
Deeplearning4j技术介绍

Deeplearning 4j概览
Deeplearning4j当前最大、最流行的基于JAVA的深度学习框架,截止目前,社区人数为4900+,拥有11800+颗星,160000+的下载量。Deeplearning4j正式诞生于2013年,在2017年加入Eclipse基金会,由美国的Skymind开源并维护。
- 支持神经网络模型的构建、模型训练和部署
- 能够与现有大数据生态进行无缝衔接(Hadoop、Spark等),也是可以原生态支持分布式模型训练的框架之一
- 支持多线程
- 跨平台(硬件:CUDA GPu,x86,ARM,PowerPC;操作系统:Windows/Mac/Linux/Android)

Deeplearning主要组件
- Deeplearning4j,ScalNet
Jvm和Spark上运行神经网络构建、训练和部署的基础框架库
- ND4J/libND4J
支持CPU/GPU加速的高性能数值计算库,可以说是JVM上的Numpy
- SameDiff
用于符合微分和计算图库
- DataVec
数据处理库,提供采样、过滤、变换等操作
- Arbiter
神经网络超参数搜索和优化库
- RL4J
JVM上的强化学习库
- Model Import
模型导入库,可以导入ONNX,TensorFlow,Keras(Caffe)模型
- Jumpy
ND4J对应python语言API
- Python4j
可以在JVM里运行python脚本语言
下面,我们将对几个主要的组件进行具体介绍。
nd4j


- ND4J中常用的类


- ND4J中的NDArray使用示例
- 创建NDArray对象
Nd4j.zeros(int nRows,int nCols)
Nd4j.create(float [],int int[])
- 获取属性
尺寸:arr.size(i),长度:arr.length(),行:arr.rows()
- 运算(加减乘除...)
arr.add(myDouble);arr.sub(myDouble);arr.mul(myDouble);arr.di v(myDouble);Nd4j.sort(Array,0,true)
- 规约操作
arr.normal(),arr.prod()
- 矩阵操作
arr.transpose();arr.Reshape(...);
Nd4j.toFlattened(arr)
SameDiff
SameDiff是具有自动微分功能的张量计算库8,其自动微分方法是基于静态图的方法,提供神经网络运算中更为底层的接口,主要用于自定义神经网络拓扑结构。
使用示例如下:
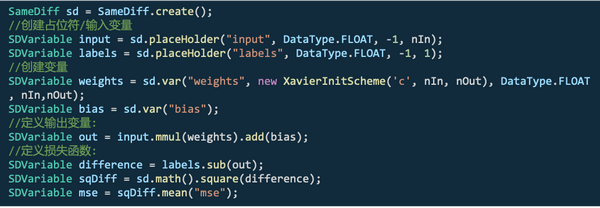
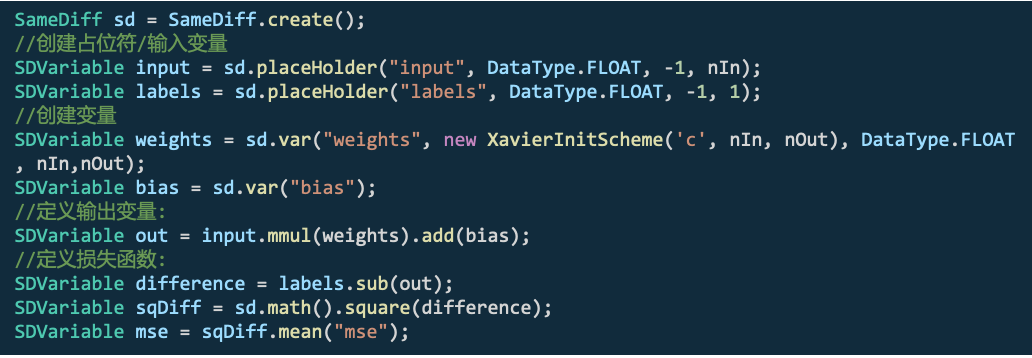
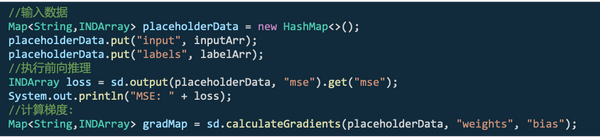

