
一.机器学习基础与特征工程
1.机器学习基础
1.1 数学基础
需要的数学知识:
高等数学、线性代数、概率与统计。
当然一开始不用深入进去,可以在学习过程中逐步积累。
1.2 编程语言
人工智能领域很火的领域的自然是Python,门槛也低,可以作为机器学习入门的首选语言。
有精力的话,再学习C/C++,多一门语言傍身不是坏事。
1.3 机器学习的开发流程
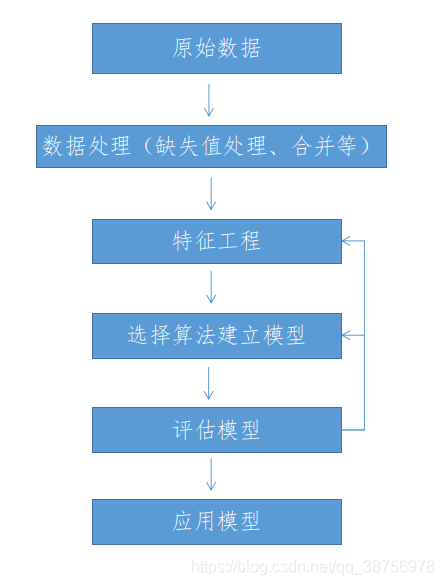
1)从公司原有的数据库或者爬虫等途径获得原始数据
我们所拿到的数据,大致分为两种类型:离散型数据和连续型数据。
2)对原始数据进行数据处理,python中可以使用pandas库。
pandas 库 参考文档 https://pandas.pydata.org/pandas-docs/stable/
3)特征处理:非常重要的一步,直接影响模型的预测结果
4)然后选择合适的算法,构建模式
5)对模型进行评估,是否符合预期,如何不理想,需要重新选择算法,或者对数据重做特征处理
6)评估OK后,模型直接应用
2.scikit-learn库
scikit-learn 是基于 Python 语言的机器学习工具:
简单高效的数据挖掘和数据分析工具
可供大家在各种环境中重复使用
建立在 NumPy ,SciPy 和 matplotlib 上
开源,可商业使用 - BSD许可证
通过这个库来逐步揭开机器学习的面纱.
2.1 特征工程
2.1.1 特征抽取
scikit-learn库提供了特征抽取的API:sklearn.feature_extraction
- 字典特征抽取 sklearn.feature_extraction.DictVectorizer
from sklearn.feature_extraction import DictVectorizer
def dict_ex():
"""
字典数据抽取
:return:
"""
list_demo = [{'city': '美国', 'new_add': 24500},
{'city': '俄罗斯', 'new_add': 4000},
{'city': '英国', 'new_add': 5600}]
dict_ins = DictVectorizer(sparse=False)
data = dict_ins.fit_transform(list_demo)
print(dict_ins.get_feature_names())
print(data.astype('int'))
if __name__ == '__main__':
dict_ex()
结果
['city=俄罗斯', 'city=美国', 'city=英国', 'new_add']
[[ 0 1 0 24500]
[ 1 0 0 4000]
[ 0 0 1 5600]]
- 文本特征抽取 sklearn.feature_extraction.text.CountVectorizer
限制英文,可以使用分词工具
from sklearn.feature_extraction.text import CountVectorizer
def text_ex():
"""
文本特征抽取
:return:
"""
text_demo = ["""
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
"""]
cv = CountVectorizer()
data = cv.fit_transform(text_demo)
print(cv.get_feature_names())
print(data) # 默认为sparse格式
print(data.toarray()) # 转化为数组
if __name__ == '__main__':
text_ex()
结果
['although', 'ambiguity', 'and', 'are', 'aren', 'at', 'bad', 'be', 'beats', 'beautiful', 'better', 'break', 'cases', 'complex', 'complicated', 'counts', 'dense', 'do', 'dutch', 'easy', 'enough', 'errors', 'explain', 'explicit', 'explicitly', 'face', 'first', 'flat', 'good', 'great', 'guess', 'hard', 'honking', 'idea', 'if', 'implementation', 'implicit', 'in', 'is', 'it', 'let', 'may', 'more', 'namespaces', 'nested', 'never', 'not', 'now', 'obvious', 'of', 'often', 'one', 'only', 'pass', 'practicality', 'preferably', 'purity', 're', 'readability', 'refuse', 'right', 'rules', 'should', 'silenced', 'silently', 'simple', 'sparse', 'special', 'temptation', 'than', 'that', 'the', 'there', 'those', 'to', 'ugly', 'unless', 'way', 'you']
(0, 9) 1
(0, 38) 10
(0, 10) 8
: :
(0, 40) 1
(0, 42) 1
(0, 73) 1
[[ 3 1 1 1 1 1 1 3 1 1 8 1 1 2 1 1 1 2 1 1 1 1 2 1
1 1 1 1 1 1 1 1 1 3 2 2 1 1 10 3 1 2 1 1 1 3 1 2
2 2 1 3 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 2 1 8 1 5
1 1 5 1 2 2 1]]
汉字的特征提取示例
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def zh_exc():
"""
中文特征值
:return:
"""
text_demo1 = """
我与父亲不相见已二年余了,我最不能忘记的是他的背影。那年冬天,祖母死了,父亲的差使也交卸了,
正是祸不单行的日子,我从北京到徐州,打算跟着父亲奔丧回家。到徐州见着父亲,看见满院狼藉的东西,
又想起祖母,不禁簌簌地流下眼泪。父亲说,“事已如此,不必难过,好在天无绝人之路!
