在很多深度学习模型中都有门控这个东西,到底是怎么控制呢?计算相似度还是怎样呢?
关注者
26被浏览
32,431登录后你可以
不限量看优质回答私信答主深度交流精彩内容一键收藏

2022年11月11日 补充了一点想法
2019年11月06日 补充几篇文章
我简单说下我的理解。
说是门控直接的想法就是lstm,gru这一类的操作。
我是做视觉方向的,其他的见到的都是更多类似于注意力机制的处理。这种注意力机制的计算相对而言更简单一些。
我的理解,计算相关性也算是一种注意力的计算呢。
粗浅理解,欢迎指出问题。可能之后会补充些材料。
2019年11月06日补充:
我隐约记得,有文章是使用门控控制不同的block的使用,待我有时间找下。
2022年11月11日补充:
实际上门控和注意力机制的内在运算差异不大。二者可能在外在形式上略有偏重。注意力可能更强调像素级的一个控制,而门控可能粒度更粗一些,例如特征啦,模块啦。
最近基于门控的概念的工作其实也不少,大多题目名字里会直接提到。也有和 Transformer 概念相结合的,例如HorNet。
Gated Feedback Refinement Network for Coarse-to-Fine Dense Semantic Image Labeling
这几个是一系列工作:
- Label Refinement Network for Coarse-to-Fine Semantic Segmentation(基础版本)
- Gated Feedback Refinement Network for Dense Image Labeling(CVPR17的)
- Gated Feedback Refinement Network for Coarse-to-Fine Dense Semantic Image Labeling(这个应该是转投期刊的版本)
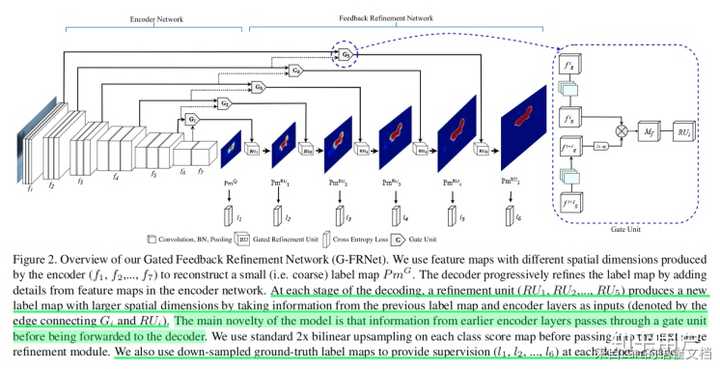

这里的门控没啥特殊处理,直接两个特征相乘得到的Mf就是所谓门控特征。
A Bi-directional Message Passing Model for Salient Object Detection
这是显著性检测的一篇文章。
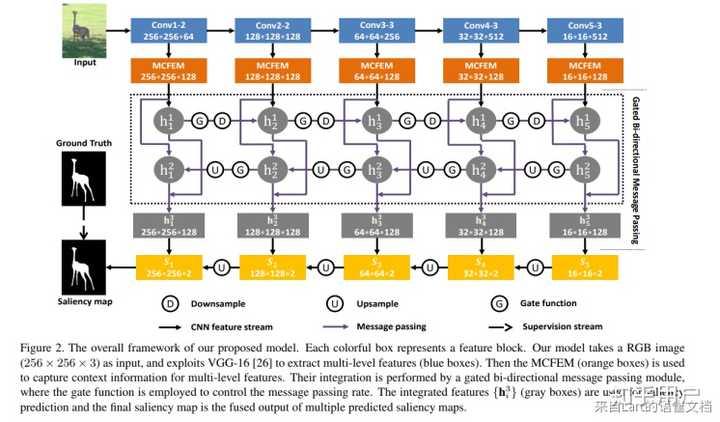

其中的G就是一个门控单元。这里利用对特征自身计算一个sigmoid来实现了一种类似于“传输率”的设定。
GFF: Gated Fully Fusion for Semantic Segmentation
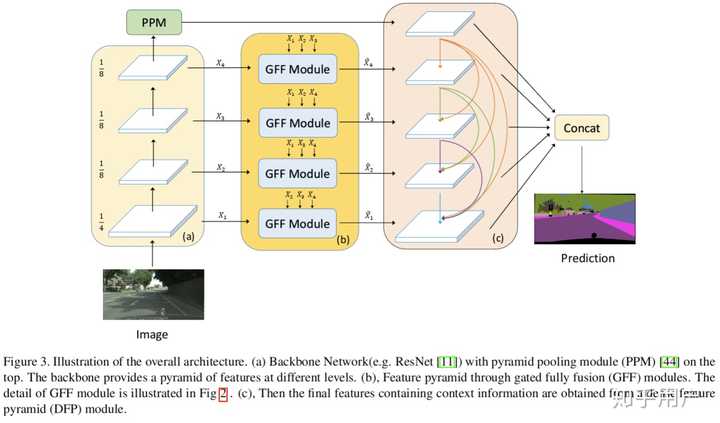

