目标检测论文阅读:Feature Pyramid Networks for Object Detection

Feature Pyramid Networks for Object Detection
论文链接:https://arxiv.org/abs/1612.03144
代码链接:未公开,github上有第三方代码
CVPR2017的文章,已经是非常经典的文章了,在很多论文里基本都属于baseline一类的存在,CVPR2018里也有一些论文基于FPN做出了很不错的效果。其实对于做目标检测来说,FPN属于必读的文章,之前也已经了解了算法,但是感觉不自己过一下总是不踏实,总的来说算是自己经典论文补完计划的一部分~
本文主要研究的是针对目标检测中的尺度问题,尤其是小目标检测中存在的卷积神经网络分辨率和语义化程度之间的矛盾问题,并提出了一种特征金字塔网络的解决思路。
1. 问题介绍
CNN网络其实对于位置变化的适应性还是很强的,但是对尺度变化的表现就会差很多,所以检测问题基本都要考虑尺度怎么处理。那么首先来看一幅非常具有代表性的图,这张图涵盖了目前很多检测问题在处理物体scale上的思路:
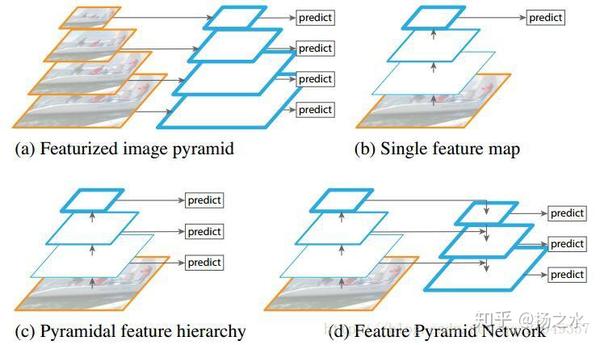

首先是(a)图,这个其实在非深度的方法中非常常见,通过将图像缩放到不同大小,构成一系列的图像金字塔网络,这样一些类似于固定滑窗的方法就可以检测到大小不同的物体了。这个在深度检测中也不是没有应用,比如MTCNN,但是用得都不会很深,而且使用也不广泛,主要就是内存和时间上的巨大开销问题,因为我们知道CNN提取特征非常耗时。
现在(b)图和(c)图的思路其实更加常见,Faster RCNN其实就是(b)图的思路,我用CNN网络的top层来进行预测,因为top层的语义化程度是最高的;但是我们知道,CNN的卷积操作考察的是局部像素之间的关联性、池化操作则对局部信息进行统计,因此CNN网络越top,feature map中的每个单元格的感受野就越大,相对的,就没有浅层那样精细,分辨率就会下降得比较厉害;这个问题在小目标上非常突出……
于是也有人尝试了类似图(c)的思路,比如SSD,在top层这种单元格感受野大的层上预测scales比较大的物体,而在浅层这种感受野小、分辨率比较高的层上预测scales比较小的物体……但是这样会导致的一个问题就是,浅层虽然分辨率提高了,语义化程度还是不够高,去预测小目标效果还是不好……
FPN就提出了一种解决思路,我在top层得到了语义化程度比较高的特征后,再不断升采样,然后和CNN网络中那些浅层特征融合,融合后的特征既有较高的语义性,也有较高的分辨率,这样再去分别预测不同scales的物体就会有比较好的效果了……另外,在实际使用的时候,作者的特征是across scales的,换句话说,在预测某个scale目标的时候,其它scales的特征也会起到一定的作用,这个就是FPN的整体思路。
2. 具体实现
网络的架构图如下图所示:
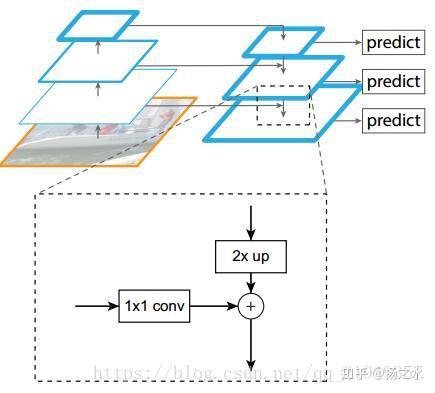