"""
text_demo2 = """
沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,
蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。
今晚却很好,虽然月光也还是淡淡的。
"""
c1 = jieba.cut(text_demo1)
c2 = jieba.cut(text_demo2)
# 转换成字符串
text1 = ' '.join(list(c1))
text2 = ' '.join(list(c2))
cv = CountVectorizer()
data = cv.fit_transform([text1, text2])
print(cv.get_feature_names())
print(data.toarray())
if __name__ == '__main__':
zh_exc()
结果
['一些', '一旁', '一条', '不必', '不禁', '不能', '东西', '事已如此', '二年', '交卸', '今晚', '冬天', '北京', '名字', '四面', '回家', '夜晚', '天无绝人之路', '奔丧', '寂寞', '少人', '差使', '幽僻', '徐州', '忘记', '怕人', '想起', '打算', '日子', '晚上', '曲折', '更加', '月光', '有些', '杨柳', '正是', '没有', '沿着', '流下', '淡淡的', '满院', '煤屑', '父亲', '狼藉', '白天', '相见', '看见', '眼泪', '知道', '祖母', '祸不单行', '簌簌', '背影', '荷塘', '蓊蓊郁郁', '虽然', '许多', '跟着', '路上', '还是', '这是', '那年', '长着', '阴森森', '难过']
[[0 0 0 1 1 1 1 1 1 1 0 1 1 0 0 1 0 1 1 0 0 1 0 2 1 0 1 1 1 0 0 0 0 0 0 1
0 0 1 0 1 0 5 1 0 1 1 1 0 2 1 1 1 0 0 0 0 1 0 0 0 1 0 0 1]
[1 1 2 0 0 0 0 0 0 0 1 0 0 1 1 0 1 0 0 1 1 0 1 0 0 1 0 0 0 1 1 1 2 1 1 0
1 1 0 1 0 1 0 0 1 0 0 0 1 0 0 0 0 2 1 1 1 0 1 1 1 0 1 1 0]]
- TF-IDF 核心内容就是评估一字词的重要程度
对应的API sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def tfidf_ext():
text_demo1 = """
我与父亲不相见已二年余了,我最不能忘记的是他的背影。那年冬天,祖母死了,父亲的差使也交卸了,
正是祸不单行的日子,我从北京到徐州,打算跟着父亲奔丧回家。到徐州见着父亲,看见满院狼藉的东西,
又想起祖母,不禁簌簌地流下眼泪。父亲说,“事已如此,不必难过,好在天无绝人之路!
"""
text_demo2 = """
沿着荷塘,是一条曲折的小煤屑路。这是一条幽僻的路;白天也少人走,夜晚更加寂寞。荷塘四面,长着许多树,
蓊蓊郁郁的。路的一旁,是些杨柳,和一些不知道名字的树。没有月光的晚上,这路上阴森森的,有些怕人。
今晚却很好,虽然月光也还是淡淡的。
"""
c1 = jieba.cut(text_demo1)
c2 = jieba.cut(text_demo2)
# 转换成字符串
text1 = ' '.join(list(c1))
text2 = ' '.join(list(c2))
tf = TfidfVectorizer()
data = tf.fit_transform([text1, text2])
print(tf.get_feature_names())
print(data.toarray())
if __name__ == '__main__':
tfidf_ext()
结果
['一些', '一旁', '一条', '不必', '不禁', '不能', '东西', '事已如此', '二年', '交卸', '今晚', '冬天', '北京', '名字', '四面', '回家', '夜晚', '天无绝人之路', '奔丧', '寂寞', '少人', '差使', '幽僻', '徐州', '忘记', '怕人', '想起', '打算', '日子', '晚上', '曲折', '更加', '月光', '有些', '杨柳', '正是', '没有', '沿着', '流下', '淡淡的', '满院', '煤屑', '父亲', '狼藉', '白天', '相见', '看见', '眼泪', '知道', '祖母', '祸不单行', '簌簌', '背影', '荷塘', '蓊蓊郁郁', '虽然', '许多', '跟着', '路上', '还是', '这是', '那年', '长着', '阴森森', '难过']
[[0. 0. 0. 0.12598816 0.12598816 0.12598816
0.12598816 0.12598816 0.12598816 0.12598816 0. 0.12598816
0.12598816 0. 0. 0.12598816 0. 0.12598816
0.12598816 0. 0. 0.12598816 0. 0.25197632
0.12598816 0. 0.12598816 0.12598816 0.12598816 0.
