《Inner Attention based Recurrent Neural Networks for Answer Selection》阅读笔记

转载请注明出处:
西土城的搬砖日常原文链接:Inner Attention based Recurrent Neural Networks for Answer Selection
来源:ACL2016
问题介绍:答案选择(Answer Selection)
答案选择任务就是根据问题,从候选答案中找出正确答案,这里的答案一般都是长句,做答案选择任务常用的数据集有InsuranceQA,TrecQA,WikiQA等。不同的数据集,每个问题对应的正确答案的个数也不相同,因此可以用不同的评价指标去进行评价,常用的评价指标有MAP,MRR,Accuracy。
主要方法:
基于attention的RNN网络在做句子表示的时候取得了非常好的效果,这篇论文的主要工作就是深入地分析了RNN中的attention机制,同时提出了三种新的带attention的RNN模型,作者将其称为Inner Attention based RNN(IARNN),与传统的在RNN隐层输出部分加attention不同,作者在RNN的输入端部分加attention,实验结果显示,这种新的RNN模型在答案选择任务上取得了state-of-art的效果。下面详细的介绍一下。
1.传统带attention的RNN模型
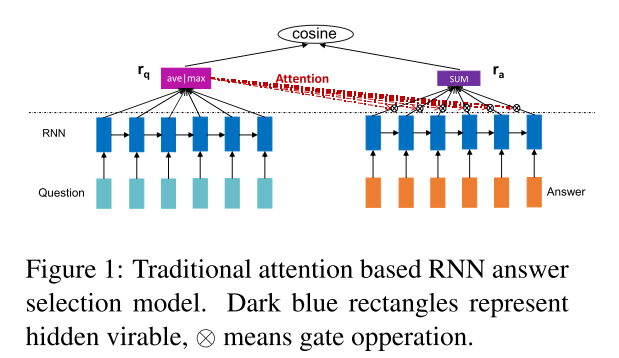

先是计算问题的向量表示,Q=\left\{ q_{1},q_{2},q_{3},...,q_{n} \right\} 表示问题,每个q代表问题中的一个单词:
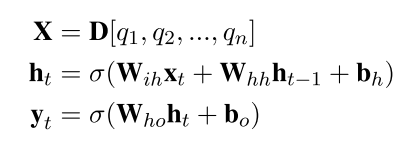
计算答案的向量表示时需要用r_{q}加attention,具体公式如下:
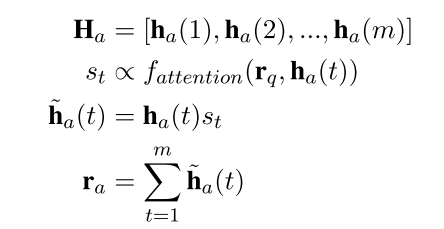

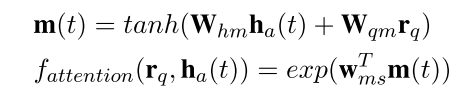

通过加attention,能够使得与问题无关的隐层状态h在最终的表示中发挥更小的作用,也即强调与问题有关的部分,这里将这种attention方式称为Outer Attention based RNN(OARNN)。
但是RNN每个时间步t的隐层状态包含了从开始到这个时间步t的所有信息,因此越靠近句子尾部的状态能够包含更多的句子信息,因此也更有可能被选择,这部分隐层状态对应的attention值也会更大,这就会造成attention的偏移,因为答案中与问题相关的部分不一定都在句子的尾部,可能在句子的任意位置。后面会对这种attention偏移问题做一个更具体的分析。
2.Inner Attention based Recurrent Neural Networks(IARNN)
为了解决attention的偏移问题,这篇论文提出了在学习得到句子表示之前进行attention操作,即Attenttion before representation。作者一共提出了三种IARNN结构。
1)IARNN-WORD
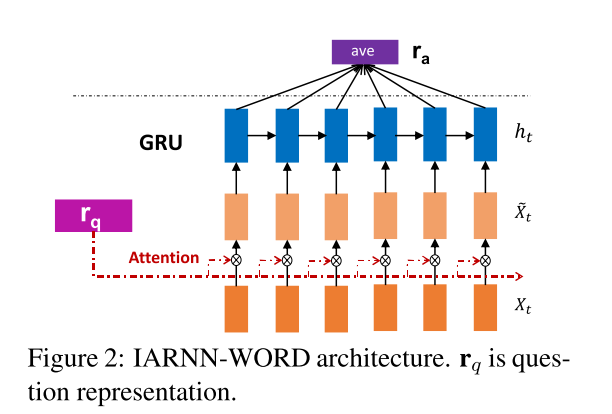

