
机器学习中如何用F-score进行特征选择
目前,机器学习在脑科学领域的应用可谓广泛而深入,不论你是做EEG/ERP研究,还是做MRI研究,都会看到机器学习的身影。机器学习最简单或者最常用的一个应用方向是分类,如疾病的分类。对于有监督机器学习(如我们常用的SVM)来说,首先需要提取特征值,特征值作为机器学习的输入进行训练,得到模型。但是,在实际的例子中,不太可能把提取到的所有特征值输入到机器学习模型中进行训练,这是因为过多维度的特征值往往会包括冗余成分,这不仅会大大降低学习速度,而且还会产生过拟合现象,进而影响机器学习模型的性能。最典型的列子是我们做MRI研究,可能会提取到上万个特征值。因此,我们需要首先对提取到的特征值进行特征选择,去除冗余特征,即所谓的特征降维。
目前,特征降维的方法很多,笔者这里就不一一列举,而F-score是其中比较简单和有效的方法,也是很常用的一种方法。今天,笔者在这里就详细讲解一下F-score如何计算,并给出Matlab程序。
第i个特征的F-score的计算公式如下所示:
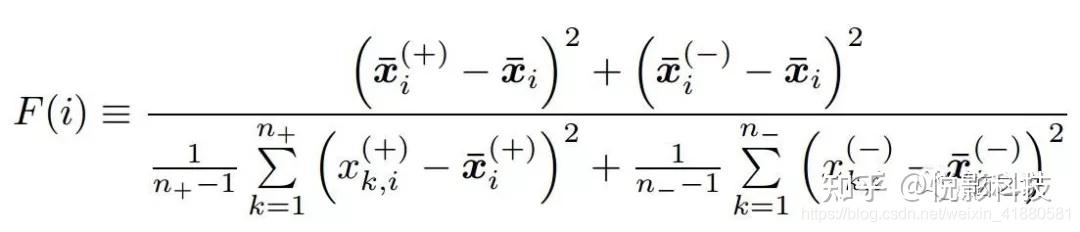
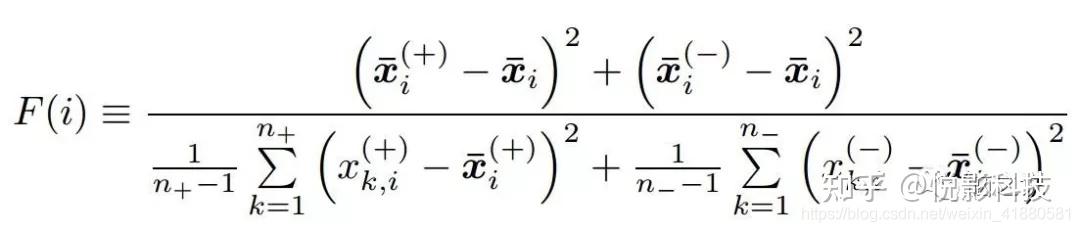
其中,图片表示第i个特征中正类特征值的平均值,图片表示第i个特征中负类特征值的平均值,图片表示第i个特征所有特征值的平均值,n+表示第i个特征中正类特征值的个数,n-表示第i个特征中负类特征值的个数,图片表示正类特征值中第k个特征值,图片表示负类特征值中第k个特征值。
对于F-score需要说明一下几点:
1.一般来说,特征的F-score越大,这个特征用于分类的价值就越大;
2.在机器学习的实际应用中,一般的做法是,先计算出所有维度特征的F-score,然后选择F-score最大的N个特征输入到机器学习的模型中进行训练;而这个N到底取多少合适,需要你自己进行尝试;
3.F-score只适用于二分类,对于多分类的应用,可以考虑采用其他的特征选择方法;
4.F-score与SVM相结合,可以达到较好的分类效果。