
第四范式提出优化NAS算法 速度比DARTS快10倍

作者:Quanming Yao ,Ju Xu,Wei-Wei Tu,Zhanxing Zhu
概述
神经架构搜索(NAS)因其比手工构建的架构能识别出更好的架构而备受关注。近年来,可微分的搜索方法因可以在数天内获得高性能的NAS而成为研究热点。然而,由于超级网的建设,其仍然面临着巨大的计算成本和性能低下的问题。
在本文中,我们提出了一种基于近端迭代(NASP)的高效NAS方法。与以往的工作不同,NASP将搜索过程重新定义为具有离散约束的优化问题和模型复杂度的正则化器。由于新的目标是难以解决的,我们进一步提出了一种高效的算法,由近端启发法进行优化。通过这种方式,NASP不仅比现有的可微分的搜索方法速度快,而且还可以找到更好的体系结构并平衡模型复杂度。
最终,通过不同任务的大量实验表明,NASP在测试精度和计算效率上均能获得更好的性能,在发现更好的模型结构的同时,速度比DARTS等现有技术快10倍以上。此外,NASP消除了操作之间的关联性。
此外,在WWW 2020的论文” Efficient Neural Interaction Functions Search for Collaborative Filtering”中,我们将NASP算法应用到了推荐系统领域,欢迎关注。
- 视频:https://www.tuijianxitong.cn/cn/school/video/26
- PPT:https://www.tuijianxitong.cn/cn/school/openclass/27
- 论文:https://arxiv.org/pdf/1906.12091
- 代码:https://github.com/quanmingyao/SIF
背景介绍
深度网络已经应用到许多应用中,其中,适当的体系结构对于确保良好的性能至关重要。近年来,NAS 因可以找到参数更少、性能更好的网络成为了关注和研究的热点,该方法可取代设计架构的人类专家。
NASNet 是这方面的先驱性工作,它将卷积神经网络(CNN)的设计为一个多步骤决策问题,并用强化学习来解决。然而,由于搜索空间离散且巨大,NASNet 需要数百个 GPU 耗费一个月的时间,才能获得一个令人满意的网络结构。后来,通过观察网络从小到大的良好传输性,NASNetA)提议将网络分割成块,并在块或单元内进行搜索。然后,识别出的单元被用作构建块来组装大型网络。这种两阶段的搜索策略极大地减小了搜索空间的大小,从而使进化算法、贪心算法、强化学习等搜索算法显著加速。尽管减少了搜索空间,但搜索空间仍然是离散的,通常很难有效搜索。最近的研究集中在如何将搜索空间从离散的变为可微分。这种思想的优点在于可微空间可以计算梯度信息,从而加快优化算法的收敛速度。
该思想已经衍生出了各种技术,例如 DARTS 平滑了 Softmax 的设计选择,并训练了一组网络;SNAS 通过平滑抽样方案加强强化学习。NAO 使用自动编码器将搜索空间映射到新的可微空间。


