
Transductive Zero-Shot Learning
前段时间在弄关于Zero-Shot Learning (ZSL)的实验和论文(前天提交出去的,希望这次可以有好的结果,我愿意用身上十斤肉来换,哈哈哈~),看到了一些关于Transductive ZSL的文章,但当我打算开始做这方面的实验的时候,发现有很多不清楚的地方,所以打算先好好了解一下Transductive ZSL。一是核实自己的想法是否有问题,二是看看会不会已经有人做过相关的实验啦。
--------------------言归正传分割线----------------------
众所周知,ZSL的两个基本挑战(fundamental challenges)是:知识迁移(Knowledge Transfer)和领域自适应(Domain Adaptation)。其中,visual-semantic embedding的提出,建立了可见类(seen classes)和未见类(unseen classes)之间的语义关系,从而使得在见过的类里学到的知识可以通过这个语义空间迁移到没见过的类。大多数关于ZSL的文章都致力于visual-semantic embedding的构建。领域自适应主要是在广义的设定下考虑的,即Generalized ZSL (GZSL)。很多人认为,在实际应用中,我们并不知道我们面对的是见过的还是没见过的类,所以我们测试的时候应该把seen和unseen类都考虑进去。因为可见类和未见类是不同的,还可能是不相关的,所以当我们直接把可见类的学到的知识直接迁移到未见类上,就很容易出现领域漂移(Domain Shift)的问题,即把unseen类识别为seen类。为了缓解这种漂移,很多人就提出了Transductive ZSL的方法,即在训练的时候把unseen类的数据也用于visual-semantic embedding的构建,当然是没有标签的unseen数据,不然就不叫ZSL。
下图就很简单、形象的展示了Inductive ZSL和Transductive ZSL的训练、测试方法(来源于论文:Transductive Zero-Shot Recognition via Shared Model Space Learning,AAAI, 2016)
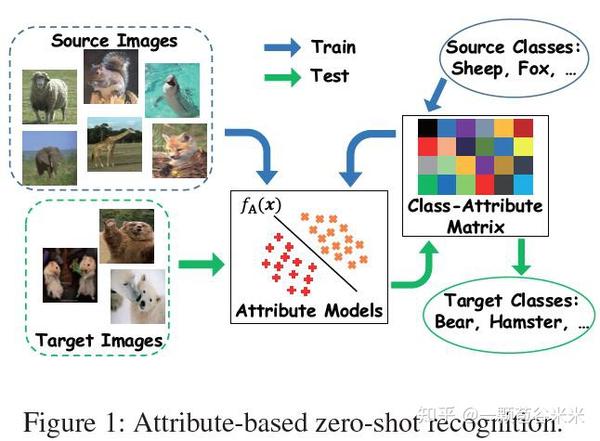

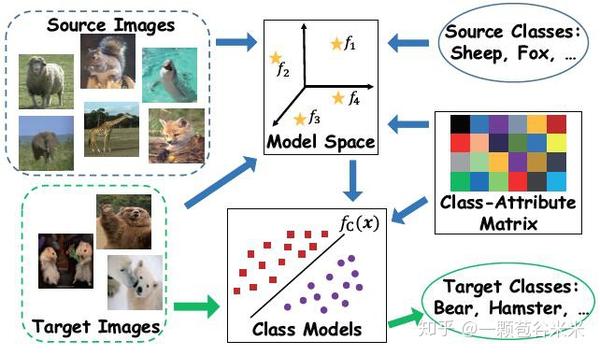

但在优化阶段,因为unseen类是没有label的,所以不能像seen类那样通过简单的分类误差进行优化。下面简单提一下对unseen类优化的几种方法:
-----------------------1、QFSL----------------------
Transductive Unbiased Embedding for Zero-Shot Learning, CVPR, 2018.
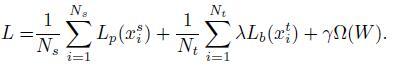
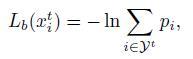
它的误差分为三部分:可见类的分类误差 L_p ,正则项 \Omega 和附加的未见类的偏置损失 L_b 。其中 L_b 的误差为某一未见类被预测为每一种未见类的概率总和,换言之,虽然我们不知道 x_i^t (未见类的图片)具体属于哪一类,但我们知道他一定属于未见类,那我们就把该图片映射在未见类标签空间的概率最大化,这样就可以一定程度上缓解GZSL设定中出现的映射偏移问题。
---------------------2、SPASS-----------------------
Transductive Zero-Shot Learning with Adaptive Structural Embedding, TNNLS, 2017.
这篇论文有在该专栏的另一篇文章也有提到:
这里再简单提一下。该文章不仅针对domain shift提出了方法,即SPASS(Self-PAsed Selective Strategy),还对visual-semantic embedding做出相应的贡献,作者称为ASTE(Adaptive STructural Embedding )方法。对于SPASS,作者认为,如果一个实例的预测是可靠的,那么它是容易预测的。(个人觉得这个假设比较弱,该方法的效果也不及上面的效果好。)所以作者提出了一种自步调选择策略(SPAS),用于迭代地选择可靠的伪标记的unseen实例。在自学习的启发下,引入了一个二元变量 u_m 来指示 第m个实例是否简单。然后定义选择过程为:
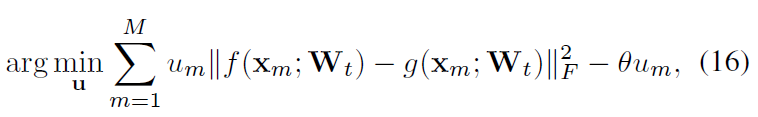

其中, M 是unseen data里的实例个数, f 是预测预测结果(可以看成是one-hot形式的), g 则是embedding结果, u=[u_1,u_2,...,u_M]\in[0,1]^M是指式向量,其值是 [0,1,1,0,...,1] 这个样子的。 \theta 则是一个阈值,用于限制每次选择的实例个数。 p = ||f(x_m;W_t)-g(x_m;W_t)||_F^2 的值越小,说明该实例的置信度越高。具个例子 g_1 = [0.5, 0.3, 0.2] , g_2 = [0.7, 0.2, 0.1] ,g1和g2的预测结果都为 f=[1,0,0] ,但是g1和f之间的p值是大于g2和f之间的p值的,说明他的置信度是较低的。从他们各自的结果很明显就能看出g2认为该类被分为第一类的概率为0.7,远大于0.5的。而 \theta 的值越小,该实例要被选择,即其 u_m=1 ,则其p值要小于\theta,才能被留下,因此只有真的“easy”实例会被选择,而随着\theta的值增大,约束减小,会有更多的不那么easy的实例也会被选择。该选择过程会一直持续到所有的实例都被选择为止。
--------------------总结分割线----------------------
使用Transductive ZSL方法来缓解domain shift,主要就是通过unseen类的加入,来构建一个更general的visual-embedding embedding,在训练的时候,来约束unseen类的映射范围;不仅如此,可以让模型对图像数据和属性数据有先验的了解,从而避免seen类与unseen类不同或可能不相关而导致的漂移问题。
