将相关滤波跟踪算法的速度做到极致


相关滤波类方法从一开始能被我盯上,就是因为速度比较快,不管哪个CV算法,速度都是重要的指标之一,tracking问题尤甚,工业应用永远把速度排在性能之前,学术论文速度快永远是tracker的亮点之一。
速度测试:以前文章介绍了很多state of the art的相关滤波类目标跟踪算法,而且我都会着重强调每个算法的速度怎么样,这里紧接着上一篇,在OTB-2015上将以往介绍的所有real-time tracker跑一下,一起比比看,包括以下几个算法:
- CSK和DCF, KCF:João F. Henriques,原始MATLAB代码,CSK是gray+gaussian +1padding, DCF是HOG+linear +1.5padding, KCF是HOG+gaussian +1.5padding;
- CN和CN2:Coloring Visual Tracking ,原始MATLAB代码,CN是未压缩10维CN+1维gray, CN2是压缩后2维CN特征+1维gray;
- DSST和fDSST:Accurate scale estimation for visual tracking,原始MATLAB代码,默认参数;
- SAMF:ihpdep/samf,原始MATLAB代码,为了加速将多尺度检测scale detection的尺度数量number_of_scales适当减少了;
- LCT:chaoma99/lct-tracker,原始MATLAB代码,默认配置,注意原始代码返回的positions没有尺度,害我跑了两遍 ~;
- CFLB:Correlation Filters with Limited Boundaries,封装了原始MATLAB代码,默认配置;
- DAT:foolwood/DAT,C++版本的实现,没有尺度自适应但速度快很多(又是foolwood,快去关注他的GitHub),注意这个不是相关滤波类算法但Staple中用到也就放在这里了;
- SRDCF:Learning Spatially Regularized Correlation Filters for Visual Tracking,原始旧版MATLAB代码,为了加速将多尺度检测scale detection的尺度数量number_of_scales适当减少了。本来打算用最新ECO代码里面的新版SRDCF(\runfiles\SRDCF_settings.m, 其实说是HC特征的C-COT更合适),可惜速度太慢了,跑了一天一夜还是没跑完就放弃了,改用旧版没有Adaptive decontamination of the training set 和 continuous convolution operators的代码;
- Staple:Staple tracker,原始MATLAB代码,默认配置;
- STAPLE+CA:Context-Aware Correlation Filter Tracking,原始MATLAB代码,仅选了Staple作为baseline的版本,默认配置;
- ECO-HC:martin-danelljan/ECO,原始MATLAB代码,最新版代码默认参数配置,仅选了HC版本,特征是HOG+CN+IC;
- fast_DCF和fastest_DCF:我自己优化DCF的两个版本算法,fastDCF主要是算法方面的优化,fastestDCF做了工程级代码优化,两个版本都是基于OpenCV的C++实现,与前面所有MATLAB算法一样用的是Piotr's Matlab Toolbox中SSE2优化,没有汇编优化,没有多核多线程,更没有GPU;
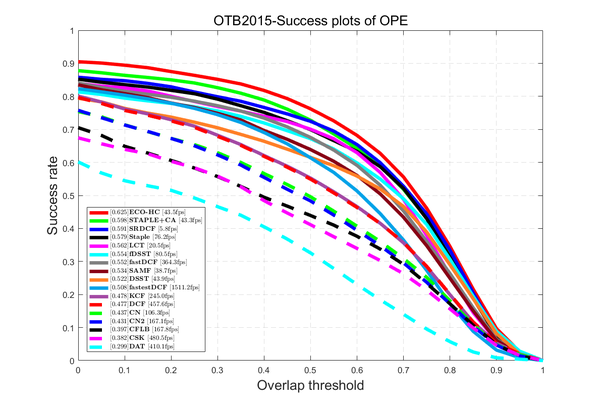
一共17个算法,基本覆盖了近几年CVPR\ICCV\ECCV和TPAMI中的所有开源代码的real-time tracker,OPE方式跑OTB-2015的所有100个序列,所有灰度序列都看做3通道相等的彩色序列,电脑配置PC:Inter i3-6100 CPU @ 3.70GHz, 8GB,64位,没有GPU,软件:MATLAB R2016a和VS2015,结果如下:

再补充几个论文数值作为参考:
Struck 0.460 & 20fps,TLD 0.425 & 30fps,OAB 0.365 & 22fps;
BACF 0.630 & 35fps, CSR-DCF 0.587 & 13fps,LMCF 0.568 & 80fps;
结果分析:总体情况就是这样,SAMF是14年的性能baseline,SRDCF是15年的性能baseline,CSK、DAT(c++)和DCF都能到400fps以上,从CSK开始速度越来越慢,LCT和SRDCF比较慢,fDSST和Staple接近80fps非常优秀,2017`CVPR的ECO-HC和STPALE+CA都在43fps。
分析几点:
- 从CN到CN2做了特征压缩,performance下降1.37%,fps上升57.20%,这个自适应压缩非常有效;
- 从DCF到KCF多了Gaussian-kernel,performance上升0.21%,fps下降46.46%,kernel-trick虽然有用但影响较小,如果注重速度可以摒弃,如果追求极限性能可以用;
- 从DSST到fDSST做了特征压缩和scale filter加速,performance上升6.13%,fps上升83.37%,不用惊讶,fDSST在OTB-2013上调参了才会这么高,在VOT2014上还是比DSST差一点的,但也说明加速策略非常有效,论文是2017`TPAMI;
- 从Staple到STAPLE+CA加入Context-Aware约束项,performance上升3.28%,fps下降43.18%,说明约束项有效,但牺牲了大量fps;
- 从SRDCF到ECO-HC,performance上升5.75%,fps上升650%,相信你的眼睛你没看错,就是650%,从SRDCF到SRDCFdecon加入Adaptive decontamination of the training set慢了很多;再到C-COT-HC加入continuous convolution operators又慢了很多,但Conjugate Gradient替换Gauss-Seidel又有一点加速;到今年CVPR的ECO从模型大小、样本集大小和更新策略三个方便加速,深度特征版本的ECO比C-COT快了20倍但我不关心,我关心的是ECO-HC比C-COT-HC快了6倍(fps+600%),惊呆了!而且performance是上升的,再次惊呆了! (公平起见这里应该比较ECO中的newer version of SRDCF和ECO-HC,但新版SRDCF实在太慢了,等了一天一夜才跑了30个序列,OMG!!!)
- 从fastDCF到fastestDCF做工程加速且以性能换速度,performance下降7.97%,fps上升315%,我的两个算法除了速度还行( 364fps & 1511fps ),性能都是中等水平不值一提,而且这个提升比例与ECO-HC差太多了,我做算法加速其实也参考了包括ECO-HC在内的很多最新论文,可惜还是不及大神们的功力,效果到我这里打对折还算好的。(本来打算在OTB-2015上调参的,后来想想100个序列挺累的,而且我又不写论文,何必呢。。然后果断放弃了)
注意:performance越高提升难度越大,所以STAPLE+CA和ECO-HC的提升都挺大,此外,CFLB和BACF大家自己对比,LCT和LMCF比较像也可以对比分析。
以上内容我想说什么呢?当然是向MD大神致敬了,因为接下来将要介绍MD大神的三篇论文,分别是:
从CN到CN2 -> fps上升57.20%
从DSST到fDSST -> fps上升83.37%
从C-COT-HC到ECO-HC -> fps上升600%
要在这里点题了:将相关滤波跟踪算法的速度做到极致。
-------------------------------------------丑陋的分割线------------------------------------------
看过我以前文章的同学都应该记得,影响相关滤波类跟踪算法速度的关键因素是三维。。当然是特征的三维,在介绍KCF的时候分析过,对于三维是m*n*d的特征,算法的复杂度是 O(d*m*n*log(m*n) ),m*n是特征的分辨率,d是特征通道数,算法加速的有效方法之一是降低特征的三维,但降低三维会大幅影响算法的性能,所以难点是如何在保证算法performance的情况下降维;另一种方法是算法的简化或优化,适合SRDCF这种比较复杂的算法。
CN2:
- Danelljan M, Shahbaz Khan F, Felsberg M, et al. Adaptive color attributes for real-time visual tracking [C]// CVPR, 2014.
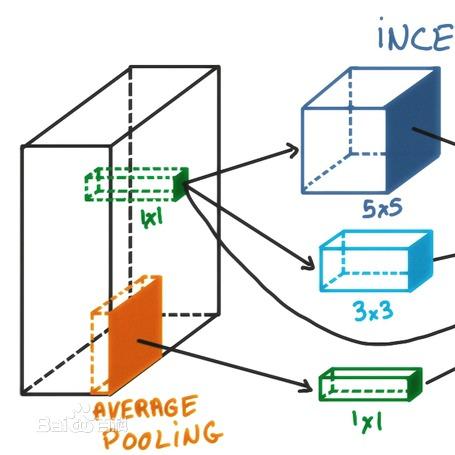
在CN中提出了非常重要的多通道颜色特征Color Names,用于CSK框架取得非常好得效果,这里我们关注加速算法CN2,通过PCA方法的自适应降维,特征通道数量从10下降到2,平滑约束项增加跨越不同特征子空间时的代价,具体做法就是PCA中的协方差矩阵线性更新防止降维矩阵变化太大。流程图如下,Bp是降维的投影矩阵,Qp是协方差矩阵,注意Qp是线性加权更新的:

PCA是最常用最简单的无监督降维方法,核心计算量是协方差矩阵SVD分解,这里协方差矩阵线性插值更新,是为了防止目标颜色剧变,而相关滤波器跟不上剧变情况就会跟丢,部分也是因为kernel-trick的存在。通过PCA降维,CN特征从m*n*10自适应降维到m*n*2,大幅提升算法速度,实验也表明performance下降不明显。
fDSST:
- Danelljan M, Hager G, Khan F S, et al. Discriminative Scale Space Tracking [J]. IEEE TPAMI, 2017.


既然CN特征可以降维,那为什么不试试对通道更多的HOG特征降维呢?DSST本来就是对尺度自适应问题的快速解决方案(支持33个尺度还比SAMF快很多),在fDSST中MD大神又对DSST进行加速:
- 平移滤波器:PCA方法将平移滤波器的HOG特征从31通道降维到18通道,这一步骤与上面的CN特征类似,直接用PCA进行降维,作者提到由于这里用了线性核,所以不需要CN中所用的平滑子空间约束,更加简单粗暴。由于HOG特征天然会降低响应分辨率(cell_size=4),这里也采用简单粗暴的方法,将响应图的分辨率上采样到原始图像分辨率,也就是响应图插值以提高检测精度,方法是三角插值,等价于频谱添0,方法更加简单粗暴,但这一步会增加算法复杂度,而且方法太简单也必然效果较差。
- 尺度滤波器:QR方法将尺度滤波器的HOG特征(二特征,没有循环移位)~1000*17降维到17*17,由于自相关矩阵维度较大影响速度,为了效率这里没有用PCA而是QR分解。多尺度数量是17(DSST中的一半),响应图是1*17,这里也通过插值方法将尺度数量从17插值到33以获得更精确的尺度定位。
总结:两处都采用了无监督的特征降维(PCA和QR),都将做了响应插值以提高检测精度(三角插值)。
这个加速版的fDSST在OTB-2013上大幅超越了DSST和SAMF,而且速度比DSST快了一倍,但在VOT2014还是略低于DSST,当然这也足够给力了。
ECO-HC:
- Danelljan M, Bhat G, Khan F S, et al. ECO: Efficient Convolution Operators for Tracking [C]// CVPR, 2017.
ECO是C-COT的加速版,从模型大小、样本集大小和更新策略三个方便加速,速度比C-COT提升了20倍,加量还减价,在VOT2016数据库上EAO提升了13.3%,当然最厉害的还是hand-crafted features版本的ECO-HC有60FPS,接下来分别看看这三步。
第一减少模型参数,既然CN特征和HOG特征都能降维,那卷积特征是不是也可以试试?这就是ECO中的加速第一步,也是最关键的一步,Factorized Convolution Operator分解卷积操作,效果类似PCA,但Conv. Feat.与前面的CN和HOG又不一样:
- CNN特征维度过于庞大,在C-COT中是96+512=608通道,需要降很多很多维才能保证速度,而无监督降维如果太多会直接影响效果(对比通用方法 - 取特征值的95%以上的维度,保留信息量);
- 虽然CNN特征迁移能力比较强,但这并不是针对跟踪问题专门训练的特征,对跟踪问题有用的信息隐藏在大量CNN激活值中,如果简单的无监督降维,可能会过滤掉那些虽然不显著,但对跟踪问题有效的特征信息。当然HOG和CN特征也有同样的问题。
怎么办呢?专门训练tracking-aware的CNN特征? 或者去tracking dataset上fine-turn? MD大神告诉我们不需要那么麻烦,那样还有过拟合的风险,all we need just a Supervised PCA, 有监督降维:
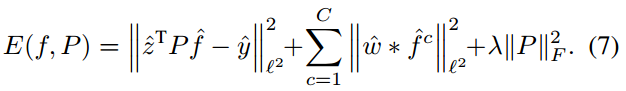