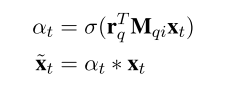
这篇论文用GRU代替常用的LSTM作为RNN的一个结构单元。
GRU的具体公式如下:
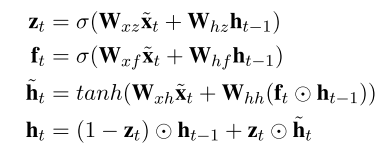
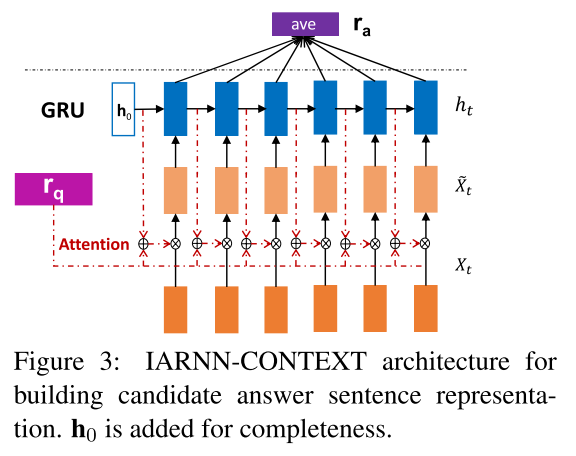
2)IARNN-CONTEXT

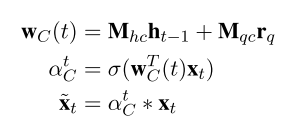
3)IARNN-GATE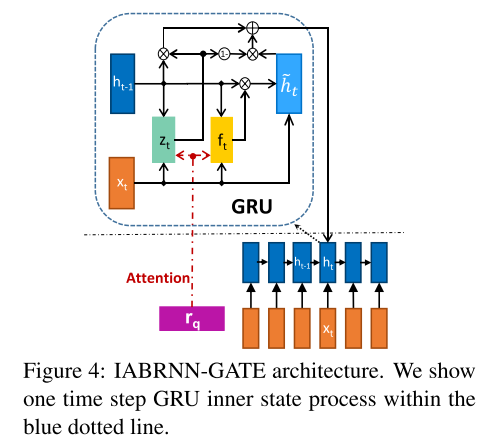

受到LSTM结构在解决RNN的梯度爆炸问题时所采用方法的启发,作者提出了直接将attention信息加入到GRU的每个门函数中,因为这些内部的门函数控制了隐层状态的信息传递,所以直接将attention信息加入到这些门函数中,去影响隐层的状态。具体公式如下: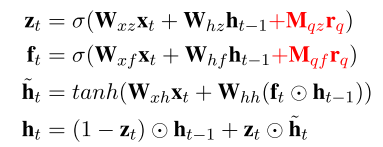
红色的部分就是新加入的attention信息,M_{qz},M_{qf}就是需要学习的attention权值矩阵。
4)IARNN-OCCAM
IARNN-WORD和IARNN-CONTEXT对每个词计算了attention,但是没有考虑整体的权重,因此需要引入一个正则项,但由于不同类型的问题,它们对应答案中包含的与问题有关的词的个数是不同的,例如When和Who对应答案中相关的词更少,而Why和How对应答案中与问题相关的词更多。直接用超参数来控制这个正则项就不大好了,因此这里也利用网络去学习这个参数。具体公式如下:
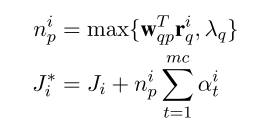
因为IARNN-GATE将计算attention的部分放在了门函数中,因此对IARNN-GATE不加这个正则项。
实验结果:
1.Quantify Traditional Attention based Model Bias Problem
第一个实验是用来验证传统的attention方法带来的权值偏移问题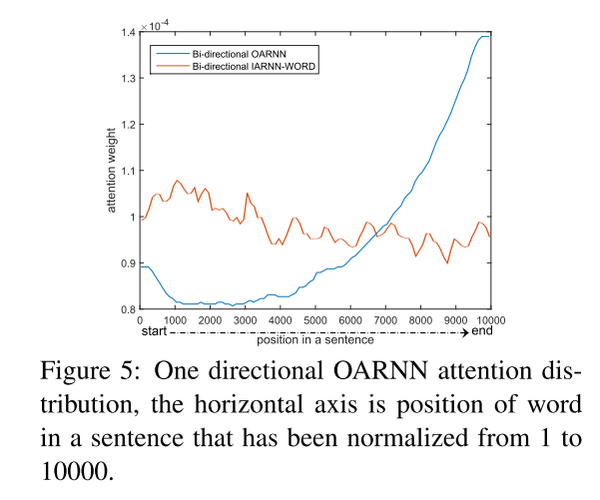