在所有这些工作中(Table 1),最为出色的是DARTS [1],因为它结合了可微分以及小搜索空间两者的优点,实现了单元内的快速梯度下降。然而,其搜索效率和识别体系结构的性能仍然不够令人满意。由于它在搜索过程中保持超级网,从计算的角度来看,所有操作都需要在梯度下降过程中向前和向后传播,而只选择一个操作。从性能的角度来看,操作通常是相互关联的。例如,7x7的卷积滤波器可以作为特例覆盖3x3的滤波器。当更新网络权值时,由DARTS构造的ensemble可能会导致发现劣质的体系结构。此外,DARTS未完成,即最终的结构需要在搜索后重新确定。这会导致搜索的体系结构和最终体系结构之间存在偏差,并可能导致最终体系结构的性能下降。
本次工作的方法
在此次工作中,第四范式提出了基于临近迭代算子算法(Proximal gradient Algorithm [2])的NAS方法(NASP),以提高现有的可微搜索方法的效率和性能。我们给出了一个新的NAS问题的公式和优化算法,它允许在可微空间中搜索,同时保持离散的结构。这样,NASP就不再需要训练一个超级网,从而加快搜索速度,从而产生更优的网络结构。
- 除了以往 NAS 普遍讨论的搜索空间、完备性和模型复杂度之外,该工作确定了一个全新且重要的一个因素,即 NAS 对体系结构的约束;
- 我们将 NAS 描述为一个约束优化问题,保持空间可微,但强制架构在搜索过程中是离散的,即在反向梯度传播的时候尽量维持少量激活的操作。这有助于提高搜索效率并在训练过程中分离不同的操作。正则化器也被引入到新目标中,从而控制网络结构的大小;
- 由于这种离散约束难以优化,且无法应用简单的 DARTS 自适应。因此,第四范式提出了一种由近端迭代衍生的新优化算法,并且消除了 DARTS 所需的昂贵二阶近似,为保证算法的收敛性,我们更进一步进行了理论分析。
- 最后,在设计 CNN 和 RNN 架构时,使用各种基准数据集进行了实验。与最先进的方法相比,提出的 NASP 不仅速度快(比 DARTS 快 10 倍以上),而且可以发现更好的模型结构。实验结果表明,NASP 在测试精度和计算效率上均能获得更好的性能。
具体算法如下:
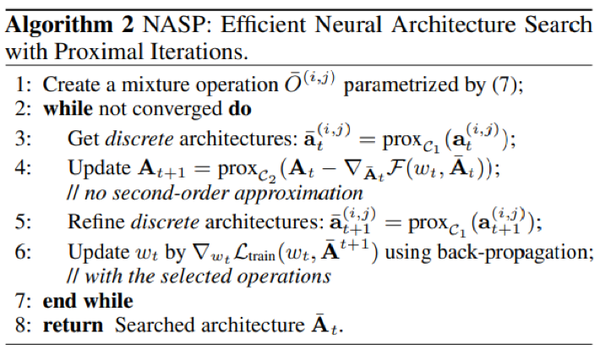

在第三步中,我们利用临近迭代算子产生离散结构;再在第四步中更新连续的结构参数(单步梯度下降,无二阶近似);最后,我们在离散的网络结构下,更新网络权重。
实验结果
该工作利用搜索CNN和RNN结构来进行实验。此次试验使用CIFAR-10、ImageNet、PTB、WT2等四个数据集。
CNN的架构搜索(在 CIFAR-10 上搜索单元)
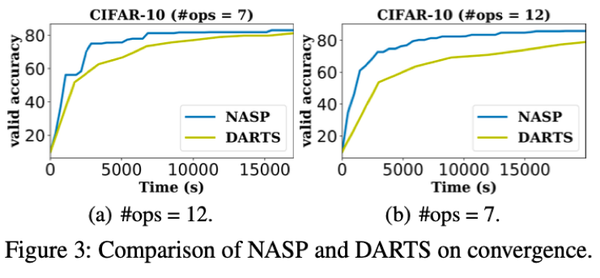
在 CIFAR-10 上搜索架构相同,卷积单元由 N=7 个节点组成,通过对单元进行 8 次叠加获得网络;在搜索过程中,我们训练了一个由 8 个单元叠加的 50 个周期的小网络。这里考虑两个不同的搜索空间。第一个与 DARTS 相同,包含 7 个操作。第二个更大,包含 12 个操作。
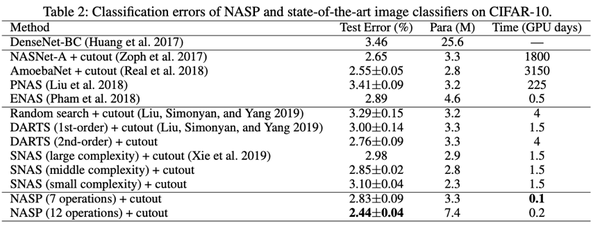

