
中科院韩先培:预训练模型怎样成为下一代知识图谱

【专栏:研究思路】随着大规模预训练模型的快速发展,许多研究者都在期待,模型能够将通用的知识抽取到通用的知识库/知识图谱中,为构建新的AI节省开发的时间和精力,让研究者能够更加专注于构建AI专门的能力上。
然而,超大规模预训练模型是否有成为下一代知识图谱的潜质?在近期的青源Talk活动中,中科院软件所韩先培研究员通过列举在预训练模型上开展的实验认为:预训练模型具有知识预测的能力,但是其仍存在很多缺陷,一是大规模预训练语言模型的工作机理还不明确;二是基于提示语的知识提炼手段,仍处于初步阶段,之前研究的一些评估手段都不可靠。
韩先培研究员建议,当前需要一些系统性的机制探索,彻底明晰预训练模型的内部机制。当可以解释这些模型的时候,就可以信任它,作为一个可信任的知识图谱。同时,建立专业和标准的评估手段,对模型提炼的知识进行专业效果评估也十分关键。


本文整理自青源Talk第六期,视频回放链接:https://event.baai.ac.cn/activities/173


韩先培,中科院软件所研究员,担任中文信息处理实验室副主任,入选国家优青、中国科协青年人才托举计划及北京智源青年科学家。主要研究方向为信息抽取、知识图谱及自然语言理解。
演讲:韩先培
整理:李栋栋
审校:戴一鸣
01
背景:预训练模型快速发展,引起知识图谱领域的讨论
(一)构建通用知识库成为AI的发展目标
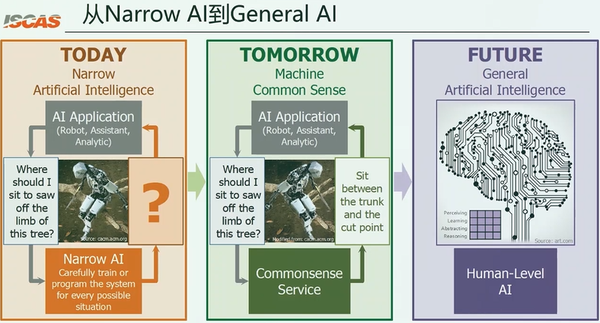

现如今AI发展迅猛,各种模型层出不穷,但是依然局限于narrow AI,也就是窄AI、弱AI的范畴。我们做每一个任务、完成每一个需求,都需要完整地构建一套新的应用来做这件事。比如说,要理解自然语言、识别图片,或者做机器人的规划,都需要从头到尾去构建一个新的AI的agent来完成。
做这些任务的时候,都要去设计它的输入、输出和训练方法,构成一个agent。这样一种弱AI方式会导致:我们每次构建任务的时候都要经过繁杂的过程。是否可以考虑把这些不同的AI共同的、共享的知识提炼出来,我们并不再需要从头再去构建这些AI的能力。
例如,我们可以把AI共享的知识,比如说空间的、时间的、物理的知识,如果可以把它们抽取出来,放到一个知识库中。这样,在构建AI的时候,就无需构建这些基本的常识,我们就可以把精力放在构建和AI应用特别相关的能力上面。
比如说构建机器人,我们不用重新构建机器人走路的技能、识别地图的技能,而是让机器人直接去完成的任务就可以了,这就是机器常识的目标。如果可以逐渐地把机器的这种能力抽象、提炼出来,逐渐地将各种能力从而将其提炼为一个抽象、可复用的状态,可以构建一个通用的智能。我们无需很多领域的语料,就可以构建通用的,像人类这种级别的智能,因为人类只需要很少的样本就可以学习到某些能力。
(二)通用知识库的探索历程
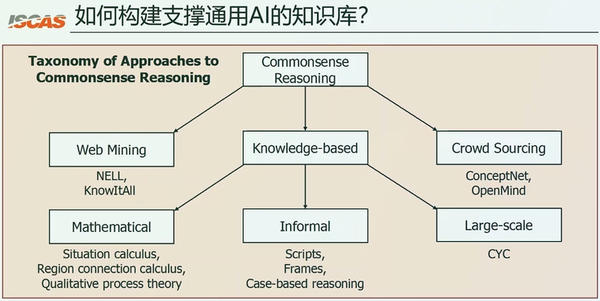

