
智能质检新实践:“双模”质检

原文来自循环智能(Recurrent AI) 公众号
上篇文章,我们介绍了新一代智能质检模式——基于深度学习技术的“非正则”质检落地应用效果:在很多质检项上远超“关键词+正则”的传统模式,能多找出 2~10 倍数量的目标通话,并且介绍了其工作原理与“关键词+正则”的区别。
随着自然语言处理(NLP)领域技术的发展,以“非正则”模式为主、“关键词+正则”模式为辅的智能质检方案已成为未来发展趋势。两种模式将长期共存,因为它们各有其更擅长做的事情、更适配的场景。

“关键词+正则”模式的 2 种适配场景
在实际应用中,“关键词+正则”作为一种基础质检模式,越来越难以满足企业在质检效果和效率上的精细化需求。但是,这种模式也有它的优势:上手快。
当企业提出一个新的、此前从未用过的质检项时,质检项的标准尚未完全确定,因此可以用“关键词+正则”模式先跑起来,快速进行探索和迭代。其后根据初步探索和迭代的结果,再判断是否可以升级到基于深度学习技术的“非正则”模式。这是适配“关键词+正则”模式的第一种场景。


第二种场景:当一个质检项命中的目标通话量比较少,只有几百甚至几十条,就无法产生足够的“正例”给机器学习模型进行训练,只能继续采用“关键词+正则”模式。这是一种被动场景,也是比较常见的场景。
还有一种场景比较特殊:有些质检项命中的目标通话比较多,原则上可以用来训练机器学习模型,但是因为“关键词+正则”已经得出不错的结果,既找得全(术语叫召回率高),又找得准(术语叫准确率高),两个值都超过 90%,那么暂时就不迫切需要升级到“非正则”质检模式了。比如很多企业需要的正向质检项——“礼貌问候”,因为可以穷举出大部分“礼貌问候”的用词,用“关键词+正则”模式就能得到双 90%的结果。
不过,这种场景非常少见。大部分情况下,“关键词+正则”质检模式相比基于深度学习技术的“非正则”质检模式,在找全率和找准率上有很大差距。
“非正则”模式的 2 种适配场景
在实际应用中,基于深度学习技术的“非正则”质检模式(原理细节可参考上一篇文章),可以大幅提升质检效率,更好地解决企业质检任务的痛点:传统“关键词+正则”的模式,很难找得全和找得准目标通话,大大影响工作效率——如果找不全,就意味着会遗漏很多目标通话;如果找不准,就意味着在人工复检时会浪费大量人力。


我们之前分享过实际对比的例子,贷后资产管理领域的基础质检项“恐吓威胁”,采用基于深度学习技术的“非正则”质检模式找出的违规通话量是“关键词+正则”的 9 倍。
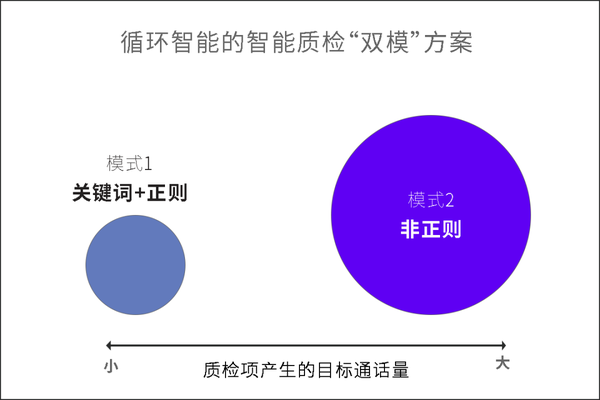
考虑到在实际使用中,质检项与命中的目标通话量之间的关系也存在“二八法则”——20%的质检项贡献了80%的质检量,所以将质检量大的少数质检项升级到“非正则”模式,往往可以大幅提升整个质检任务的找全率和找准率。这是“非正则”质检模式的第一种适配场景,也是主要的适配场景。
第二种场景:某些质检项,虽然从某一家企业的角度看,所命中的目标通话量不算大,但是这个质检项是整个行业中较为成熟的、通用的质检项,其他企业也都在用,那么就可以采用基于深度学习技术的“非正则”模式进行模型训练。因为其他企业都可以比较快速的复用或者经过简单调整之后复用,所以“非正则”模式带来的收益就更高。比如,消费金融领域的正向质检项“提示逾期天数”;客服领域的负向质检项“暴露客户隐私”等都是各自领域或行业通用的。
与“关键词+正则”质检模式相比,基于深度学习技术的“非正则”模式,不再需要既懂业务又懂正则的稀缺人才编写规则和迭代规则,只需要普通人快速进行数据标注即可训练算法模型,而且通常能得到更好的效果。唯一显著的缺陷就是,如果没有数千条数据,很难训练出效果好的模型。
“双模”质检,各司其职
当前阶段,质检项应该采取哪种模式,主要取决于该质检项产生的目标通话量大小——通常数量大,才能快速标注数据、训练出更好的算法模型,采用“非正则”模式,否则仍需要继续使用“关键词+正则”模式。

其次也要考虑到质检项的成熟度——太新的、标准尚不明确的质检项,适合先用“关键词+正则”模式迭代起来,再决定何时升级到基于深度学习技术的“非正则”模式。
综合来看,循环智能在实践中采用“双模”方案,让两种模式各司其职,可以最大程度提升质检效率。
循环智能的主产品是基于对话数据的 AI 销售中台,针对销售和客服场景,提供三大核心模块:线索成单预测、客户心声分析和智能质检,并提供电话录音ASR语音识别基础服务。猛戳这里,申请免费试用。