另外,SameDiff支持导入Tensorflow冻结模型格式的.pd(protobuf)模型。对ONNX、TensorFlow SaveModel和Keras模型的导入正在完善中。我们可以简单的认为SameDiff和DL4J的关系类似于Tensorflow和Keras。
Datavec
DataVec是一个用于机器学习ETL(提取、转换、加载)操作的库,目的是将原始数据转化为可用的向量格式,从而将其输入到机器学习算法中。
整体流程如下:
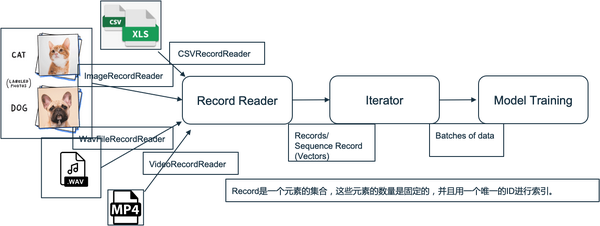
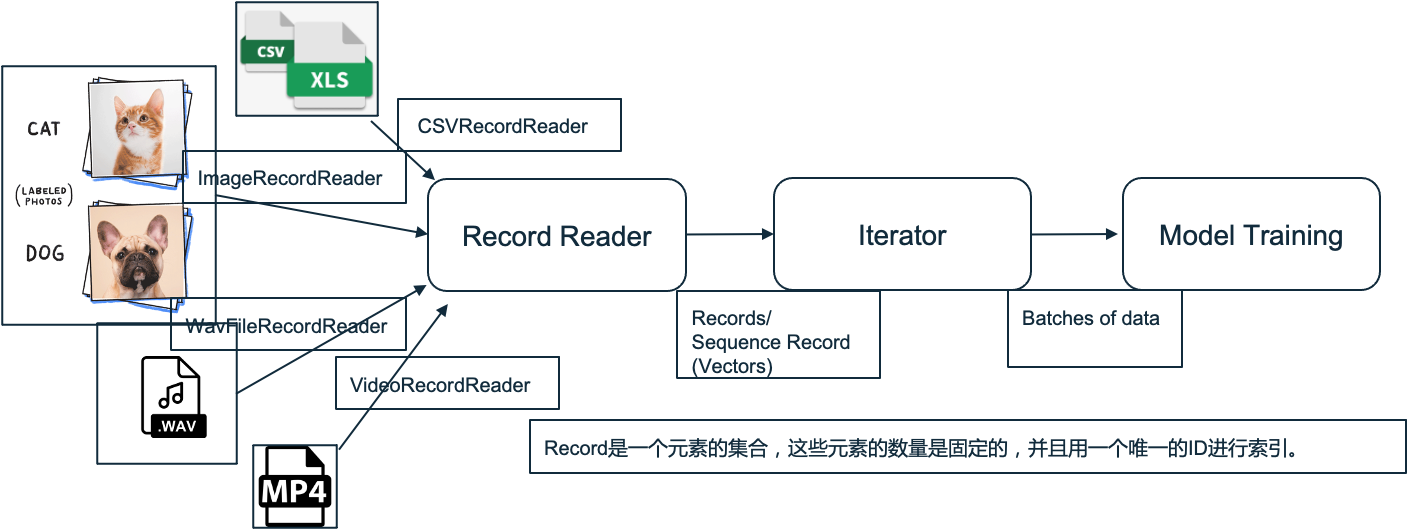
同时,DataVec也支持所有主要类型的输入(CSV、文本、图像、音频、视频和数据库)
整体流程如下:
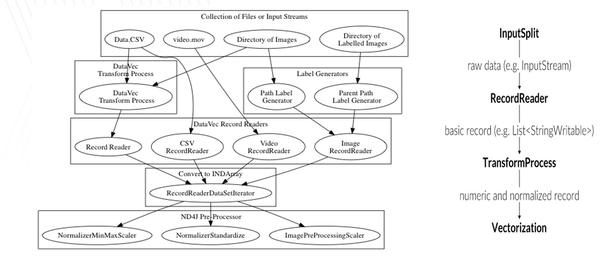

