
MoCo Momentum Contrast 工作简介

最近听说 Kaiming 的这个工作非常fancy,就拿来试着读了一下,整理了一下文章的宏观框架,希望可以帮助到粗览这篇文章或刚入门的同学。
Basic Framework
这篇文章中,作者针对图像处理领域的预训练提出了一种非常简单的模型和训练方法:
- 对每一个图片数据,分别将其编码成 query vector 和 key vector
- 在训练过程中,训练目的是提高自己的query vector和key vector的相似度,同时降低自己的query vector和其他图片的key vector的相似度
- 在更新编码网络的过程中,由于需要分别将图片更新成 query vector 和 key vector,作者提出了一种利用相同参数初始化,被称为MoCo的训练方式
Several Points
Signal Space
文章中作者提到了NLP任务中的单词是离散的,因此可以构建单独的词典(dictionary)。而图像处理任务中的数据则分布在高维的连续空间中,没有办法构建图像词典。
这里的词典可以看成是包含了所有基本信息单元的数据结构。在NLP中可以认为词典包含了所有的单词,相对的,在图像空间中的词典就是包含了所有的图片的数据结构。
而词典结构作者认为是无监督学习方法的关键(个人理解:NLP中的Language Model 是通过预测词典中的单词来训练的),NLP任务中的词典是非常自然的,但CV任务中的词典很难说是什么,因此缺乏词典结构阻碍了图像处理领域的无监督学习方法的发展
Dynamic Dictionaries
既然我们没有办法穷举所有的图片,我们就换一种方式来构建我们的图片词典,也就是文章中提出的动态词典。
所谓的动态词典,作者文中说的是The dictionary is dynamic in the sense that the keys are randomly sampled. 这里的Key指的是字典中的元素。字典的作用主要是在训练过程中,作为一个比较或者预测的范围。既然没有办法穷举整个图片的取值,作者在这里就采用了randomly sampling的方式(实际上这里的sample是和mini batch时的sample是一样的)
总结一下就是,动态词典是在训练过程中,随机从所有图片中采样若干张图片,作为本次训练的词典。这是作者提出的一种handle高维连续数据的trick。
Network Structure
深度学习作为特征提取方法的一种,需要神经网络来对数据进行编码,前面所提到的词典并不是一种网络结构。
本文提供的训练方法依赖于两个网络结构:作者分别称之为key encoder和query encoder。这两个网络的功能都是将图片映射到成一个低维度的向量空间中去。
简而言之,无论是key encoder还是query encoder,我们丢进去一张图片,他都能生成一个向量。
至于这两个encoder是怎么设计的,作者并没有作重点阐述,大家可以看paper 3.3. Pretext 去看看Technical details。大家感兴趣也可以试试在复现的时候看看,是否调一调encoder的结构对最后的结果影响不大
Contrastive Loss and Contrastive Learning
我们有了词典和encoder网络以后,要怎么样利用词典来完成我们的训练任务呢?这里作者采用的是Contrastive Learning的方式。
Contrastive Learning的训练目标是降低Contrastive Loss.