上面的目标,实际上已经有了多年的探索,这个过程就是构建通用AI的知识库,通常来说有三种手段。
第一种是基于web的挖掘,从九几年就开始了,例如NELL和KnowItAll等。这种工作的问题在于它挖掘出的很多知识都是存在噪音的,距离人类的常识还有很远的距离。
第二种是基于知识,我们首先定义好需要什么样的知识,然后让专家来一条一条编写这些知识,这种手段更早,从七几年就开始了,例如OpenCYC等。它编写了几百条知识,但是最终靠人还是难以得到机器常识的知识库,最终OpenCYC停留在一个初始的阶段,没有办法达到它最终的目标。
2000年以后,众包的形式取代了手工的方式,和web方法相互促进,构建了很多大的知识库,例如ConceptNet等。但是,众包知识的缺点是覆盖度不够,仍旧无法支撑真正的AI应用。
2016年之后,大规模预训练模型开始兴起,使用大规模预训练模型来构建知识库的新范式出现了。
(三)大规模预训练模型来势汹汹
大规模预训练模型模型说到底是一个语言模型,常见的例子如中国的首都是“哪里”,需要预测的词是北京,这种就属于预测下一个词。还有一种就是美国的“什么”是纽约,语言模型预测的结果应该是金融中心,这就属于预测挖空的词。
这些模型具备超大的语料、超大的参数和超大的算力,并且往往越大性能越好,这不仅仅体现在本身的能力,还有下游任务的迁移和自适应能力,如GPT-3不需要训练就能完成文本生成、问答和编曲的任务。
02
预训练模型成为知识图谱的可能性
(一)一切皆有可能?
这么多大规模的语言模型能力如此强,就引出了一个疑问,PLM可以作为知识图谱使用吗?因为像北京是中国的首都、傲慢与偏见是用什么语言写的、鸽子是什么颜色这些常识性的知识,它回答地都非常好 ,而这些常识性的知识抽取对于做知识图谱的人来说是一件苦差事,看到这些结果,大家感觉是不是好日子已经来了?
看到这些实验结果鼓舞人心,就有人做了一个实验,构建了一个LAMA数据集,通过这个数据集去测试这些模型里面是否存在知识。LAMA里面有十几种关系,每种关系用到了三元组,例如问一个人的出生地、出生日期和死亡地点,通过实验证明,该数据集具备较好的性能。
2019年这些工作出来后,又引出了更多人的尝试,每一种尝试都提升了它可以作为知识图谱的可能性,在这看来好像没有什么不可能的。


(二)构建知识图谱的难点


基于前面的想法,我们后面开展了研究性工作,但是这个过程中发现了一些问题。比如乔布斯是哪个公司的CEO,他回答的是微软,奥巴马是哪个国家的总统,它回答的是利比亚。然而,我们知道,利比亚和美国是敌对的关系,这些例子很明显是不对的。
另外,一些常识例子,如一张纸有几条腿、什么动物有毛和爪子,预训练模型的回答是“一张纸有两条腿”、“男性拥有毛和爪子”。这些例子有好的有坏的,究竟哪些是对的,它的预测机制是什么,预训练模型值得信任作为知识库么,我们非常想搞清楚这些问题。
(三)预训练模型进行知识预测背后的原理
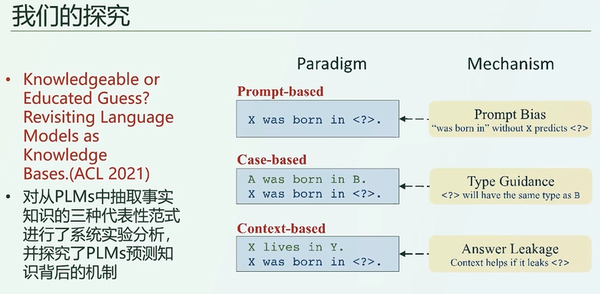

21年开始,我们开始做了一些工作,想知道模型是知识很渊博还是猜测的能力很强,它到底是否具备真正的知识。研究发现,前面所提到的预训练语言模型,如果使用这种大规模预训练模型作为知识图谱,它常常表现为三种模式。
第一种是提示语的模式,我们想知道什么知识,直接问知识图谱就可以,比如x出生于哪里这个问题,只要知道x出生于后面那个答案即可,这个提示语和其答案就组成了一条关于x的出生地的一条知识。
预训练模型作为知识图谱的第二种使用模式,是一种基于样例的类比模式。例如,乔布斯出生于加利福尼亚,比尔盖茨出生在加州,此时问知识图谱另外一个人出生在什么,它的回答应该是这个人出生在哪个地方,也就是前面的两个事例应该会帮助知识图谱识别出来,识别出我的问题应该是关于地域的答案,这个出生应该是一个地点,而非一个时间。
第三种使用的模式就是基于上下文的推理。例如,给一大段关于乔布斯的维基百科文本,然后再问乔布斯出生在什么地方?此时应该基于前面的一些背景的知识,能够推理出来乔布斯出生在哪,有了这个背景知识,那么最终答案可能给出的也是加州。模式已经总结为如上三种,但是这三种模式究竟有什么样的研究结果呢?研究人员对这三种模式分别做了详细的实验,结果如下。
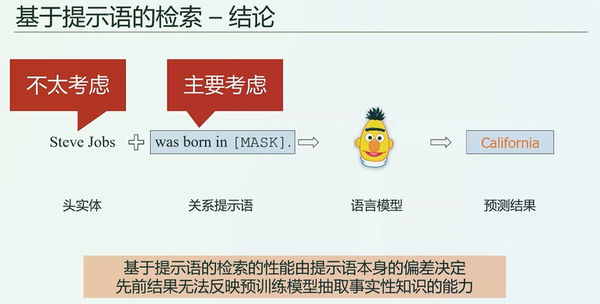
1.基于提示语的检索
起初,给出一个头实体的集合,按道理它的预测分布应该跟头实体的答案分布高度相关,例如给出100个中国人、50个美国人和20个日本人,最后预测结果应该中国人占60%,美国人占30%,日本人占10%,也就是通过这种分布来探索模型预测的机制是否和数据分布有关。
按照这个假设,我们构建了两个数据集,WIKI-UNI和LAMA,LAMA出生地是有个规律——遵循长尾分布,流行的城市出现次数更多,如伦敦。把这两个数据集输入到大规模模型里面,发现了一个很神奇的现象,就是不管输入如何,最终结果的分布几乎不变,都是伦敦最多,其他次之。
也就是说,预训练语言模型预测出来的答案,跟输进去的query的正确答案的分布好像关系不是太大。正确答案的分布跟预测出来的答案的分布没有太大的关联,这就说明预训练语言模型好像没有理解前面想要问的这个问题。
接着,第二个研究就是把实体抹掉了,比如乔布斯出生在什么地方,直接把乔布斯抹掉,最终答案的分布仍旧是不受影响。也就是加不加头实体对预测结果没有影响,即预测主要考虑提示语,而不考虑头实体。既然不考虑头实体,那么为何LAMA的结果如此好呢,研究结论是LAMA的答案分布正好和语言模型一致,只要一换成WIKI-UNI,它的结果马上就降下来了。
所以,最终得到的答案是:基于提示语的检索性能由提示语本身的偏差决定,结果无法真实反映预训练模型抽取事实知识的能力。

