
SSD

参考: SSD: Single Shot MultiBox Detectordeepsystems.io
背景介绍:
基于“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的结果,但是在速度方面离实时效果还比较远在提高 mAP 的同时兼顾速度,逐渐成为 Object Detection 未来的趋势。 YOLO 虽然能够达到实时的效果,但是其 mAP 与刚面提到的 state of art 的结果有很大的差距。 YOLO 有一些缺陷:每个网格只预测一个物体,容易造成漏检;对于物体的尺度相对比较敏感,对于尺度变化较大的物体泛化能力较差。针对 YOLO 中的这些不足,该论文提出的方法 SSD 在这两方面都有所改进,同时兼顾了 mAP 和实时性的要求。在满足实时性的条件下,接近 state of art 的结果。对于输入图像大小为 300*300 在 VOC2007 test 上能够达到 58 帧每秒( Titan X 的 GPU ),72.1% 的 mAP。输入图像大小为 500 *500 , mAP 能够达到 75.1%。作者的思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。


关键点:
关键点1:网络结构
该论文采用 VGG16 的基础网络结构,使用前面的前 5 层,然后利用 astrous 算法将 fc6 和 fc7 层转化成两个卷积层。再格外增加了 3 个卷积层,和一个 average pool层。不同层次的 feature map 分别用于 default box 的偏移以及不同类别得分的预测(惯用思路:使用通用的结构(如前 5个conv 等)作为基础网络,然后在这个基础上增加其他的层),最后通过 nms得到最终的检测结果。
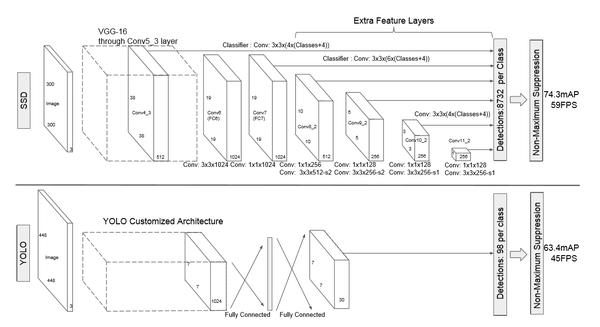

这些增加的卷积层的 feature map 的大小变化比较大,允许能够检测出不同尺度下的物体: 在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。观察YOLO,后面存在两个全连接层,全连接层以后,每一个输出都会观察到整幅图像,并不是很合理。但是SSD去掉了全连接层,每一个输出只会感受到目标周围的信息,包括上下文。这样来做就增加了合理性。并且不同的feature map,预测不同宽高比的图像,这样比YOLO增加了预测更多的比例的box。(下图横向的流程)
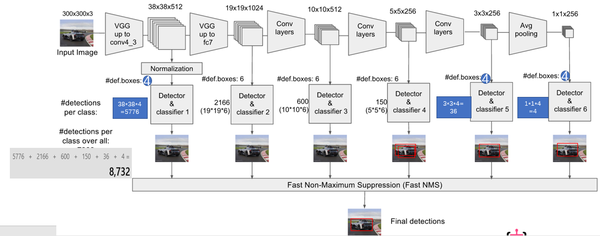

关键点2:多尺度feature map得到 default boxs及其 4个位置偏移和21个类别置信度
对于不同尺度feature map( 上图中 38x38x512,19x19x512, 10x10x512, 5x5x512, 3x3x512, 1x1x256) 的上的所有特征点: 以5x5x256为例 它的#defalut_boxes = 6
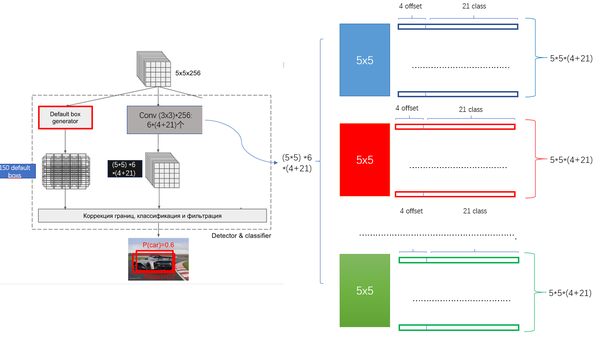

- 1 按照不同的 scale 和 ratio 生成,k 个 default boxes,这种结构有点类似于 Faster R-CNN 中的 Anchor。(此处k=6所以:5*5*6 = 150 boxes)
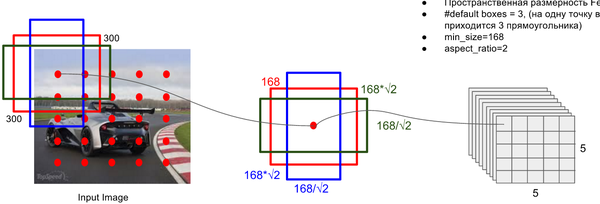