与最新的 NAS 方法相比,在相同的空间(7 次操作)中,NASP 的性能与 DARTS(二阶)相当,比 DARTS(一阶)好得多。在更大的空间(12 个操作)中,NASP 仍然比 DARTS 快很多,测试误差比其他方法更低很多。在以上实验中,研究人员对模型复杂度进行了正则化,我们设置了的η=0。结果显示,模型尺寸随着η的增大而
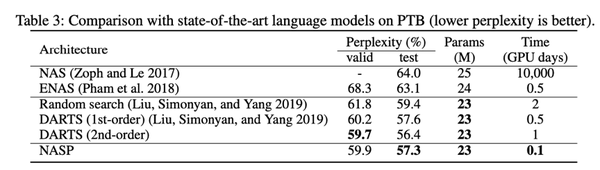
为了探索实验中搜索到的单元在 ImageNet 上的迁移能力,我们将搜索到的单元堆叠了 14 次。值得注意的是,NASP 可以用最先进的方法实现竞争性测试误差。
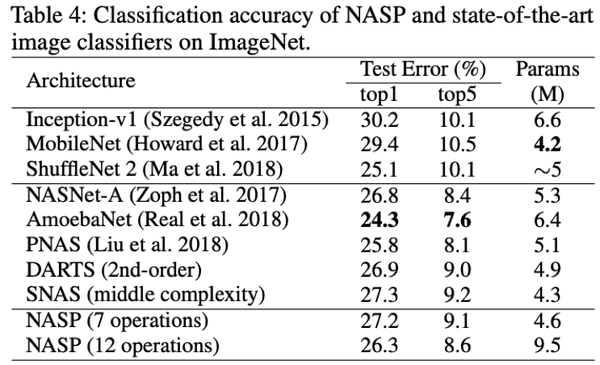

RNN 的架构搜索(在 PTB 上搜索单元)
根据 DARTS 的设置,递归单元由 N=12 个节点组成;第一个中间节点通过线性变换两个输入节点,将结果相加,然后通过 tanh 激活函数得到;第一个中间节点的结果应为由激活函数转换而成。
在搜索过程中,我们训练了一个序列长度为 35 的 50 个阶段的小网络。为了评估在 PTB 上搜索到单元的性能,使用所发现的单元对单层递归网络进行最多 8000 个阶段的训练,直到与批处理大小 64 收敛。实验结果显示,DARTS 的二阶比一阶慢得多,NASP 不仅比 DARTS 快得多,而且可以达到与其他最先进的方法相当的测试性能。

模型简化测试
1. 对比 DARTS
实验给出了更新网络参数(即 w)和架构(即 A)的详细比较。在相同的搜索时间内,NASP 可以获得更高的精度,且 NASP 在相同的精度下花费更少的时间。这进一步验证了 NASP 比 DARTS 效率更高。

2. 与同期工作比较
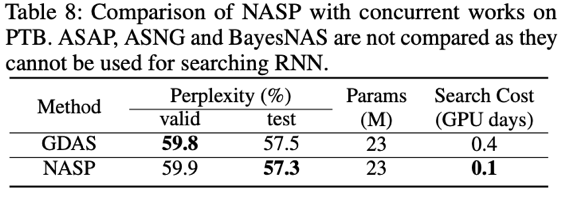
实验中也加入了与同期工作的比较。ASAP 与 BayesNAS 将 NAS 作为一个网络修剪问题,该工作删除了在搜索过程中无效的操作。ASNG 和 GDAS 都对搜索空间进行随机松弛,区别在于 ASNG 使用自然梯度下降进行优化,而 GDAS 使用 Gumbel-Max 技巧进行梯度下降。此次实验将 NASP 与这些工作进行比较,实验表明,NASP 更有效,可在 CNN 任务上提供更好的性能。此外,NASP 还可以应用于 RNN。



参考资料
[1]. Liu, H.; Simonyan, K.; and Yang, Y. DARTS: Differentiable architecture search. In ICLR 2019
[2]. Parikh, N., and Boyd, S. Proximal algorithms. Foundations and Trends in Optimization 2013