P就是那个降维矩阵,放在目标函数中优化得到,具体求解比较复杂看论文吧,用PCA作为P的初始值去迭代优化,采用Gauss-Newton和Conjugate Gradient方法。但每帧都迭代优化降维矩阵速度反而会更慢,大神告诉我们仅在第一帧优化这个降维矩阵就可以了,第一帧优化完成后这个降维矩阵就是固定的,后续帧都直接用。Factorized Convolution Operator减少了80%的卷积特征还能略微提升性能,HC版本从31+11降维到10+3速度提升非常明显。至于为什么降维了还能提升效果,论文中说参数太多容易过拟合,也可能是判别力较低或者无用的通道响应图会成为噪声,淹没较高判别力的通道响应图。

第二减少样本数量,这个是针对Adaptive decontamination of the training set的加速,C-COT中要保存400个样本,但视频相邻帧之间的相似性非常高,存在大量相似的冗余样本,而且每次更新都要用样本集中所有样本做优化,速度非常慢。ECO中改为紧凑的生成样本空间模型compact generative mode,采用Gaussian Mixture Model (GMM)合并相似样本,建立更具代表性和多样性的样本集,需要保存和优化的样本集数量降到C-COT的1/8。用特征距离衡量两个样本的相似程度,样本合并方法是两个样本特征的权值相加,样本特征按照权值加权合并。