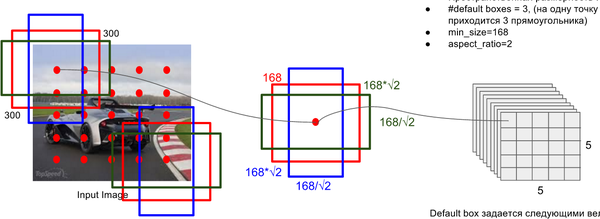

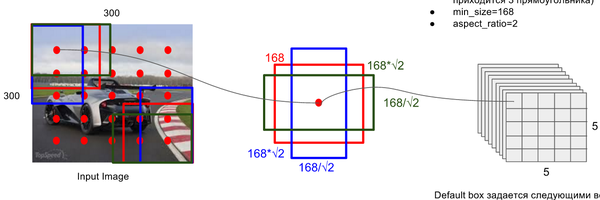

- 2 新增加的每个卷积层的 feature map 都会通过一些小的卷积核操作,得到每一个 default boxes 关于物体类别的21个置信度 (c_1,c_2 ,\cdots, c_p 20个类别和1个背景) 和4偏移 (shape offsets) 。
- 假设feature map 通道数为 p 卷积核大小统一为 3*3*p (此处p=256)。个人猜想作者为了使得卷积后的feature map与输入尺度保持一致必然有 padding = 1, stride = 1 : \frac{ inputFieldSize - kernelSize + 2 \cdot padding }{stride} + 1 = \frac{5 - 3 + 2 \cdot 1}{1} + 1 = 5
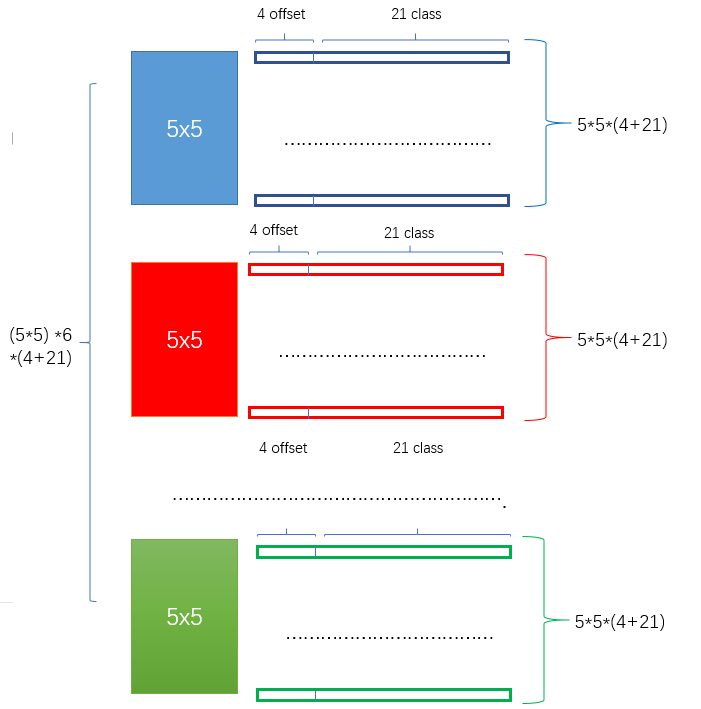
- 假如feature map 的size 为 m*n, 通道数为 p,使用的卷积核大小为 3*3*p。每个 feature map 上的每个特征点对应 k 个 default boxes,物体的类别数为 c,那么一个feature map就需要使用 k(c+4)个这样的卷积滤波器,最后有 (m*n) *k* (c+4)个输出。





