
时间序列分析|(ETS)指数平滑模型及R中实践

你是否想要做时间序列分析,但却不知道代码怎么写?
你是否不清楚时间序列分析各种模型该在什么情况下使用?
本文将针对以上两个问题,带你入门时间序列分析~
等等!
不止’入门‘
读完这篇,你立即就能在R中写出不同模型的相应代码~
先介绍以下我自己吧~
我目前是Warner Bros.做Data Scientist,记得刚入职时,老板就跟我说未来我的主要任务是用各种类型的时间序列模型做预测:预测好莱坞游览车未来三年每天的乘客数量、预测<Aquaman>, <Joker>,<Wonder Women>等华纳出品的电影每分钟的观看量,预估艾伦秀不同播出计划的未来收视率和收入等等等等~~~
刚入职的第一个月每天愁眉不展,时间序列的方法很多,很多时候,即使理论基础学懂了,但是到实践上,R里的code要怎么写又是个大问题,网上的很多教程,教授了公式,却不教授具体的代码怎么写。
幸运的是,老板是个比较技术咖的人,他教会了我很多实际操作上的东西,结合我过去七个月做过的各种时间序列模型,决定好好总结一下时间序列常见模型各自的适用场合、特征等理论知识,更重要的是,每个模型在R里的具体代码实现以及操作步骤,希望能帮助到需要使用R来做时间序列的朋友们~
本节将介绍使用指数平滑模型进行预测的一般步骤及R中code
指数平滑模型适用性:对于时间序列数据做短期预测
方法:
- 简单指数平滑
- Holt法
- Holt-Winters
以上三种方法的适用条件不同,对于不同特征的时间序列数据,需以上应用不同方法。
本文将根据方法逐个介绍 ,先介绍理论背景,再介绍R中实践 (附code)
看完本文,您可以:在R中使用三种指数平滑模型来拟合时间序列数据,并且做出未来预测
简单指数平滑
适用:时间序列数据没有趋势特征,也没有季节性特征
理论背景:
简单指数平滑方法提供了一种估计当前时间点水平的方法。
平滑度由参数alpha控制;用于当前时间点的水平估计。
alpha的值;介于0和1之间。alpha值接近0表示在对未来值进行预测时,对最新观察值的权重很小。
R中实践
数据来源: 大家可以下载好该数据,跟着以下R中步骤一步一步来操作
数据内容: 该数据包含1813年至1912年伦敦的年降雨量(以英寸为单位)(来自Hipel和McLeod的原始数据,1994年)。
我们首先将数据读入R并通过键入以下内容进行绘制:
rain <- scan("http://robjhyndman.com/tsdldata/hurst/precip1.dat",skip=1)
rainseries <- ts(rain,start=c(1813))
plot.ts(rainseries)
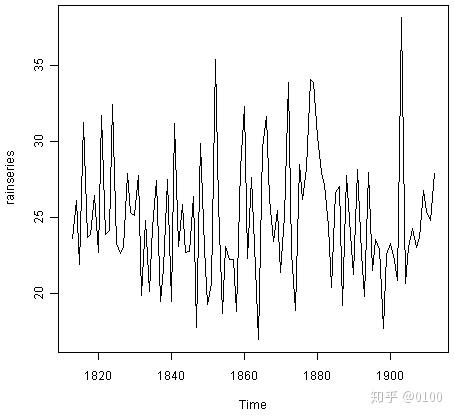
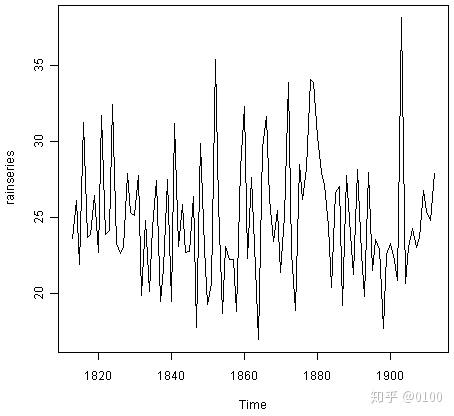
我们可以从图中看到数据的趋势基本保持稳定,且时间序列中的随机波动不随时间变化,因此,我们可以使用简单的指数平滑进行预测。
要使用R中的简单指数平滑进行预测,我们可以使用R中的“ HoltWinters()”函数拟合指数平滑预测模型,我们需要设置参数beta = FALSE和HoltWinters()函数中的gamma = FALSE(β和gamma参数用于Holt的指数平滑或Holt-Winters指数平滑,如下所述)。
HoltWinters()函数返回一个列表变量,其中包含几个命名元素。
例如,要使用简单的指数平滑法来预测伦敦年降雨量的时间序列,输入:
rainseriesforecasts <- HoltWinters(rainseries, beta=FALSE, gamma=FALSE)
