
【CVPR2016论文快讯】面部特征点定位的最新进展

深度学习大讲堂致力于推送人工智能,深度学习方面的最新技术,产品以及活动。请关注我们的知乎专栏!
摘要
CVPR2016刚刚落下帷幕,本文对面部特征点定位的论文做一个简单总结,让大家快速了解该领域最新的研究进展,希望能给读者们带来启发。CVPR2016相关的文章大致可以分为三大类:处理大姿态问题,处理表情问题,处理遮挡问题。
1.姿态鲁棒的人脸对齐方法
1.1 Face Alignment Across Large Poses: A 3D Solution [1]
这里首先介绍一篇大会口头报告文章,来自中国科学院自动化研究所Xiangyu Zhu等人的工作。极端姿态下(如侧脸),一些特征点变了不可见,不同姿态下的人脸表观也存在巨大差异,这些问题都导致大姿态下面部特征点定位任务极具挑战性。为了解决以上问题,本文提出一种基于3D人脸形状的定位方法3DDFA,算法框架如下图所示:
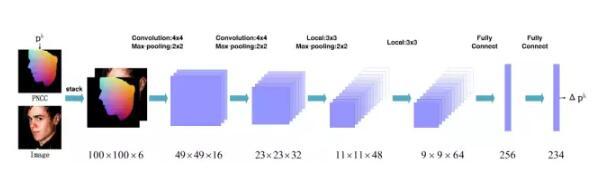

算法输入为100x100的RGB图像和PNCC (Projected Normalized Coordinate Code) 特征,PNCC特征的计算与当前形状相关,可以反映当前形状的信息;算法的输出为3D人脸形状模型参数。使用卷积神经网络拟合从输入到输出的映射函数,网络包含4个卷积层,3个pooling层和2个全连接层。通过级联多个卷积神经网络直至在训练集上收敛,PNCC特征会根据当前预测的人脸形状更新,并作为下一级卷积神经网络的输入。此外,卷积神经网络的损失函数也做了精心的设计,通过引入权重,让网络优先拟合重要的形状参数,如尺度、旋转和平移;当人脸形状接近ground truth时,再考虑拟合其他形状参数。实验证明该损失函数可以提升定位模型的精度。由于参数化形状模型会限制人脸形状变形的能力,作者在使用3DDFA拟合之后,抽取HOG特征作为输入,使用线性回归来进一步提升2D特征点的定位精度。
训练3DDFA模型,需要大量的多姿态人脸样本。为此,作者基于已有的数据集如300W,利用3D信息虚拟生成不同姿态下的人脸图像,核心思想为:先预测人脸图像的深度信息,通过3D旋转来生成不同姿态下的人脸图像,如下图所示:


(a)为原始图像,(b,c,d)为生成的虚拟样本,yaw方向的角度依次增加20°,30°和40°。生成虚拟人脸图像的code和3DDFA的code可以在以下链接下载:
http://www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3DDFA/main.htm
1.2 Large-Pose Face Alignment via CNN-Based Dense 3D Model Fitting [2]
这篇文章是来自密西根州立大学的Amin Jourabloo和Xiaoming Liu的工作。和上一篇文章的出发点一样,作者试图使用3D人脸建模解决大姿态下面部特征点定位问题。2D的人脸形状U可以看成是3D人脸形状A通过投影变化m得到,如下图所示:
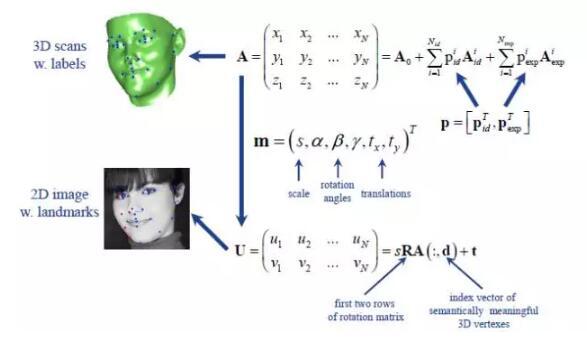

