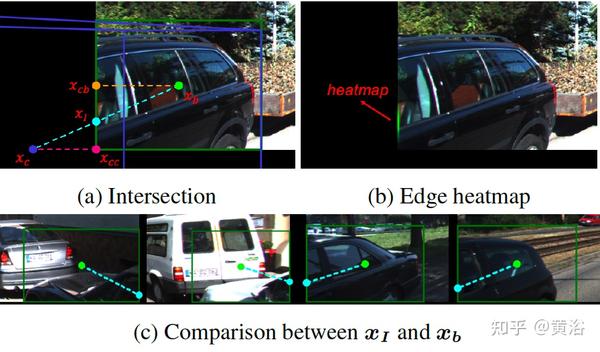
对于图像外目标,首先是确定方法,即如下图所示的图像边界和xb-xc连线的相交点xI,其预测来自边缘热图。比较xI和xb,xI分离了热图边缘地区,专注于图像外目标,提供了一个强边界鲜艳知识,可简化定位。对于高截断目标,显然xI比xb更合适做表示。

对图像外目标,这个偏差回归变成
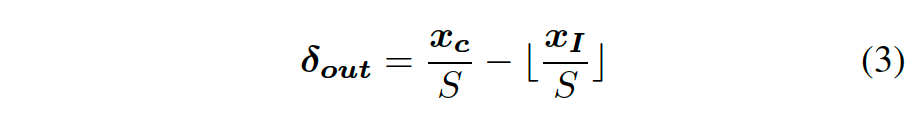

提出edge fusion进一步分解特征学习和图像外目标的预测。图像内和图像外目标的偏差尺度差别可以通过edge fusion模块解决。
偏差损失函数如下:


视觉特性回归包括2D框、大小、朝向、目标关键点等。
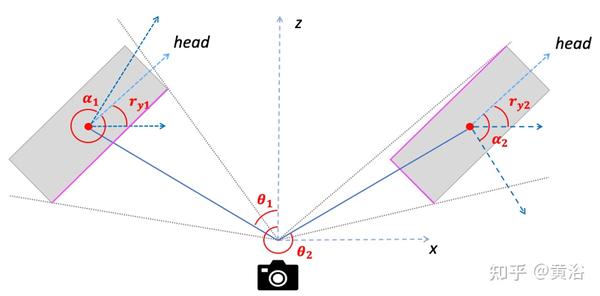
如图是朝向角和观测角的关系:

如图是关键点的示意图:3D框的8个顶点加顶中心和底中心。
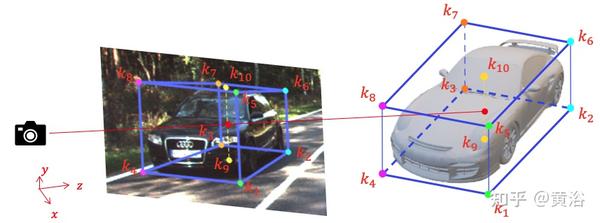

深度估计来自关键点估计的集成。从高度估计深度不仅和朝向估计无关,而且也少受大小估计误差的影响。每个目标边框垂直支撑线的深度可从其像素高度和目标高度计算:
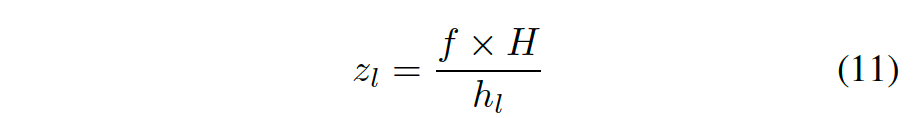

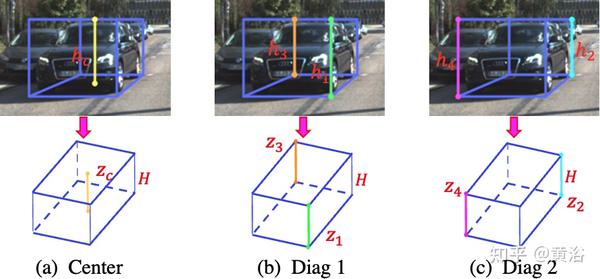
如图所示:将十个关键点分为三组,即中心垂直线深度和两个对角垂直边界线(h1-h3和h2-h4)平均,每组可以独立产生中心深度估计。

深度回归loss:
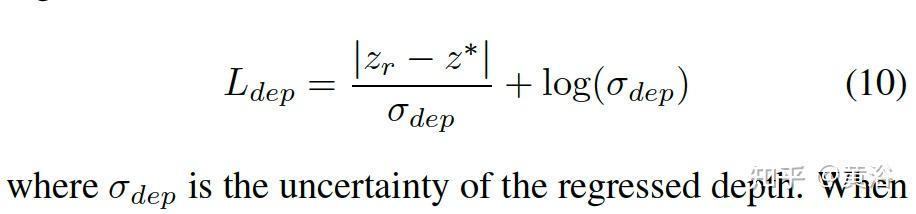

从关键点的目标深度回归loss:
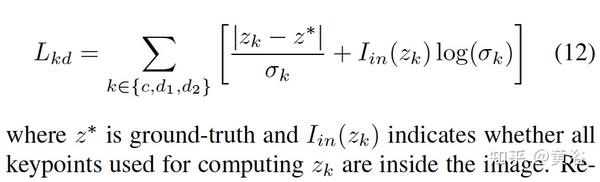

最后深度预测的Uncertainty Guided Ensemble:
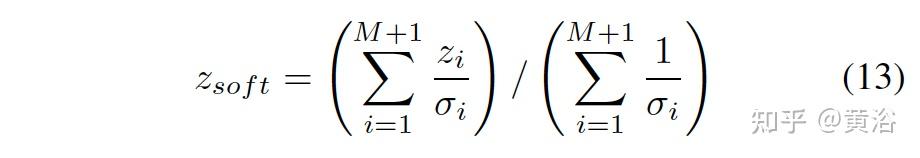

附加的边框顶点估计loss:
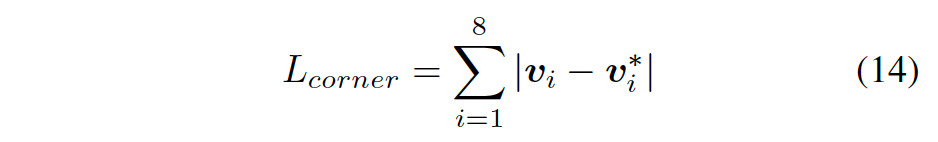

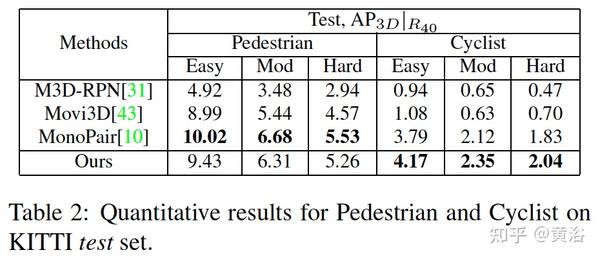
实验结果比较如下:


定性结果:注意其中截断目标(红圈)




