ICLR2021有什么值得关注的投稿?这些高赞论文先睹为快
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要7分钟
跟随小博主,每天进步一丢丢


【导读】机器学习顶会ICLR2021 deadline已经结束,最后共有3013篇论文提交。ICLR 采用公开评审,可以提前看到这些论文。小编整理了来自Twitter、知乎热议的高赞论文,先睹为快。
ICLR 2021会议网址:
https://openreview.net/group?id=ICLR.cc/2021/Conference

1. An Attention Free Transformer

https://openreview.net/forum?id=pW--cu2FCHY
2. Contrastive Learning with Stronger Augmentations

https://openreview.net/forum?id=KJSC_AsN14
3. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

https://openreview.net/forum?id=YicbFdNTTy
4. A Good Image Generator Is What You Need for High-Resolution Video Synthesis
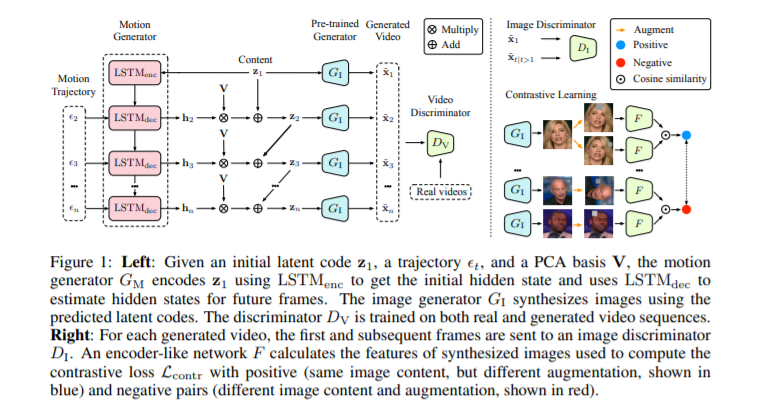
https://openreview.net/pdf?id=6puCSjH3hwA
5. Score-Based Generative Modeling through Stochastic Differential Equations

https://openreview.net/forum?id=PxTIG12RRHS¬eId=PxTIG12RRHS
最后附上周博磊老师的推荐

https://docs.google.com/document/d/1Rk2wQXgSL-9XiEcKlFnsRL6hrfGNWJURufTST2ZEpIM/edit
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! ![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT ![]()
后台回复【南大模式识别】
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
推荐两个专辑给大家: 专辑 | 李宏毅人类语言处理2020笔记 专辑 | NLP论文解读 专辑 | 情感分析
整理不易,还望给个在看!