网络结构
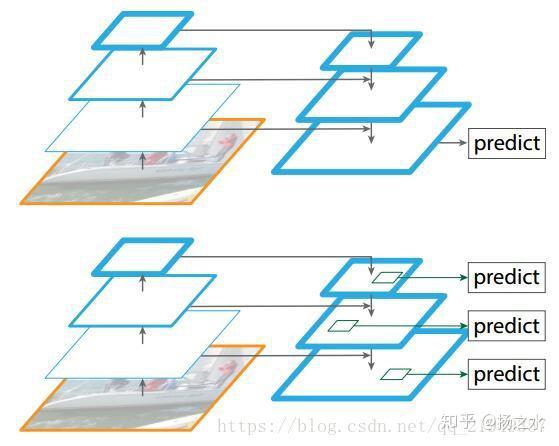
可以看到网络整体上有三条线路,一个是左面的CNN网络,作者称之为Bottom-up pathway;另一条则是将CNN得到的高语义化不断升采样,作者称之为top-down pathway;最后是将它们融合起来的侧边通道,作者称之为lateral connections,下面介绍一些细节
- bottom-up路线:作者使用了ResNet作为基础网络;这里还有一个,就是每个scales在哪个层上建立的问题。作者将大小相同的层都认为是一个stage的,而作者选用了一个stage里面最后的那一层来建立anchor。作者选取了四个尺度,分别简历在ResNet的conv2,conv3,conv4和conv5的output上,构成了C2,C3,C4,C5四个尺度的特征……而对应的融合后的特征是P2,P3,P4,P5
- top-donw路线与lateral connection:如图所以,later connection是一个1x1 conv层,可以用来减少通道数、并进行跨通道的信息融合;而top-down则是依次进行了x2的upsample;C5到P5则是直接用1x1的卷积层连接起来;另外,在叠加后,还会使用一个3x3的卷积核来消除混叠效应
在Faster RCNN当中的使用
作者改变了Faster RCNN,将FPN的思路糅合了进去
- RPN:首先就是RPN阶段,除了BackBone是ResNet外,最重要的一点是RPN阶段现在不需要在一个特征层上假设有不同scale的anchor了,由于有了P2~P5四个特征层,作者直接在每个特征层上假设有一个scales,对应32,64,128,256大小的物体;特别要指出的是,作者额外添加了一个P6层(由P5层进行stride 2的subsample得到),用来预测512大小的物体;ratios还是和原版一样
- RoI pooling与RCNN:原版的RoI pooling统一到同一个大小的feature map,但是这对FPN并不合适,因为FPN在RPN阶段抽取的候选框本来就含有不同的尺度,作者的方法是将不同尺度的候选框map into到不同大小的特征图,具体的公式这里就不贴了,可以参考论文;另外作者关于RoI pooling之后的网络结构也有一定不同,作者添加了两个1024的fc层在最终的分类与回归层前,作者认为这更加轻便(这里暂时不太懂,要结合源码理解下)
- 权值共享问题:这个特别拿出来提一下,每个特征层进行预测的结构是和原版Head一样的,不过比较特殊的是,作者这里采用了权值共享的策略,我的理解是在预测某个尺度的时候,其它尺度的特征也会参与预测,而不是各个尺度完全独立的预测
3.实验结果
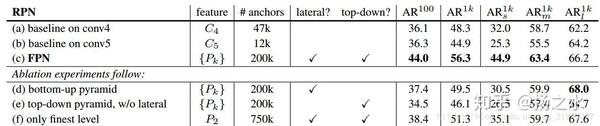
这部分无非就是一些对比实验了,比如RPN阶段我有没有lateral connection和top-down路线的话,我的召全率表现

又或者是我固定了RPN的候选框,然后看RCNN的分类回归结果:
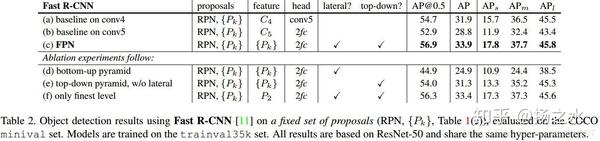

当然还有整体和Faster RCNN的比较,以及是否共享特征、更换BackBone的效果比较,这里就不一一提了。我觉得这里比较耐人寻味或者说比较有趣的是两个表格中(c)和(f)行的结果,它们的差异其实是这样的:

但是你可以看到,在RPN阶段,只用finest level效果是非常差的,但是在RCNN阶段差异就不会这么大,作者认为这主要是RoI pooling层是一个含有扭曲和变形的操作过程,因此对尺度的敏感度会小一点。
最后贴一个检测结果:


主要提升还是APs方面的,就是似乎没看到detection方面的运行时间比较,稍微有点遗憾,代码目前也没有找到。
4. 总结
由于目前还没怎么接触segmentation,因此关于这部分就不介绍了。总的来说,FPN还是非常经典的文章,思路还是很简单清晰的,小目标检测的分辨率与语义化之间有矛盾,那我就想办法获取同时获取分辨率和语义化信息,什么不足就解决什么,有点找出问题解决问题的很典型的思维方式的感觉,也可能是接触比较多,如果放在刚放出来的时候,应该也是很有趣的工作。
感觉scale问题真的是目标检测的一个关卡,这方面估计还有很多可以做的工作。