除了明显提供经典数据格式的读取器,DataVec还提供了一个接口。因此,如果你想摄取特定的自定义数据,你就不必构建整个管道。你只需要编写第一步就可以了。例如,如果你通过API描述你的数据如何符合符合接口的通用格式,DataVec将为每条记录返回一个可写列表。你会在相应的模块中找到更多关于API的细节。你可以用DataVec做的另一件事是数据清洗。比方说,你不是拥有干净的、随时可以使用的数据,而是从不同形式或不同来源的数据开始。您可能需要进行采样、过滤,或者在现实世界中准备数据所需的几个令人难以置信的混乱的ETL任务。DataVec提供了过滤器和转换,帮助你策划、准备和处理数据。它利用Apache Spark来大规模地完成这些任务。最后,DataVec为您的列式数据跟踪一个模式,跨越所有转换。该模式会通过探测进行主动检查,如果您的数据与模式不匹配,DataVec会引发异常。您也可以指定过滤器:例如,您可以将正则表达式附加到类型为String的输入列中,DataVec将只保留符合该过滤器的数据。
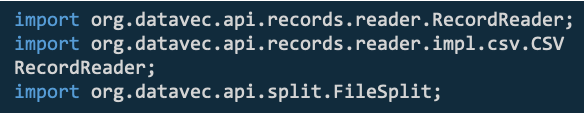
DataVec使用示例:

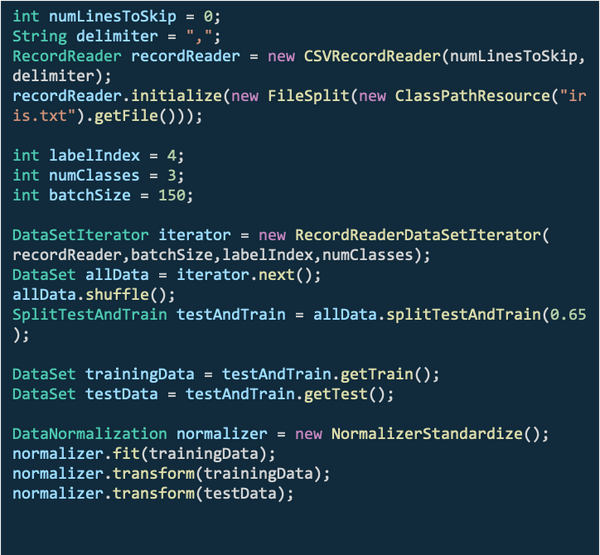
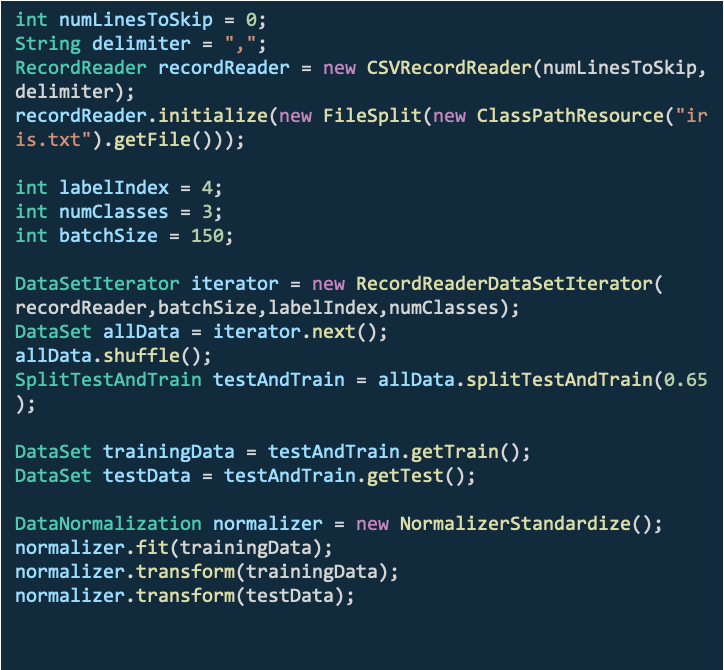
Deeplearning4j
神经网络高层API库,用于构建具有各种层的MultiLayerNetworks和ComputationGraphs,支持从其他框架导入模型和在Apache Spark上进行分布式训练。


