7 Papers | KDD2019最佳论文;AutoML SOTA 综述

本周的看点是 KDD 2019 大会,分别有两篇研究赛道和应用赛道最佳论文被选入。本周入选的其他论文都有架构或研究方法上新颖的点,如 CMU、加州大学圣迭戈分校等的基于语义的相似性的机器翻译论文、乔治亚理工联合 Facebook 和俄勒冈州立大学提出的多模态 BERT 模型等、提出反向传播替代方法 HSIC 瓶颈的论文等。
机器之心整理,参与:一鸣。
目录:
- Network Density of States
- Actions Speak Louder than Goals: Valuing Player Actions in Soccer
- Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
- The HSIC Bottleneck: Deep Learning without Back-Propagation
- AutoML: A Survey of the State-of-the-Art
- ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
- Trick Me If You Can: Human-in-the-Loop Generation of Adversarial Examples for Question Answering
1. 标题:Network Density of States
- 作者:Kun Dong、Austin R. Benson、David Bindel
- 论文链接:https://arxiv.org/pdf/1905.09758.pdf
摘要:在本文中,研究者深入探索了真实世界图谱谱密度的核心。他们借用了凝聚态物理学中开发的工具,并添加了新的适应性来处理常见图形的谱特征。他们计算了单个计算节点上超过 10 亿个边的图的谱密度,证明所得到的方法非常高效。除了提供视觉上引人注目的图形指纹之外,研究者还展示了谱密度的估计如何简化许多常见的中心度量的计算,并使用谱密度估计关于图结构的有意义信息,这些信息不能仅从极值特征对推断出来。
推荐:这篇是 KDD 2019 的研究赛道最佳论文,作者来自 CMU 和康奈尔大学。
2. 标题:Actions Speak Louder than Goals: Valuing Player Actions in Soccer
- 作者:Tom Decroos、Lotte Bransen、Jan Van Haaren、Jesse Davi
- 论文链接:https://arxiv.org/pdf/1802.07127.pdf
摘要:评估足球运动员比赛中个人行动所造成的影响是评估他们的重要指标。然而,大多数传统指标在解决此类任务时效果都不尽如人意,因为它们只关注整场比赛中仅有的几次特殊动作,比如射门和进球——而忽视了行动的背景。研究人员提出的方法包括:一种用于描述球场上各个球员动作的新语言;基于它对比赛结果的影响来评估任何类型球员动作的框架,同时考虑了动作发生的背景。
推荐:解决「魔球」问题的一篇论文,获得了 KDD 2019 应用赛道最佳论文。
3. 标题:Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
- 作者:John Wieting、Taylor Berg-Kirkpatrick、Kevin Gimpel、Graham Neubig
- 论文链接:https://www.aclweb.org/anthology/P19-1427
摘要:在本文中,研究者提出以一种可替代的奖励函数(reward function)来优化神经机器翻译(NMT)系统,这种奖励函数基于语义相似性的研究。研究者对四种翻译成英文的语言展开评估,结果发现:利用他们提出的*度量*进行训练,可以产生较 BLEU、语义相似性和人工测评等评估标准更好的翻译效果,并且优化过程的收敛速度更快。分析认为,取得更好翻译效果的原因在于研究者提出的度量更有利于优化,同时分配部分分数(partial credit),提供较 BLEU.1 更强的分数多样性。


推荐:一篇较少见的基于语义相似性的机器翻译论文。推荐想要继续研究这一领域的读者看看最新的研究进展。
4. 标题:The HSIC Bottleneck: Deep Learning without Back-Propagation
- 作者:Wan-Duo Kurt Ma、J.P. Lewis、W. Bastiaan Kleijn
- 论文链接:https://arxiv.org/pdf/1908.01580v1.pdf
摘要:在本文中,研究者介绍了用于训练深度神经网络的希尔伯特·施密特独立准则(Hilbert-Schmidt independence criterion,HSIC)瓶颈。HSIC 瓶颈是传统反向传播的一种替代方法,具有很多明显的优势。该方法有利于并行处理,并且所需要的操作流程大幅度减少。此外,该方法还不会遭遇梯度爆炸或梯度消失的情况。从生物学的角度来看,由于不需要对称反馈,所以该方法较反向传播更为合理。研究发现,即使当不鼓励系统输出的结果类似于分类标签时,HSIC 瓶颈在 MNIST/FashionMNIST/CIFAR10 分类中的表现与具有交叉熵目标的反向传播相当。增加一个利用 SGD(无反向传播)进行训练的单一层能够实现 SOTA 性能。
推荐:虽然反向传播已经是神经网络的标配,但为何不能再提高下运算效率,解决梯度下降中的问题呢?文章提出的新型梯度下降方法,值得读者了解最新的神经网络架构创新动向。
5. 标题:AutoML: A Survey of the State-of-the-Art
- 作者:Xin He、Kaiyong Zhao、Xiaowen Chu
- 论文链接:https://arxiv.org/pdf/1908.00709v1
摘要:在特定领域构建高质量的深度学习系统不仅耗时,而且需要大量的资源和人类的专业知识。为了缓解这个问题,许多研究正转向自动机器学习。本文是一个全面的 AutoML 论文综述文章,介绍了最新的 SOTA 成果。首先,文章根据机器学习构建管道的流程,介绍了相应的自动机器学习技术。然后总结了现有的神经架构搜索(NAS)研究。论文作者同时对比了 NAS 算法生成的模型和人工构建的模型。最后,论文作者介绍了几个未来研究中的开放问题。