训练策略
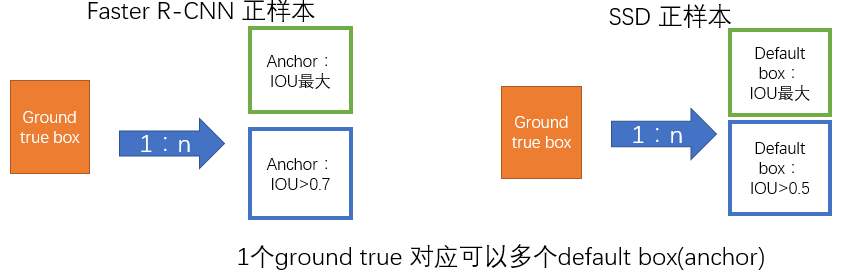
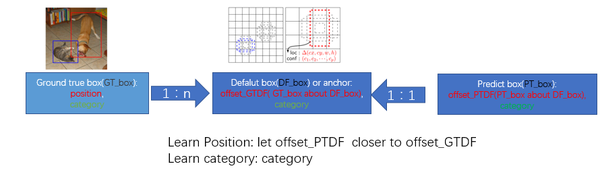
监督学习的训练关键是人工标注的label。对于包含default box(在Faster R-CNN中叫做anchor)的网络模型(如: YOLO,Faster R-CNN, MultiBox)关键点就是如何把 标注信息(ground true box,ground true category)映射到(default box上)
- 正负样本: 给定输入图像以及每个物体的 ground truth,首先找到每个ground true box对应的default box中IOU最大的作为(与该ground true box相关的匹配)正样本。然后,在剩下的default box中找到那些与任意一个ground truth box 的 IOU 大于 0.5的default box作为(与该ground true box相关的匹配)正样本。 一个 ground truth 可能对应多个 正样本default box 而不再像MultiBox那样只取一个IOU最大的default box。其他的作为负样本(每个default box要么是正样本box要么是负样本box)。下图的例子是:给定输入图像及 ground truth,分别在两种不同尺度(feature map 的大小为 8*8,4*4)下的匹配情况。有两个 default box 与猫匹配(8*8),一个 default box 与狗匹配(4*4)。
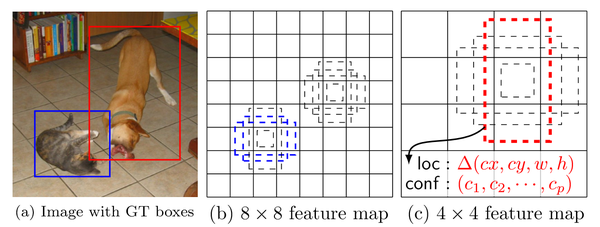




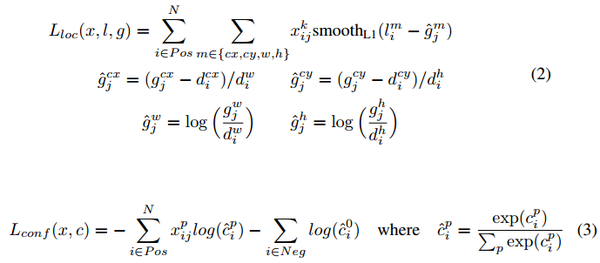


在预测阶段,直接预测每个 default box 的偏移以及对于每个类别相应的得分。最后通过 nms 的方式得到最后检测结果。
Default Box 的生成:
该论文中利用不同层的 feature map 来模仿学习不同尺度下物体的检测。
- scale: 假定使用 m 个不同层的feature map 来做预测,最底层的 feature map 的 scale 值为 s_{min} = 0.2,最高层的为 s_{max} = 0.95,其他层通过下面公式计算得到 s_k = s_{min} + \frac{s_{max} - s_{min}}{m - 1}(k-1), k \in [1,m]
- ratio: 使用不同的 ratio值a_r \in \left\{1, 2, \frac{1}{2}, 3, \frac{1}{3} \right \} 计算 default box 的宽度和高度:w_k^{a} = s_k\sqrt{a_r},h_k^{a} = s_k/\sqrt{a_r}。另外对于 ratio = 1 的情况,额外再指定 scale 为s_k{'} = \sqrt{s_ks_{k+1}} 也就是总共有 6 中不同的 default box。
- default box中心:上每个 default box的中心位置设置成 ( \frac{i+0.5}{ \left| f_k \right| },\frac{j+0.5}{\left| f_k \right| } ) ,其中 \left| f_k \right| 表示第k个特征图的大小 i,j \in [0, \left| f_k \right| ) 。
Hard Negative Mining:
用于预测的 feature map 上的每个点都对应有 6 个不同的 default box,绝大部分的 default box 都是负样本,导致了正负样本不平衡。在训练过程中,采用了 Hard Negative Mining 的策略(根据confidence loss对所有的box进行排序,使正负例的比例保持在1:3) 来平衡正负样本的比率。这样做能提高4%左右。
Data augmentation
为了模型更加鲁棒,需要使用不同尺寸的输入和形状,作者对数据进行了如下方式的随机采样:
- 使用整张图片
- 使用IOU和目标物体为0.1, 0.3,0.5, 0.7, 0.9的patch (这些 patch 在原图的大小的 [0.1,1] 之间, 相应的宽高比在[1/2,2]之间)
- 随机采取一个patch
当 ground truth box 的 中心(center)在采样的 patch 中时,我们保留重叠部分。在这些采样步骤之后,每一个采样的 patch 被 resize 到固定的大小,并且以 0.5 的概率随机的 水平翻转(horizontally flipped)。用数据增益通过实验证明,能够将数据mAP增加8.8%。