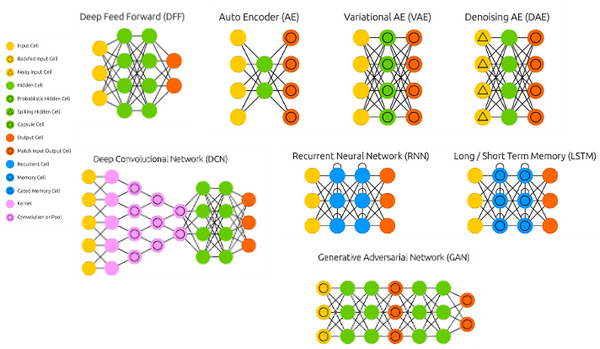
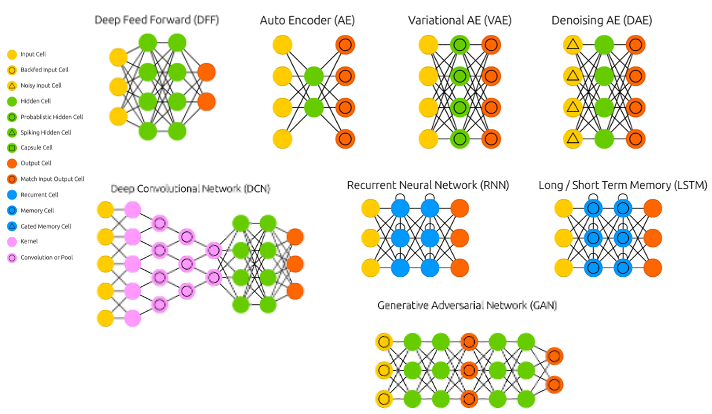
Deeplearning主要类
Layer
● Feedforward Layers
● Output Layers
● Convolutional Layers
● Recurrent Layers
● Unsupervised Layers
● …


Configuration
● Activation Functions
● Weight Initialization
● Updaters (Optimizers)
● Learning Rate Schedules
● Regularization
○ L1/L2 regularization
○ Dropout
○ Weight Noise
○ Constraints


Deeplearing示例:




Deeplearning技术栈与工作流


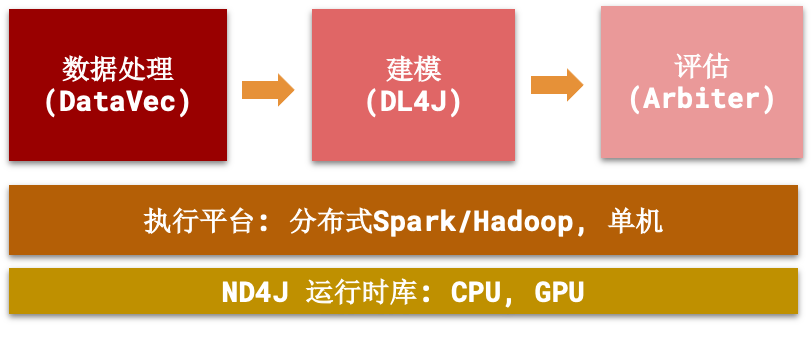
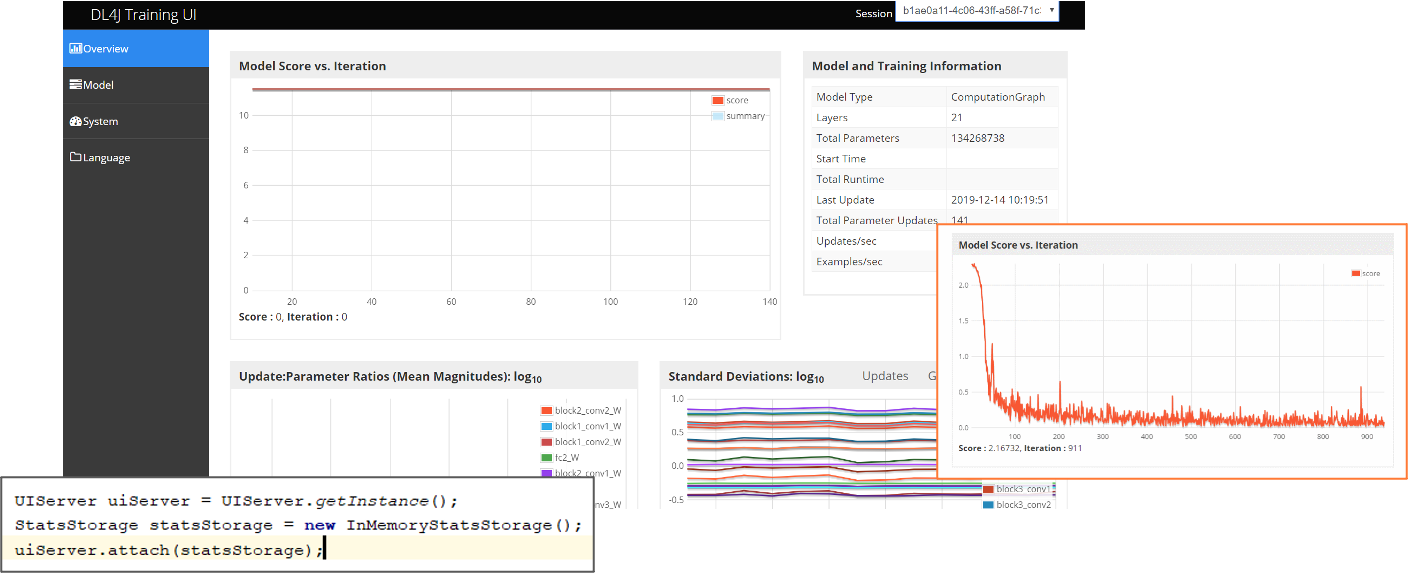
Deeplearning可视化界面:
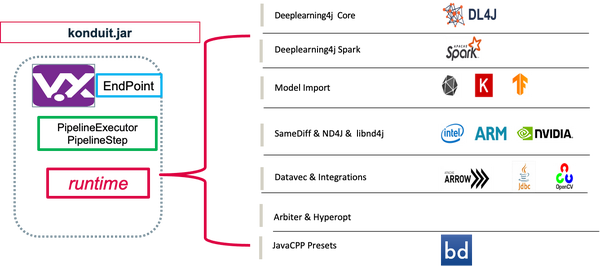
Konduit
Konduit 是一个专注于将机器学习工作流部署到生产环境中的服务系统和框架,核心概念是PipelineStep(工作流步骤 )。
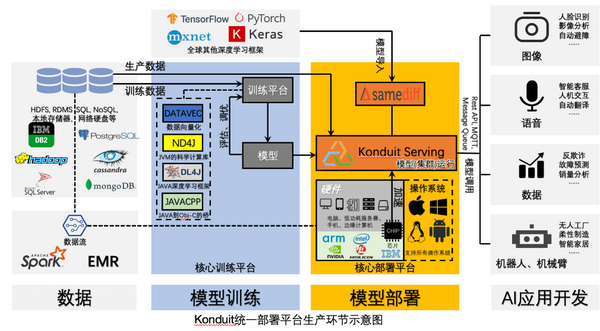