3D人脸形状模型可以表示为平均3D人脸形状A0与若干表征身份、表情的基向量Aid和Aexp通过p参数组合而成。面部特征点定位问题(预测U)可以转变为同时预测投影矩阵m和3D人脸形状模型参数p。算法的整体框架图如下所示:
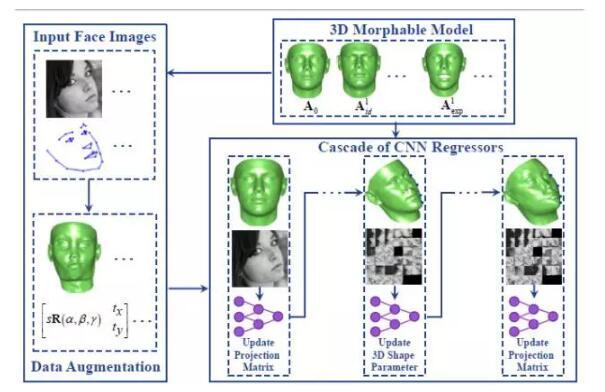

作者通过级联6个卷积神经网络来完成这一任务。首先以整张人脸图像作为输入,来预测投影矩阵的更新。使用更新后的投影矩阵计算当前的2D人脸形状,基于当前的2D人脸形状抽取块特征作为下一级卷积神经网络的输入,下一级卷积神经网络用于更新3D人脸形状。基于更新后的3D人脸形状,计算可得当前2D人脸形状的预测。根据新的2D人脸形状预测,抽取块特征输入到卷积神经网络中来更新投影矩阵,交替迭代优化求解投影矩阵m和3D人脸形状模型参数p,直到在训练集收敛。值得一提的是,该方法在预测3D人脸形状和投影矩阵的同时也考虑到计算每一个特征点是否可见。如果特征点不可见,则不使用该特征点上的块特征作为输入,这是普通2D人脸对齐方法难以实现的。此外,作者提出两种pose-invariant的特征Piecewise Affine-Warpped Feature (PAWF)和Direct 3D Projected Feature (D3PF),可以进一步提升特征点定位的精度。
1.3 Unconstrained Face Alignment via Cascaded Compositional Learning [3]
这篇文章是来自香港中文大学的Shizhan Zhu等人的工作。和前面两篇工作不同,本文提出的方法Cascaded Compositional Learning (CCL)没有从3D人脸建模出发来解决大姿态下人脸对齐问题,而是将所有人脸样本划分成多个域(Domain)来分别处理,并通过学习组合系数,融合不同域的结果来得到最终的定位结果。方法的出发点与GSDM[4]类似,不过GSDM依赖视频中上一帧的人脸对齐结果来选择域,所以不能处理静态图片的人脸对齐问题。本文提出的方法巧妙地学习组合系数来自动完成域的选择,从而有效地解决GSDM的局限性。CCL算法的示意图如下所示:
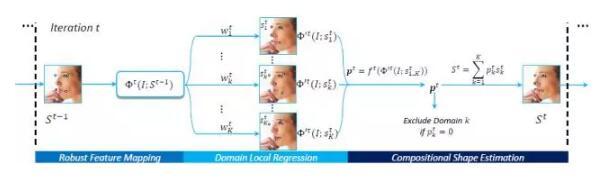

