
首战AutoDL系列比赛2'nd经验分享

之前听说过不少机器学习的比赛,kaggle天池什么的,这还是自己第一回打比赛(导师不说都不知道有这回事hhhh),很幸运捡了个第二(盲测第二,feedback是第一),拿了1500刀奖金和pami邀稿
我参加的这个是谷歌,第四范式等举办的AutoDL 2019系列比赛中的AutoCV2,属于ECML PKDD会议上的一个比赛,AutoDL 2019这个系列比赛有好几场,IJCNN的AutoCV,ECML PKDD的AutoCV2,WAIC的AutoNLP/AutoSeries,以及最后NeurIPS上的AutoDL。因为之前kdd有个automl,所以现在又搞出来这么个autodl比赛。
AutoCV是自动图像分类,AutoCV2是图像/视频,AutoNLP/AutoSeries是序列数据分类,AutoDL是啥都有。。。数据都是未知的,需要算法要能hold得住各种情况各种蛋疼的数据。。。
比赛官网在这https://autodl.chalearn.org/,后面还有个AutoDL比赛没开始,大家感兴趣的可以尝试下
比赛介绍
AutoCV2比赛的任务是视频/图像的多分类,参赛选手仅需要提交代码,代码会在后台的评测系统上自动进行训练,训练数据集对选手完全未知,需要选手的算法能够完全适应不同的数据集,并且在最短的时间内取得尽可能高的测试精度。
比赛共分为两个阶段,第一个阶段是feedback,参赛选手的代码在后台运行结束后会给出相应的学习曲线的反馈,用于用户调试自己的算法,第二个阶段是blind test,将选手最后提交的代码在另外5个完全未知的数据集进行测试,并且给出最终的结果。
比赛的任务为视频/图像的多分类,并要求每个数据集上的运行时间不超过20分钟。评测指标为每个数据集的学习曲线下的面积(ALC),具体计算方式如下:
- 在每一个时刻t,计算s(t) = Norm AUC = 2 * AUC - 1,s(t)是对时间t的函数
- 将时间归一化到[0,1]区间内,其中的T = 1200s为上限,t0是参考时间,默认为60s
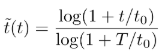
- 然后将s(t)在归一化后的时间上进行积分得到ALC
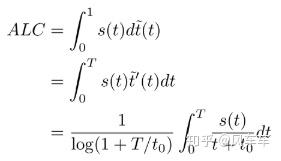
最后算的就是下面这些图像蓝色部分的面积,取平均排名为最后的排名


算法
我们是直接在AutoCV冠军的代码上改的(hhhh调参大法好),人家写的确实很牛逼,并且也拿了AutoCV2的冠军,我自己有很多地方尝试着去改发现都没有他们的版本好,不过后来修修补补也取得了一些提升,他们的代码在这https://github.com/kakaobrain/autoclint,我的代码在这https://github.com/tanglang96/AutoCV2,我就不专门说我改过的部分了,整体一起来总结思路会清晰一些。
这个比赛的一大特色就是不仅最后AUC要够高,而且还要跑得快(香港记者那种),这样最后的ALC才会足够高,并且前面的时间比重会更大,所以要尽量减小前期的时间开销。
为了跑得快,我们直接上imagenet pretrain的resnet18来作为模型,只把最后的layer和fc层随机初始化,并且全部转换为fp16来计算。
为了抢到前面的面积,在第一个epoch跑完就直接拿出来test,但是每个数据集大小不一样,这里的一个epoch就直接固定了batch的个数,就是跑完固定的step作为一个epoch。
另外一个比较蛋疼的地方是某个数据集下图像的大小不一定一致,不过按照经验来看这个系列比赛的数据都不会太复杂,因为要求在20min内跑完,所以直接就裁剪为64以下的size,这样会快很多,并且精度不会有太大损失。
AutoCV2的比赛是图像视频数据集都有,视频处理起来会很蛋疼,对于这种很简单的数据集,我们直接尝试在时间帧上求了个平均,将视频降维成图像来用resnet18处理,最后发现效果还挺好hhhh,并且这样跑的也比较快。
这个比赛还有个关键的地方是需要自己来判断什么时候进行test,如果测试太频繁则会减小训练的时间,影响最后的精度,测试太少则会取得较小的ALC,因此需要谨慎的选择进行测试的时间。而是否应该进行测试取决于是否在验证集上有较好的性能,如果每一次训练后都在验证集上进行验证则会浪费很多时间,这里我们设置了一定的限制条件来决定是否在这次训练结束之后进行验证,包括训练集精度是否足够/训练时间是否过长/是否进行了连续验证等。
这套策略其实还挺复杂的。。。东西很杂,工程上的技巧比较多,比较难搞的两个地方是overfit和训练发散的情况,kakaobrain(AutoCV冠军)用的是Fast AutoAugmentation,在训练后期进行数据增强,不过有些size比较小的数据集还是搞不定,我也尝试过用小模型/dropout等方法,发现其实都不太work,直到最后也没搞定。训练发散的情况比较容易被忘掉。。因为有可能feedback上的学习率都没啥问题,但是盲测就扑街了,这里我们是写了个handler来处理这种异常,比如训练loss一下涨的比较多就回到上一个epoch的state然后减小学习率重新开始这个epoch。
总结
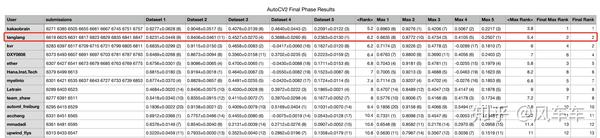
最后是feedback拿了个第一,盲测只有第二。。。
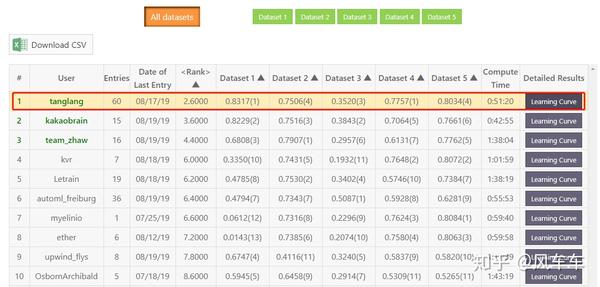


feedback的学习曲线如下
盲测的学习曲线


总体而言还是工程技巧比较多(可能是因为要刚速度),算法没什么新鲜的,最后感觉还是蛮有趣的hhh