第三改变更新策略,以前CF方法都是每帧更新,这种过更新不仅慢,而且会导致模型对最近几帧严重过拟合,对遮挡、变形和平面外旋转等突然变化过度敏感,但对大多数方法都是无可奈何的,因为如KCF等方法不保存样本,这一帧不更新就再也没机会了。
但ECO保存了所有样本的代表性样本集,所以完全没有必要每帧都更新,这里采用了sparser updating scheme(稀疏更新策略),即每隔5帧更新一次模型参数,这不但提高了算法速度,而且提高了对突变,遮挡等情况的稳定性,三步优化中稀疏更新对效果提升最大。由于ECO的样本集是每帧都更新的,稀疏更新并不会错过间隔期的样本变化信息,但这种方法可能不适合没有样本集的方法,如KCF,因为没有保存样本集,一旦错过就是永远。。
当然,ECO的成功还有很多细节,如果想了解更多最好去看代码,因为MD大神的论文干货太多,很多成功的细节在论文中都没有提(~毕竟是大神,要我就多写几篇~),这里仅举两个例子(因为实在太多了):
- 响应插值问题:ECO-HC中HOG特征的cell_size=6,CN特征的cell_size=4,如果是100*100的图像块,提取特征并降维以后,HOG特征是16*16*10,CN特征是25*25*3,虽然C-COT中的continuous convolution operators连续空域插值解决了不同分辨率的集成问题,但最终响应图的分辨率也只有25*25,fDSST中的响应图插值方法效果甚微,在SRDCF中改为牛顿法迭代找到子像素精度的最大值点,比响应图插值方法更快更好。
- 基础分辨率问题:从KCF到SRDCF都有一个问题,就是相关滤波器的分辨率是由第一帧目标的大小决定的,如果太大会缩放到合理尺度以保证速度,如大于200*200会固定缩放到200*200以内;但如果目标太小时也不合理,却都没有相应处理,比如第一帧目标是20*20,那滤波器的尺寸也是以20*20为基准,以后帧不管目标怎么变化,即使尺度变大到200*200也要缩放到20*20去提特征,这就非常不合理了。到C-COT和ECO时,MD大神用了双阈值,如ECO-HC中,如果第一帧目标大于200*200就缩小到200*200以内,如果小于150*150就放大到150*150以上,这样虽然在目标较小时速度比以前慢了,但可以利用更多目标纹理信息,提升跟踪精度。
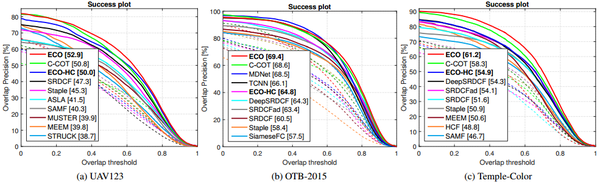
实验部分:ECO实验跑了四个库 (VOT2016, UAV123, OTB-2015, and TempleColor)都是第一,而且没有过拟合的问题,仅性能来说ECO是目前最好的相关滤波算法,也有可能是最好的目标跟踪算法。hand-crafted features版本的ECO-HC,降维部分,原来HOG+CN的42维特征降到13维,尺度自适应采用fDSST中的加速scale filter方法,其他部分类似,实验结果虽然没给ECO-HC在VOT2016的结果,但其他三个都很高,而且论文给出速度是60FPS,我用最新版代码跑的结果稍微低一点0.625。

这篇就到这里,算法怎么可能做到极致,我承认我骗人了。。
6.29更新:
前面提到过我自己优化的DCF版本用的是OpenCV中的DFT,是速度瓶颈,所以找了个开源的FFT库调用,其他部分保持不变,在OTB-2015上的测试结果:
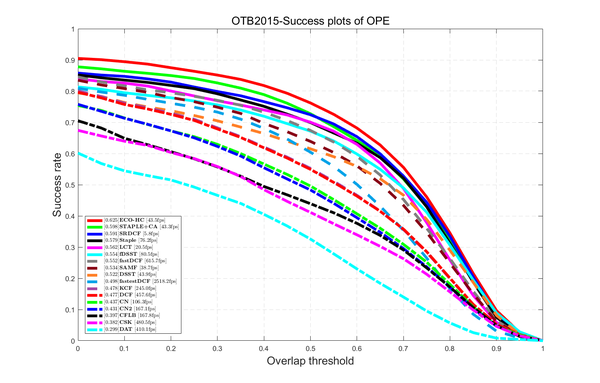

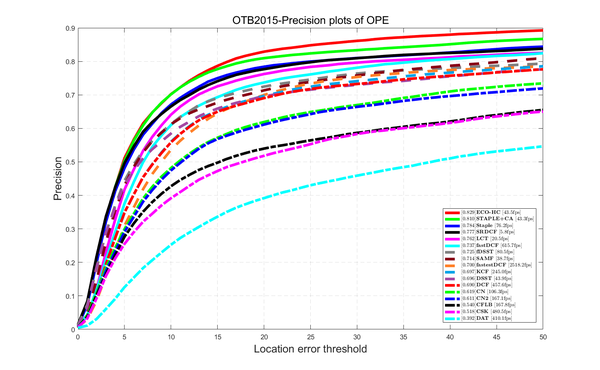

fast_DCF的速度从364fps提升到615fps,性能超过SAMF接近fDSST;
fastest_DCF的速度从1511fps提升到2518fps,性能还在比KCF之上。2500fps意味着完整跑完OTB2015的100个序列只需要3分钟。