算法整体框架为级联形状回归,每一级包含三块,分别是特征提取模块,形状回归模块和组合系数预测模块。其中特征提取模块在LBF [5]特征的基础上引入特征点是否可见的信息,为后续预测组合系数提供重要线索,当出现自遮挡情况时(Self-occlusion)比LBF特征更加鲁棒。形状回归模块包含K个形状回归器,分别对应于K个域。组合系数预测模块融合K个形状回归器的预测,生成最终的定位结果。该方法在AFW和AFLW数据集上均取得了State-of-the-art的结果,在单核的台式机上达到350 FPS,方法简单、高效。
2.表情鲁棒的人脸对齐方法
2.1 Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection [6]
前面给大家介绍了三篇主要解决大姿态下人脸对齐问题的文章,接下来给大家带来一篇联合处理表情识别和面部特征点检测的文章。这篇文章是来自Rensselaer Polytechnic Institute的Yue Wu和Qiang Ji的工作。考虑到表情识别和人脸对齐是两个非常相关的人脸感知任务,作者在级联形状回归算法框架的基础上,提出新的Constrained Joint Cascade Regression Framework (CJCRF)来联合预测表情(这里是识别脸部运动单元(Facial Action Unit))和面部特征点定位。下图为算法框架图:
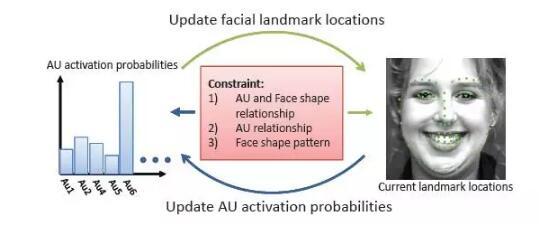

算法分两步,首先使用受限玻尔兹曼机模型,建模脸部运动单元与人脸形状之间的联系。下图(a)蓝色人脸形状展示了不同的脸部运动单元(AU12,AU15和AU25)对应的人脸形状先验(红色为平均人脸形状)。下图(b):给定一个特定的人脸形状(蓝色),不同的脸部运动单元(AU)被激活的概率分布情况。


接着,以脸部运动单元与人脸形状之间的联系作为约束,嵌入到级联形状回归框架下来联合估计特征点的位置和脸部运动单元。实验表明,Constrained Joint Cascade Regression Framework (CJCRF)可以同时提升特征点定位任务和脸部运动单元识别任务的精度。下图展示了不引入脸部运动单元信息(图a)和引入脸部运动单元信息(图b)的定位结果,可以看出引入脸部运动单元信息可以提升面部特征点定位模型对于夸张表情的鲁棒性。


3.遮挡鲁棒的人脸对齐方法
3.1 Occlusion-Free Face Alignment: Deep Regression Networks Coupled With De-Corrupt AutoEncoders [7]
最后介绍本人的一篇工作,主要是处理遮挡问题。面部特征点定位系统在出现遮挡时往往会性能退化。为此,本文提出一个新的算法框架Deep Regression Networks Coupled WithDe-corrupt Autoencoders(DRDA)来显示处理面部特征点定位任务中的遮挡问题。算法总体框架如下所示:
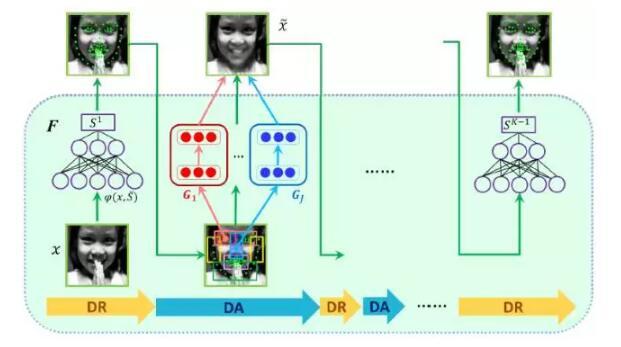