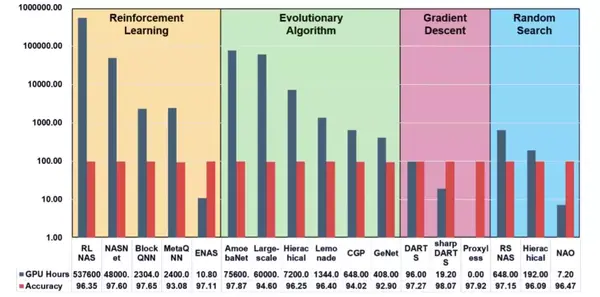

推荐:自动学习难入门?SOTA 模型学起来。
6. 标题:ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
- 作者:Jiasen Lu、Dhruv Batra、Devi Parikh、Stefan Lee
- 论文链接:https://arxiv.org/pdf/1908.02265.pdf
摘要:研究人员提出了一种名为 ViLBERT(图文 BERT)模型。这是一个可以学习任务未知的、图像内容和自然语言联合表征的模型。研究人员将流行的 BERT 架构扩展成一个 multi-modal two-stream 模型上。在这个模型上,模型用两个分开的流处理图像和文本输入,但他们彼此用联合注意力层交互。研究人员在两个代理任务上,使用 Conceptual Captions 数据集(数据集很大,而且是自动收集的数据)预训练这个模型,然后将模型秦阿姨到多个建立好的图像-文本任务上。这些任务包括图像问答、图像常识推理、引述表达、指称成分,以及基于捕捉的图像提取。这些只需要在基本架构上进行微小的补充。研究人员观察到,相比现有的针对任务的特定模型,新模型在这些任务上都有了相助的性能提升——在每个任务上都取得了 SOTA。


ViLBERT 模型的架构。绿色和紫色的两条 stream 分别输入图像和文本数据,并使用联合注意力层进行交互。这一结构可以学习图像和文本的联合表征。
推荐:使用 BERT 进行多模态的数据预训练,这篇论文提供了一个新思路。论文作者来自乔治亚理工、Facebook 和俄勒冈州立大学。
7. 标题:Trick Me If You Can: Human-in-the-Loop Generation of Adversarial Examples for Question Answering
- 作者:Eric Wallace、Pedro Rodriguez、Shi Feng、Ikuya Yamada、Jordan Boyd-Graber
- 论文链接:https://doi.org/10.1162/tacl_a_00279
- 项目链接:https://github.com/Eric-Wallace/trickme-interface/
摘要:对抗评估(adversarial evaluation)强调测试模型对自然语言的理解能力。由于过去的方法只能发现表层的规律,获得的对抗样本只有有限的复杂性和多样性。本文中,研究人员提出了一种人类参与的对抗样本生成循环流程。在流程中,人类作者可以被引导用于中断模型。研究人员给作者们提供了交互式界面,用于解释模型的预测结果。研究人员在 Quizbowl 这一机器问答任务上使用提出的生成框架,由热衷于 trivia 游戏的人制作对抗问题。而最终生成的文本通过人机匹配进行验证:尽管生成的问题对人类很普通,但可能会全面地难倒神经模型或信息抽取模型。这些对抗样本涵盖了多种多样的特征,从多跳推理(multi-hop reasoning)到实体类型干扰项,暴露出了鲁棒的机器问答研究中的许多开放挑战。


推荐:机器问答任务中同样需要各种各样的对抗样本来提升模型鲁棒性。马里兰大学的这一研究可以帮助读者朋友了解机器问答模型中的鲁棒性问题。而引入人类因素的对抗样本生成同样值得借鉴。