0. 0. 0. 0. 0. 0.12598816
0. 0. 0.12598816 0. 0.12598816 0.
0.62994079 0.12598816 0. 0.12598816 0.12598816 0.12598816
0. 0.25197632 0.12598816 0.12598816 0.12598816 0.
0. 0. 0. 0.12598816 0. 0.
0. 0.12598816 0. 0. 0.12598816]
[0.15617376 0.15617376 0.31234752 0. 0. 0.
0. 0. 0. 0. 0.15617376 0.
0. 0.15617376 0.15617376 0. 0.15617376 0.
0. 0.15617376 0.15617376 0. 0.15617376 0.
0. 0.15617376 0. 0. 0. 0.15617376
0.15617376 0.15617376 0.31234752 0.15617376 0.15617376 0.
0.15617376 0.15617376 0. 0.15617376 0. 0.15617376
0. 0. 0.15617376 0. 0. 0.
0.15617376 0. 0. 0. 0. 0.31234752
0.15617376 0.15617376 0.15617376 0. 0.15617376 0.15617376
0.15617376 0. 0.15617376 0.15617376 0. ]]
2.1.2 特征处理
什么是特征处理?就是通过特定的数学方法将数据转换成我们算法要求的数据。
- 归一化
min-max 归一化的公式为:
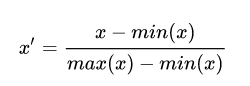
mean 归一化的公式为:
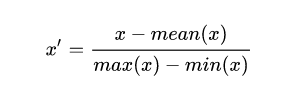
其中 mean(x)、min(x) 和 max(x) 分别是样本数据的平均值、最小值和最大值。
再求X``
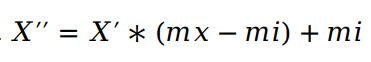
其中mx,mi分别为指定区间[mi, mx],一般mx为1,mi为0。
归一化的目的:通过对原始数据进行变换把数据映射到指定区间之间,一般是[0,1],那就是省去求X``, 这步可以省略。
sklearn库提供了归一化API:sklearn.preprocessing.MinMaxScaler
代码示例:
from sklearn.preprocessing import MinMaxScaler
def mm_ex():
"""
归一化示例
:return:
"""
test_dict = [[99,1,18,1002],
[88,4,18,1400],
[89, 4,25,1201],
[97,2,19,2800]]
mm = MinMaxScaler()
data = mm.fit_transform(test_dict)
print(data)
if __name__ == '__main__':
mm_ex()
结果
[[1. 0. 0. 0. ]
[0. 1. 0. 0.22135706]
[0.09090909 1. 1. 0.11067853]
[0.81818182 0.33333333 0.14285714 1. ]]
归一化的结果因最大值和最小值而变化,所以容易特异点数据影响,如
test_dict = [[99,1,18,200000],
[88,4,18,1400],
[89, 4,25,1201],
[97,2,19,2800]]
200000这个数值就对结果有很大影响。
- 标准化
公式
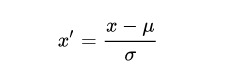
u为平均值,σ为标准差
sklearn提供了标准化API: scikit-learn.preprocessing.StandardScaler
代码示例
from sklearn.preprocessing import StandardScaler
def standard_ex():
"""
标准化API示例
:return:
"""
test_dict = [[99, 1, 18, 1002],
[88, 4, 18, 1400],
[89, 4, 25, 1201],
[97, 2, 19, 2800]]
ss = StandardScaler()
data = ss.fit_transform(test_dict)
print(data)
if __name__ == '__main__':
standard_ex()
结果
[[ 1.1941005 -1.34715063 -0.68599434 -0.84743801]
[-1.09026568 0.96225045 -0.68599434 -0.28413057]
[-0.88259602 0.96225045 1.71498585 -0.56578429]
[ 0.7787612 -0.57735027 -0.34299717 1.69735287]]