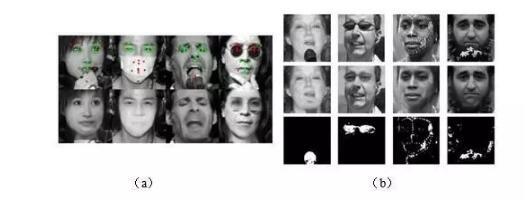
去遮挡网络(De-corrupt Autoencoders)用于自动恢复被遮挡区域的人脸信息。由于姿态、表情的影响,人脸表观千差万别,很难仅使用一个去遮挡网络来很好地恢复人脸表观细节。为了恢复较为精细的人脸表观,本文依据当前预测的人脸形状,将人脸划分为若干个区域,对每个区域学习一个去遮挡网络,来去除遮挡物。深度回归网络(Deep Regression Networks)使用去遮挡后的人脸作为输入,来预测人脸形状。通过级联多个去遮挡网络和深度回归网络,逐步优化人脸去遮挡结果和特征点定位的结果。该方法不但可以预测出特征点是否被遮挡(如图a所示),而且能定位出遮挡物区域,并最终得到“干净的”人脸(如图b所示)。

结语
以上介绍的几个工作分别从姿态、表情、遮挡等因素出发设计算法,提升特征点定位模型的鲁棒性。所有方法或多或少都和级联形状回归框架有关,足见级联形状回归方法的有效性。但级联形状回归框架下的每一级回归模型都是独立训练的,并不是一个端到端(End-to-End)的方法。英国帝国理工大学的George Trigeorgis等人提出使用Convolutional Recurrent Neural Network 来解决特征点定位问题 [8],可以端到端地训练特征点定位模型,比传统的级联回归方法有显著的性能提升。此外,姿态估计、表情识别以及遮挡检测与特征点定位任务有很强的依赖关系,联合考虑这些任务或许是人脸分析应用里不错的解决方案。马里兰大学的Rama Chellappa教授在CVPR2016 ChaLearn Looking at People and Faces Workshop的特邀报告上介绍了HyperFace。这一工作的核心思想也是融合卷积神经网络不同层的feature map来同时完成人脸检测、面部特征点定位、姿态预测和性别识别等任务。再者,以上介绍的大部分工作与深度模型相关,如何学习低复杂度的定位网络,能在手持终端上高效准确地定位面部关键点也是一个值得探索的问题。
参考文献
[1] Xiangyu Zhu, Zhen Lei, Xiaoming Liu, Hailin Shi, Stan Z. Li. Face Alignment Across Large Poses: A 3D Solution. CVPR 2016.
[2] Amin Jourabloo, Xiaoming Liu. Large-Pose Face Alignment via CNN-Based Dense 3D Model Fitting. CVPR 2016.
[3] Shizhan Zhu, Cheng Li, Chen-Change Loy, Xiaoou Tang. Unconstrained Face Alignment via Cascaded Compositional Learning. CVPR 2016.
[4] Xuehan Xiong, De la Torre Fernando. Global supervised descent method. CVPR 2015.
[5] Shaoqing Ren, Xudong Cao, Yichen Wei, Jian Sun. Face Alignment at 3000 FPS via Regressing Local Binary Features. CVPR 2014.
[6] Yue Wu, Qiang Ji. Constrained Joint Cascade Regression Framework for Simultaneous Facial Action Unit Recognition and Facial Landmark Detection. CVPR 2016.
[7] Jie Zhang, Meina Kan, Shiguang Shan, Xilin Chen. Occlusion-Free Face Alignment: Deep Regression Networks Coupled With De-Corrupt AutoEncoders. CVPR 2016.
[8] George Trigeorgis, Patrick Snape, Mihalis A. Nicolaou, Epameinondas Antonakos, Stefanos Zafeiriou. Mnemonic Descent Method: A Recurrent Process Applied for End-To-End Face Alignment. CVPR 2016.
该文章属于“深度学习大讲堂”原创,如需要转载,请联系@果果是枚开心果.
作者简介:

张杰,中科院计算技术研究所VIPL课题组博士生,专注于深度学习技术及其在人脸识别领域的应用。相关研究成果发表在计算机视觉国际顶级学术会议ICCV, CVPR和ECCV,拥有两篇关于人脸跟踪和对齐方面的专利,并担任国际顶级期刊TPAMI,TIP和TNNLS审稿人。
欢迎大家关注我们的微信公众号,搜索微信名称:深度学习大讲堂