得到结果:
> rainseriesforecasts
Smoothing parameters:
alpha: 0.02412151
beta : FALSE
gamma: FALSE
Coefficients:
[,1]
a 24.67819
HoltWinters()的输出告诉我们,alpha参数的估计值约为0.024。这非常接近于零,意味着
该预测对于近期数据,只给了较小权重,对于久远数据给了较大权重。
在上面的示例中,我们将HoltWinters()函数的输出存储在列表变量“ rainseriesforecasts”中。HoltWinters()对于训练集的模型拟合值存储在一个名为“ fitted”的命名元素中,我们可以通过以下code获取模型拟合值:
rainseriesforecasts$fitted
得到结果:
Time Series:
Start = 1814
End = 1912
Frequency = 1
xhat level
1814 23.56000 23.56000
1815 23.62054 23.62054
1816 23.57808 23.57808
1817 23.76290 23.76290
1818 23.76017 23.76017
1819 23.76306 23.76306
1820 23.82691 23.82691
...
1905 24.62852 24.62852
1906 24.58852 24.58852
1907 24.58059 24.58059
1908 24.54271 24.54271
1909 24.52166 24.52166
1910 24.57541 24.57541
1911 24.59433 24.59433
1912 24.59905 24.59905
通过输入以下内容,我们可以将训练数据与其模型拟合值作图:
> plot(rainseriesforecasts)
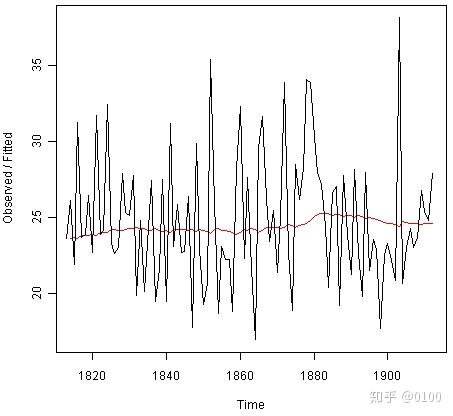
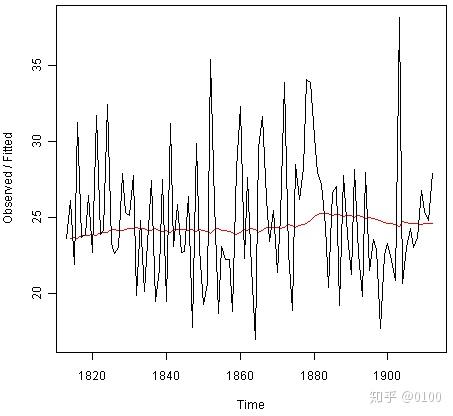
该图以黑色显示原始时间序列,以红线显示拟合值。拟合的时间序列比原始训练集平滑得多。
为了衡量预测的准确性,我们可以计算样本内预测误差的平方误差总和。
误差平方和存储在名为“ SSE”的列表变量“ rainseriesforecasts”的命名元素中,因此我们可以通过输入以下内容获取其值:
> rainseriesforecasts$SSE [1] 1828.855
也就是说,这里的平方误差总和是1828.855。
在简单的指数平滑中,通常将时间序列中的第一个值用作该级别的初始值。例如,在伦敦的降雨时间序列中,第一个值是1813年的降雨的23.56(英寸)。可以使用“ l.start”参数在HoltWinters()函数中为水平指定初始值。例如,要进行将级别的初始值设置为23.56的预测,输入:
> HoltWinters(rainseries, beta=FALSE, gamma=FALSE, l.start=23.56)
默认情况下,HoltWinters()仅对原始数据所在时间段进行预测,降雨时间序列的时间段为1813-1912。如若要对未来时间段进行预测,我们可以使用R“ forecast”包中的“ forecast.HoltWinters()”函数对其他时间点进行预测。要使用Forecast.HoltWinters()函数,我们首先需要安装“ forecast” R包:
> library("forecast")