图五显示的是单向RNN的attention权值偏移问题,蓝色的线是传统的attention,红色的线是IARNN-WORD,可以看到,由于单向rnn的信息是从前往后传递的,所以靠近句尾的attention权值比较大。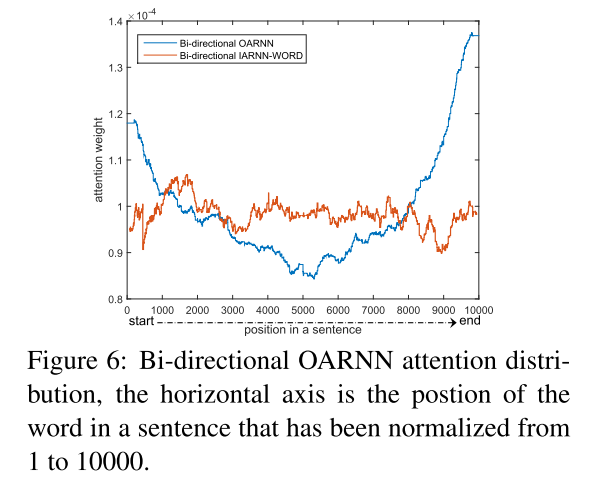

图六显示的是双向rnn的attention权值的分布,可以看到头尾两端的attention权值比较大。
2.Answer selection
作者在三个答案选择数据集上进行了实验:WikiQA,InsuranceQA,TREC-QA
三个数据集都使用了两个模型当baseline,一个是GRU,即用不带attention的GRU-RNN分别对问题和答案进行建模,另一个是OARNN,即带传统attention的GRU-RNN。
1)WikiQA
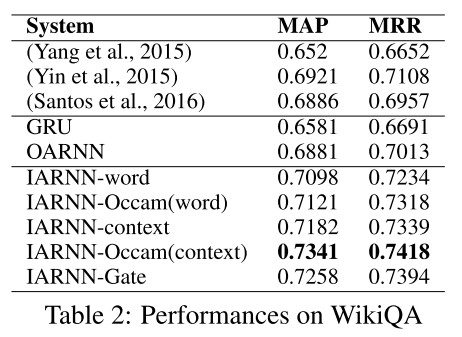

在wikiqa数据集上,作者还比较了另外三个模型,分别是:
(i)(Yang 2015)带average pooling的CNN模型
(ii)(Yin 2015)问题和答案间的interactive attention的CNN模型
(iii)(Santos 2016)在得到句子表示之后构建attention矩阵的CNN模型
从实验结果可以看到,带occam正则项的IARNN-context模型效果最好。
2)InsuranceQA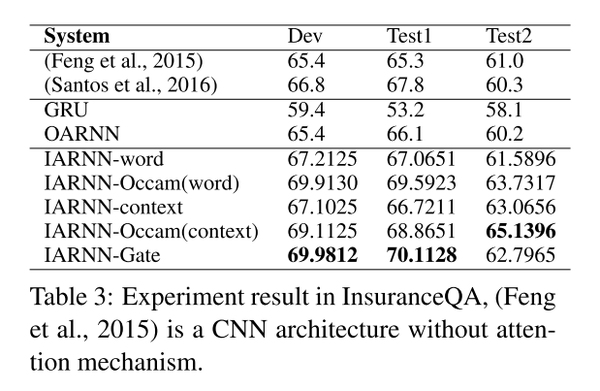