Konduit-旨在使模型开发和部署更加高效和易用
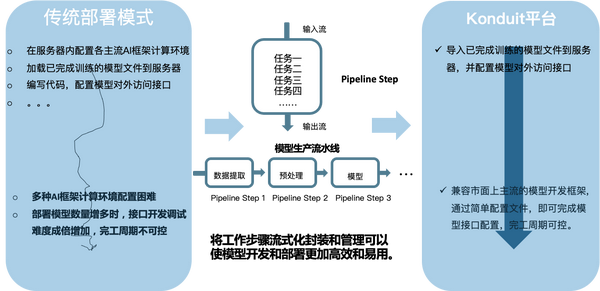
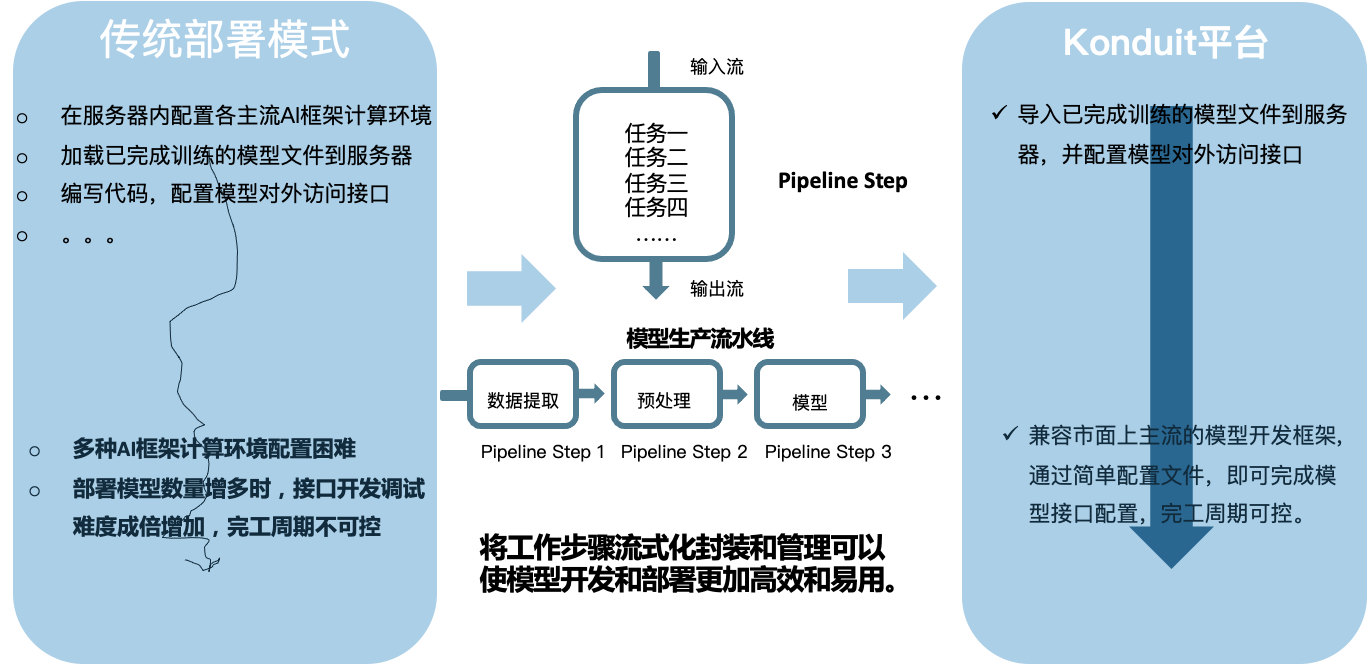
Konduit与其他部署方式的比较
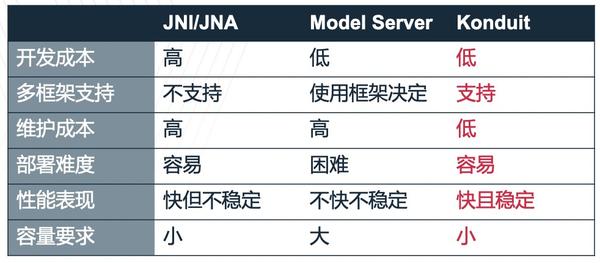

另外,Konduit支持多种输入和输出数据格式,如:numpy、Json、ND4J 图片、ARROW。
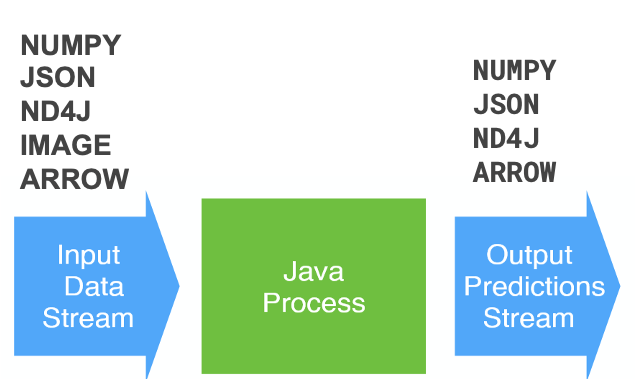
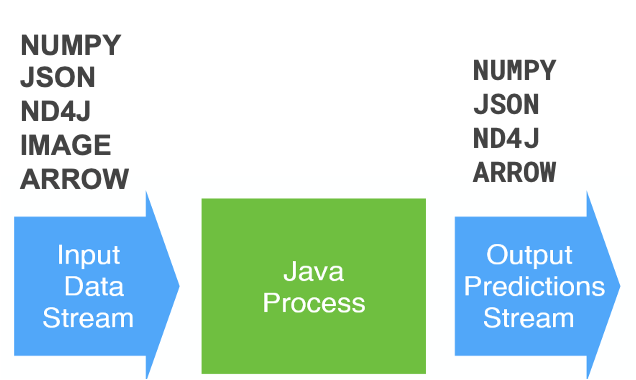
Konduit工作流水线步骤(Pipeline steps)