对一张图片而言,我们希望Contrastive Loss具有如下属性: 1. 该图片经过key encoder和query encoder编码以后得到的两个向量 k_+, q 尽可能接近 2. 该图片经过query encoder得到的向量 q ,和dictionary中所有其他的图片的经过key encoder编码后得到的向量\{k_i,\ i\in{0,1,...,K}\} 尽可能正交(不接近)
那么对于一张图片而言,定义其contrastive loss(即InfoNCE)为:
\mathcal{L}q = - \log \frac{\exp(q\cdot k+/\tau)}{\sum_{i}^K\exp(q\cdot k_i/\tau)}
其中 \tau 是个超参数
这里作者虽然没说,但考虑到作者采用了mini batch的训练方法,这里训练的目标应该是minimize the expectation of \mathcal{L}_q 。需要注意这里采用了mini batch的训练方法,这对后面 dictionary 的更新规则有启发性的作用
Convergence and Momentum Update
上面基本构建起了训练算法的出发点和宏观框架,现在回到 dictionary 的更新规则上。我们说到这里的dictionary是动态采样的。那么dictionary是怎么采样的呢?作者这里采用了一种基于队列的采样更新规则(为了方便下述MoCo)。此外作者还与另外两种方式做了个对比,分别为end-to-end的方式和memory bank的方式。这三种方式的前提都是我们采用mini batch的训练方法
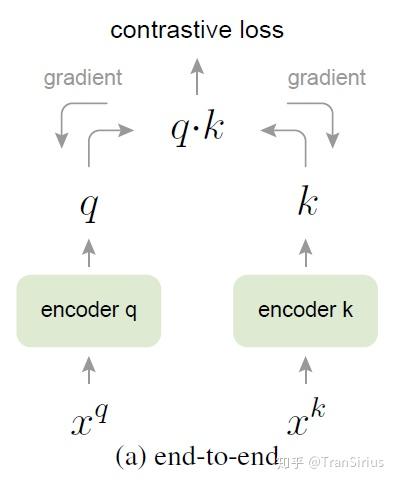
end-to-end
在end-to-end方式下,每一个 batch 的动态字典和这个 batch 下采样出来的数据一样。举个例子来说,每一个 batch 采样10张图片,则每一张图片都和这10张图片算一个contrastive loss。这个batch下的图片,两两互为负样本。
另一方面,这里的 query encoder 和 key encoder 的参数更新是独立的。
这种方式有一个致命的缺陷在于,dynamic dictionary size只能和batch size一样大。然而由于显存限制和计算资源有限,batch size就很难非常大。这种基于mini batch 的方式还需要特殊的encoder网络结构来解决一些收敛性的问题
memory bank
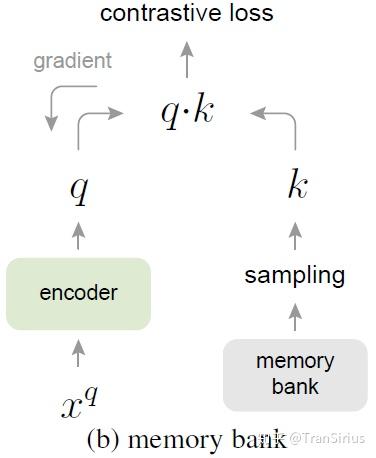
end-to-end问题的核心在于 dynamic dictionary size 和 batch size的耦合。因此,memory bank采用了将 dictionary 保存下来,每一个batch只是去更新它的方式。
memory bank这个银行中存储的是所有训练数据经过 key encoder 编码之后的表示(A memory bank consists of the representations of all samples in the dataset.)。在训练过程中,每一个batch采样出来的数据将重新被 key encoder 编码,替换掉 memory bank 中原来的 key encoding。
在计算每个 batch 的contrastive loss时,都要进行一次 dictionary 的采样。在更新参数时,不会对 key encoder 传播梯度。
需要注意的是,这里的key network和query network是同一个network,具体可以参考18年CVPR的 Unsupervised Feature Learning via Non-Parametric Instance Discrimination


但是这种方法的致命缺陷在于,Memory Bank中储存的 key encoding 有用很早以前的参数的 key encoder编码出来的,这会造成网络参数的不一致
MoCo
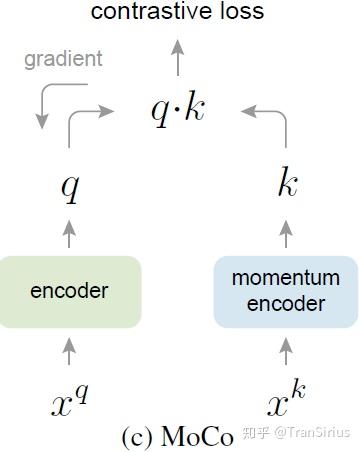
MoCo 采用了时间管理的机制。简而言之,在MoCo中,每一个batch都会淘汰掉 dynamic dictionary中最早被编码的那一批数据,然后把最新采样的数据加进去。这就缓解了 memory bank中,过早sample的数据编码已经不一致的问题。
Training Methods
最后作者提出了一种用query encoder '拖着' key encoder 更新参数的训练方法。即每次梯度传播不向 key encoder 传播,而只更新query encoder的参数。key encoder的参数采用逐步向 query encoder 逼近的方式。具体而言:
\theta_k \leftarrow m \theta_k + (1-m)\theta_q
这里的 \theta 是网络参数, m 是动量系数,是一个超参数。
Experiments and Results
作者首先在简单的classification任务上verify了自己算法的有效性,此外也在一系列CV下游任务上都取得了不错的成绩。具体参见论文第四章本身。