因为insuranceqa数据集的每个问题只有一个正确答案,所以这里用准确率来评价。在计算问题和答案的相似度时,用(Feng 2015)提出的GESD来进行计算,具体公式如下:
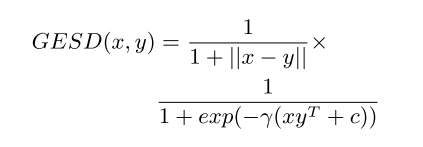

可以看到,几种IARNN的效果比baseline结果都要好,其中IARNN-Gate在test1上的效果最好,IARNN-Occam(context)在test2上的效果最好。
3)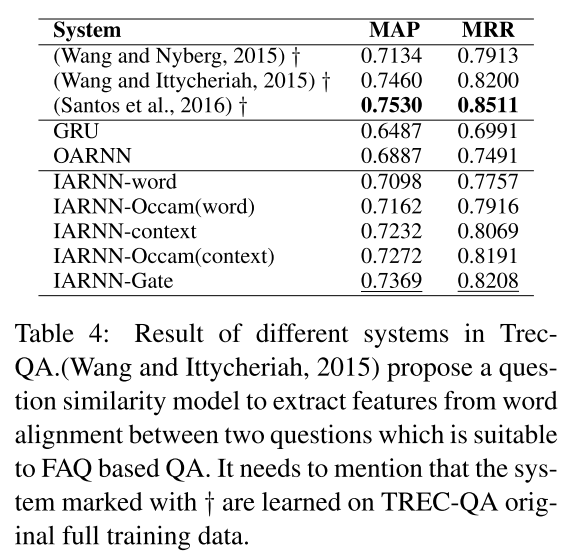

在训练模型时,这篇论文没有用全量的TREC-QA的数据集,而是用经过人工编辑的一个比较小的数据集。虽然在实验结果上,IARNN的效果不是最好的,但是比GRU和OARNN两个baseline还是有提升的。
简评:
这篇论文针对attention值的偏移现象,提出了IARNN,即在进行RNN的操作之前对相关句子加attention,这样可以防止经过rnn之后,越靠后的部分包含更多的信息量,因而在学习attention值的时候,这部分的attention值要更大,造成attention值的偏移。作者提出了三种IARNN模型,一种直接对输入词加attention的IARNN-WORD,一种带上下文信息的IARNN-CONTEXT模型,还有一种直接在RNN的结构单元中加入attention信息的IARNN-GATE模型。
从实验结果中我们可以看到,IARNN的效果要比OARNN效果要好,如下图:


在作者提出的三个IARNN模型中,IARNN-GATE模型效果最好,因为它将attention值放在了RNN的门函数中,通过RNN的门函数能够更好地控制attention值的传递。 另外两个模型中,IARNN-WORD模型效果不如IARNN-CONTEXT,如下图:


除此之外,作者提出的对attention值加正则,也在一些类型的问题上取得了更好的效果,例如WikiQA和InsuranceQA,因为这两个数据集的答案比较长,包含更多的冗余信息。从问题的类型上看,如下图:
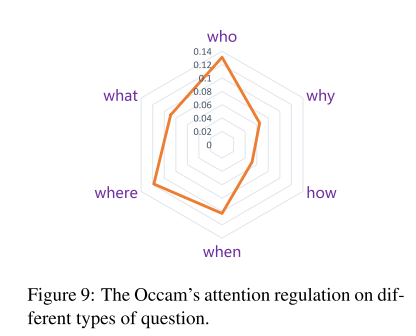
这篇论文从attention值的偏移现象入手,提出了IARNN模型,从结果上来看取得了很好的效果,而且也具有一定的可解释性,对于其他用到attention结构的模型有一定的借鉴作用,另外作者提出的将attention值放到GRU的门函数中进行传递的IARNN-GATE模型,也是一种很好的学习attention值的方法,作者也提到,是否可以另外加入一个门函数用来计算attention值,也许能够更好地利用到句子的上下文信息,从而学习到更好的attention值。