Konduit框架结构

使用Konduit部署MNIST模型示例
一:将工作流水线参数写入配置文件
1、输入、输出数据类型和格式
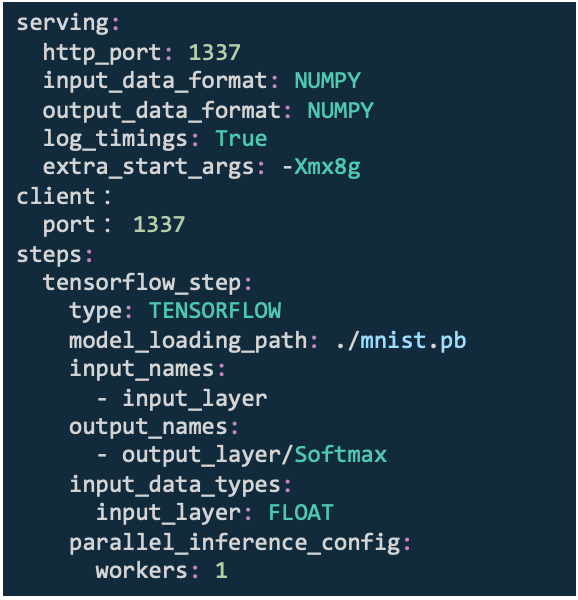
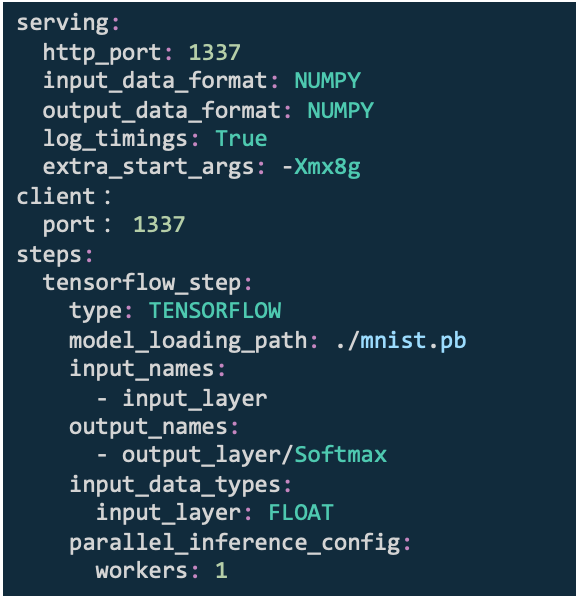
2、流水线步骤
二:启动konduit服务
命令行方式:konduit serve --config tf_mnist.yaml -id server


三:Konduit可视化监控
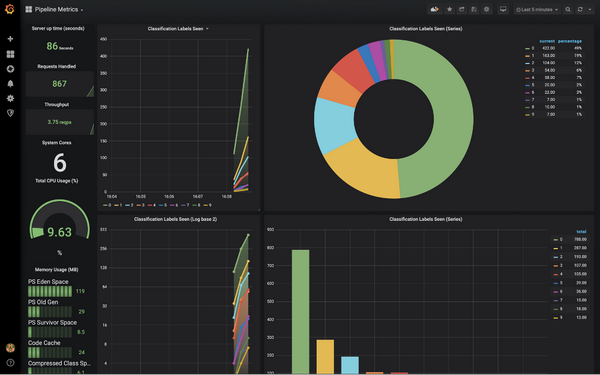
● Konduit推行的现代化的可视化标准,用于监控在服务器端从GPU到推理时段的一切行为。
● Konduit支持可视化应用程序,如Grafana (该程序支持数据可视化领域的Prometheus 标准)。