接着,使用Forecast.HoltWinters()中的“ h”参数指定要进行预测的其他时间点。例如,要使用Forecast.HoltWinters()对1814-1820年(再增加8年)的降雨量进行预测,输入:
> rainseriesforecasts2 <- forecast.HoltWinters(rainseriesforecasts, h=8)
得到结果:
> rainseriesforecasts2
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
1913 24.67819 19.17493 30.18145 16.26169 33.09470
1914 24.67819 19.17333 30.18305 16.25924 33.09715
1915 24.67819 19.17173 30.18465 16.25679 33.09960
1916 24.67819 19.17013 30.18625 16.25434 33.10204
1917 24.67819 19.16853 30.18785 16.25190 33.10449
1918 24.67819 19.16694 30.18945 16.24945 33.10694
1919 24.67819 19.16534 30.19105 16.24701 33.10938
1920 24.67819 19.16374 30.19265 16.24456 33.11182
Forecast.HoltWinters()函数为提供了两个置信区间,分别为80%和95%。例如,1920年的预测降雨量约为24.68,其95%的预测间隔为(16.24,33.11)
要绘制由Forecast.HoltWinters()做出的预测,我们可以使用“ plot.forecast()”函数:
> plot.forecast(rainseriesforecasts2)
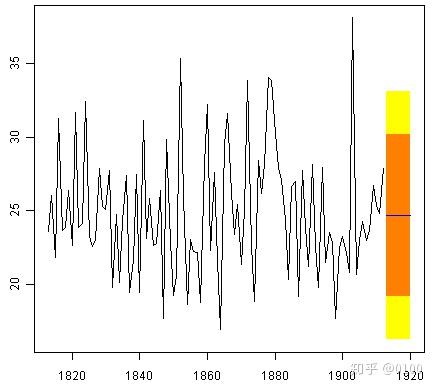

在这里,对1913-1920年的预测为蓝线,80%置信区间为橙色阴影区域,95%置信区间为黄色阴影区域。
以上便是简单指数平滑在R中的操作步骤啦~
Holt的指数平滑
适用:时间序列数据有趋势特征,但没有季节性特征
理论背景:
Holt的指数平滑估计了当前时间点的水平和斜率。
平滑由两个参数控制,α用于估计当前时间点的水平,而β用于估计当前时间点的趋势分量的斜率b。与简单的指数平滑化一样,参数alpha和beta的值在0到1之间,并且值接近于0意味着在对未来值进行预测时,对最新观察值的权重很小。
R中实践:
数据:1866年至1911年间女性裙子长度的时间序列数据。
(来自Hipel和McLeod的原始数据,1994年)
我们可以通过输入以下内容来读入并绘制R中数据:
> skirts <- scan("http://robjhyndman.com/tsdldata/roberts/skirts.dat",skip=5)
Read 46 items
> skirtsseries <- ts(skirts,start=c(1866))
> plot.ts(skirtsseries)
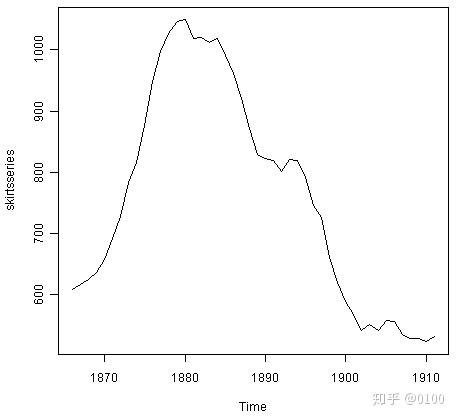

从图中可以看出,下摆直径从1866年的600左右增加到1880年的1050左右,然后在1911年减小到520左右。
为了进行预测,我们可以使用R中的HoltWinters()函数拟合预测模型。
要使用HoltWinters()进行Holt指数平滑,我们需要设置参数gamma = FALSE(gamma参数用于Holt-Winters指数平滑,如下所述)。
输入:
> skirtsseriesforecasts <- HoltWinters(skirtsseries, gamma=FALSE)
结果:
> skirtsseriesforecasts
Smoothing parameters:
alpha: 0.8383481
beta : 1
gamma: FALSE
Coefficients:
[,1]
a 529.308585
b 5.690464
> skirtsseriesforecasts$SSE
[1] 16954.18
alpha的估计值为0.84,beta的估计值为1.00。这些都很高,意味着模型给了近期数据更大的权重,给遥远数据较小的权重。
通过输入以下内容,我们可以将原始时间序列绘制为黑线,将模型拟合值绘制为红线。
> plot(skirtsseriesforecasts)
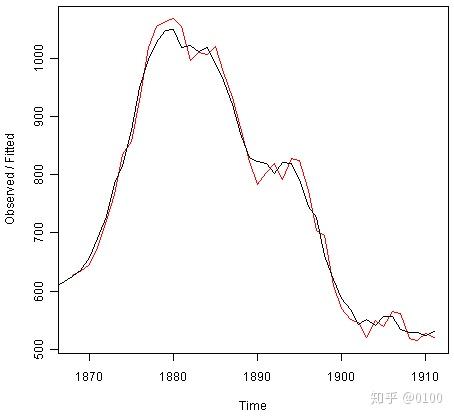

从上图中我们可以看到,样本内拟合值与观察值非常吻合。
如果愿意,可以通过对HoltWinters()函数使用“ l.start”和“ b.start”自变量来指定趋势分量的水平和斜率b的初始值。
通常将水平的初始值设置为时间序列中的第一个值(对于裙数据为608),将斜率的初始值设置为第二值减去第一值(对于裙数据为9)。
例如,要使用Holt指数平滑法将预测模型拟合到裙摆数据,其初始值为608,趋势分量的斜率b为9,输入:
> HoltWinters(skirtsseries, gamma=FALSE, l.start=608, b.start=9)
对于简单的指数平滑,我们可以使用“ forecast”包中的Forecast.HoltWinters()函数对未来时间进行预测。例如,我们的裙摆边的时间序列数据是1866年至1911年,因此我们可以预测1912年至1930年(另外19个数据点),输入以下内容进行预测:
> skirtsseriesforecasts2 <- forecast.HoltWinters(skirtsseriesforecasts, h=19)
> plot.forecast(skirtsseriesforecasts2)
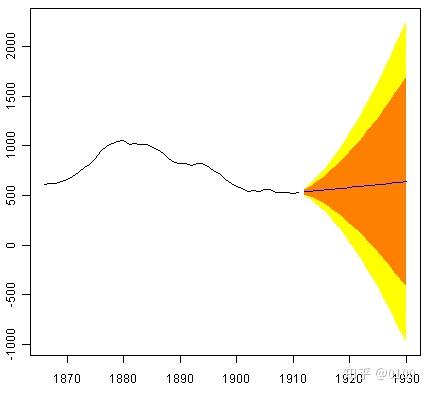

预测显示为蓝线,其中80%置信区间为橙色阴影区域,而95%置信区间为黄色阴影区域。
Holt-Winters指数平滑
适用:时间序列数据有趋势特征,且有季节性特征
理论背景:
Holt-Winters指数平滑法可估算当前时间点的水平,坡度和季节性变量。
平滑度由三个参数控制:alpha,beta和gamma,分别用于估计当前时间点的水平,趋势变量的斜率b和季节性分量。
参数alpha,beta和gamma的值都在0到1之间,并且接近0的值表示在对未来值进行预测时,对最新观察值的权重相对较小。
R中实践:
数据: 澳大利亚昆士兰州一个海滩度假小镇的纪念品商店的月度销售对数的时间序列
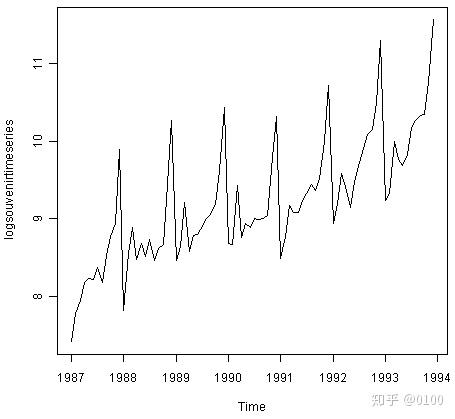

为了进行预测,我们可以使用HoltWinters()函数拟合预测模型。
输入:
> logsouvenirtimeseries <- log(souvenirtimeseries)
结果:
> souvenirtimeseriesforecasts <- HoltWinters(logsouvenirtimeseries)
> souvenirtimeseriesforecasts
Holt-Winters exponential smoothing with trend and additive seasonal component.