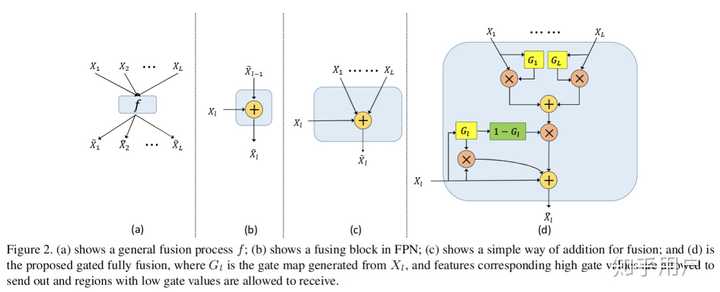

这里的gated map是那个G,G的计算有如下描述:
each gate map G_l=\text{sigmoid}(w_i∗X_i) is estimated by a convolutional layer parameterized with w_i \in \mathbb{R}^{1 \times 1 \times C_i} .
知乎的编辑器什么情况,在全屏模式下这里的公式编辑了好几次,提交修改后就被吞了?正常模式到是又没事了。
Context Contrasted Feature and Gated Multi-Scale Aggregation for Scene Segmentation
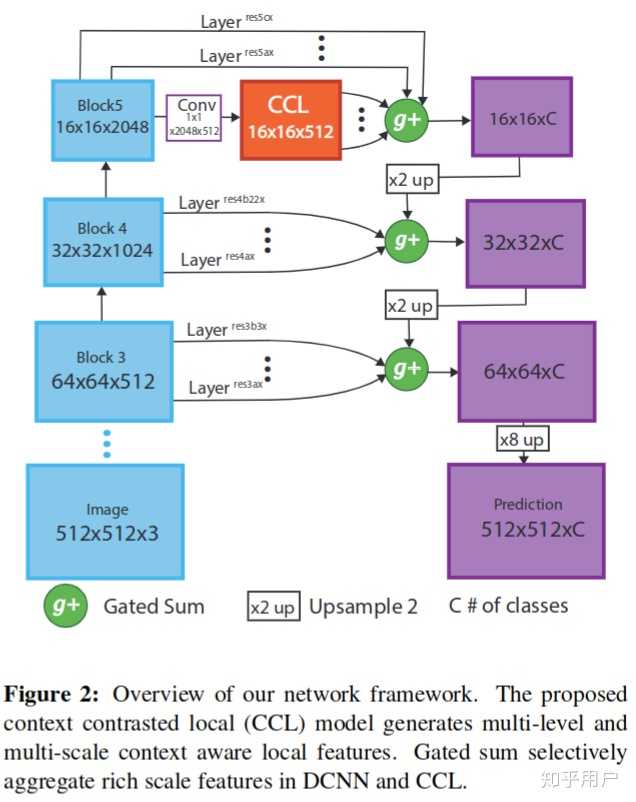

这篇文章的一个重点是其中的gated sum ,具体运算过程如下图:
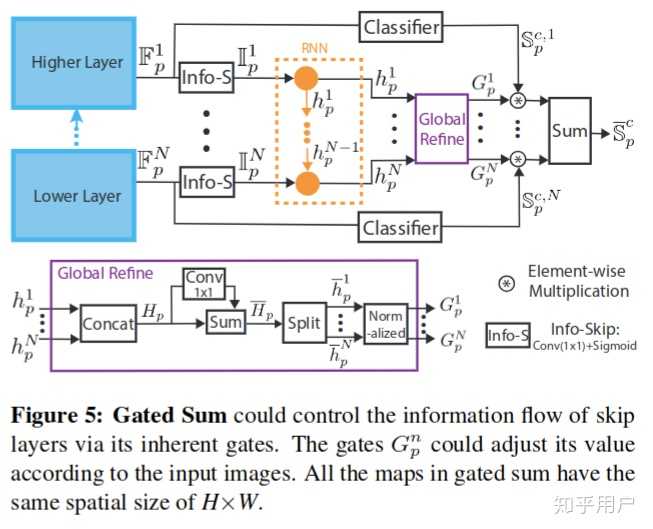

感觉具体过程操作还是蛮复杂的,之后看明白了补充下。
编辑于 2022-11-11 10:27・IP 属地山西