2.基于示例类比
示例的类比,就是通过给出一些奥巴马出生在夏威夷、比尔盖茨出生在加州的例子,可以提升预测史蒂夫乔布斯出生在什么地方的能力,也就是举一反三的能力。给模型输入以后,的确提升了性能,一系列结果证明,示范性的样本可以通过帮助模型更好的识别实体类别,从而提升知识抽取的性能。但是如果类别本身是错误的,提示语并不能帮助模型提升预测的准确率。
结论是:加入额外示例提升了预测类别的能力,但是并没有提升特定答案实体的能力。给出奥巴马出生在夏威夷、比尔盖茨出生在加州的例子,只是提升了模型推理出他出生在某个地方的能力,还是不能区分到底是加利福尼亚还是德克萨斯这种具体实体结果。


3.基于上下文推理
这种模式就是从大规模预选领域来提取知识的能力,给出乔布斯居住在加州,创业在加州,希望提升他出生在加州的预测能力。实验证明,这些上下文的确提升了性能,但是究竟是哪些具体的上下文提升了性能呢?后来发现,因为上下文都包括了加州,所以准确率高。如果去掉加州,则准确率降低近30%,也就是这些显式的答案泄漏提升了预测能力。
更进一步,即使Mask掉上下文答案 ,性能提升依旧明显,这是为什么呢?实际上没有答案的时候,预训练语言模型根据之前的上下文也可以预测出正确的结果,这种可以称之为隐藏的答案泄漏。
结论是:上下文实际上是通过显式或者隐示的答案泄漏来提供额外的信息,从而提升了模型预测的能力。该方式之所以起作用的机制是因为,它是一种显式或隐藏的答案泄露,比如说史蒂夫乔布斯居住在什么地方,如果把答案抹掉了,只要基于前面的语言模型所提供的知识,还是能预测出加利福尼亚这个词语,只不过有的是直接显露的给出答案,有的是隐藏的、不明显的答案。


通过如上综述,预训练模型作为良好知识库的主要来自于提示语偏差、类别指导和答案泄漏,这与我们当初的预期并不完全,那么它到底是否是下一代的知识图谱吗?
03
展望


前面我们探讨了这样的一些工作,其实最终要表达和探索的还是标题,即预训练模型是否可以作为下一代的知识图谱,关于该题目,通过前面的研究主要总结出来三点,这三点也是对未来的一些展望。
第一个就是预训练模型具有成为下一代知识图谱的潜力,预训练语言模型中确实是包含了非常多的知识,只是目前这些潜力还是没有发挥。
第二个就是这种大规模预训练语言模型的工作机理还不明确,它目前还是一个黑箱,因此需要去探明它背后的预测机制。在现实中,不能只是问一下答一下,然后发现它的效果很好就认为可以使用它作为图谱,还需要去理解它真正的预测机制是什么。需要一些系统的机制探索,彻底明白了它的机制,并且可以解释这些模型的时候,此时就可以信任它,把它作为一个可信任的知识图谱。
第三个就是这种基于提示语的知识提炼手段,还是在一个很初步的阶段,即前面研究的一些评估手段都是不可靠的,并没有一套专业和标准的评估手段来对这些提炼的知识进行专业的效果评估,也就是如果测量长度,起码保证尺子是对的,如果尺子本身都是错的,那么前面得到的结果也必然是错的,所以,尺子很重要,一套完整、专业的评估手段对于这些研究的发展是非常重要的。
欢迎关注智源社区公众号(ID:BAAIHub)阅读原文参与文章讨论。