Smoothing parameters:
alpha: 0.413418
beta : 0
gamma: 0.9561275
Coefficients:
[,1]
a 10.37661961
b 0.02996319
s1 -0.80952063
s2 -0.60576477
s3 0.01103238
s4 -0.24160551
s5 -0.35933517
s6 -0.18076683
s7 0.07788605
s8 0.10147055
s9 0.09649353
s10 0.05197826
s11 0.41793637
s12 1.18088423
> souvenirtimeseriesforecasts$SSE
2.011491
alpha,beta和gamma的估计值分别为0.41、0.00和0.96。alpha的值(0.41)相对较低,表明当前时间点的水平估计是基于更遥远数据。beta的值为0.00,表示趋势分量的斜率b的估计未在时间序列上更新,而是设置为等于其初始值。相反,伽玛(0.96)的值很高,表明当前时间点的季节性成分估算仅基于最近的观测结果。
对于简单的指数平滑和Holt的指数平滑,我们可以将原始时间序列绘制为黑线,而将模型拟合值绘制为红线:
> plot(souvenirtimeseriesforecasts)
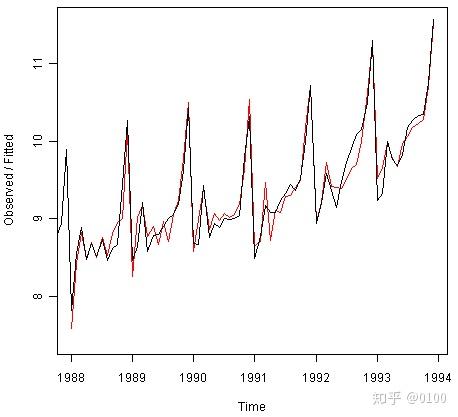
从图中可以看出,Holt-Winters指数方法预测了每年的11月左右的季节性高峰。
为了对原始时间序列中未包含的未来时间进行预测,我们使用“ forecast”包中的“ forecast.HoltWinters()”函数。
纪念品销售的原始数据是从1987年1月到1993年12月。如果我们要对1994年1月到1998年12月进行预测(还需要48个月),并绘制预测:
> souvenirtimeseriesforecasts2 <- forecast.HoltWinters(souvenirtimeseriesforecasts, h=48)
> plot.forecast(souvenirtimeseriesforecasts2)
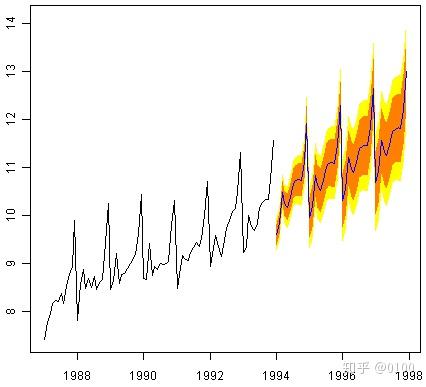

预测显示为蓝线,橙色和黄色阴影区域分别显示80%和95%的置信区间。
总结一下,
本篇介绍了三种指数平滑模型的方法以及其各自在R中的code:
- 简单指数平滑
- Holt法
- Holt-Winters
以上三种方法适用于不同特征的时间序列数据,并且都只能用于短期内的预测。
大家看完别忘了赞一个让更多人看到~
另外,欢迎关注我的专栏: 煮一锅数据汤
专栏定期分享数据分析方面干货,如时间序列模型实践、机器学习模型讲解、R编程语言操作、SQL小白入门等
