显存不足?PyTorch 显存使用分析与优化
面对动辄几百万几千万参数量的模型, GPU那连常规 U盘都比不过的显存, 真的是杯水车薪。相信大家在日常模型训练过程中,或多或少的总会遇见:
torch.FatalError: cuda runtime error (2) : out of memory
那么, 可怜的显存到底在哪里消耗掉了?
显存去哪了?
首先我们看一下 PyTorch 官方的数据格式(由于文本只讨论显存,故将 CPU tensor 去掉了):
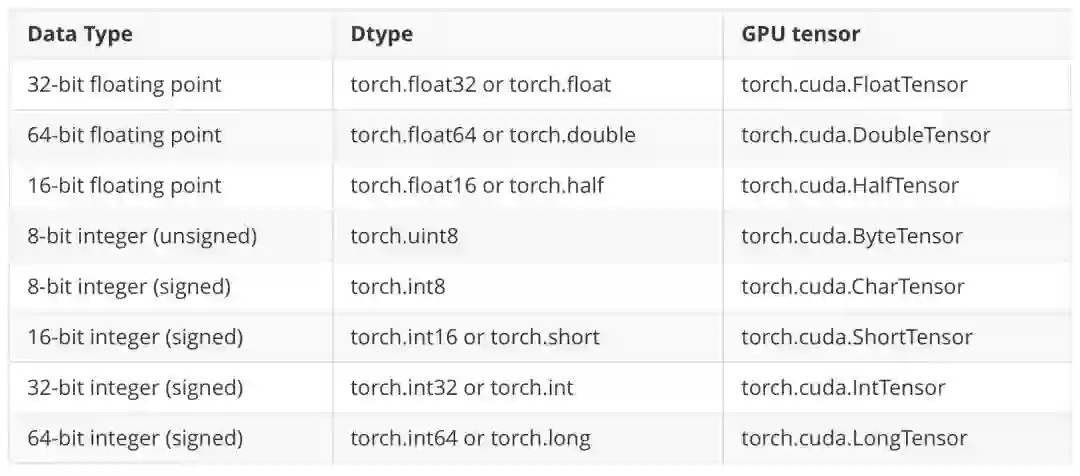
其中,大家日常训练用到的一般是torch.cuda.FloatTensor和torch.cuda.IntTensor, 根据上表,它们分别是32位浮点数和32位整数,都占4个 Byte.
也就是说,常见的一张224x224大小的图片,占用 个 Byte,约为588K。
根据常用的张量组织形式(bathc_size, channel, height, width), 那么一个大小时(128,3, 224, 224) 的张量约占用73.5M。
让我们来看一下常见的 VGG-16的内存占用:

上述图片来自 CS231n 的课件
(http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf)
是 VGG-16 在输入单张图片,且在不计算 biases的情况下计算的内存和参数量占用。
红色字体代表:从输入图像开始,每一个的卷积池化,全连接所产升的内存消耗。
蓝色字体代表:每一步计算,所需要记住的参数的个数
注意,这只是前向 forward 时候的内存消耗,计算反向传播的时候,上述消耗要至少再乘以2,因为链式法则要记很多中间结果。
最终的结果有点沉重,单张图片96M,反向传播时单张图片192M。这时候,我们稍微升高一下 batch_size, 比如batch_size = 128, 结果可想而知
处理模型设计的固有内存占用,还有很多模块也占用非常多的显存。
比如:优化器
比如常用的随机梯度下降SGD,它的计算公式是:
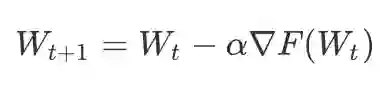
显然,程序是要记忆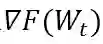
但是,如果要使用动量(Momentum-SGD) , 程序还要额外记忆动量, 占用显存 x3:

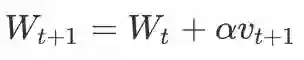
而更常用的,如果我们使用 Adam 优化器,占用显存 x4。
总的来说,显存占用分四个部分:
模型参数
模型计算中间结果
反向传播中间结果
优化器额外参数
计算模型显存占用
比如我们有一个如下的 PyTorch 模型:
Sequential(
(conv_1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(relu_1): ReLU(inplace)
(conv_2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
(relu_2): ReLU(inplace)
(pool_2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1,
ceil_mode=False)
(conv_3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1),
padding=(1, 1))
)
我们可以使用model.parameters() 将模型的参数拿出来,然后统计一下个数:
import numpy asnp
# 模型内参数个数
para =sum([np.prod(list(p.size())) for p in model.parameters()])
# float32 占 4个 Byte
type_size =4
model_size =para * type_size /1024/1024
print(model_size)
# 约为0.43M
显然,这仅仅是第一部分,模型参数
模型计算的中间结果可以通过传入一个简单输入,然后提取中间结果来统计:
input_ =input.clone()
# 取消计算梯度,我们现在只计算模型中间结果的大小
input_.requires_grad_(requires_grad=False)
mods =list(model.modules())
out_sizes =[]
fori inrange(1, len(mods)):
m =mods[i]
ifisinstance(m,nn.ReLU):
ifm.inplace:
continue
out =m(input_)
out_sizes.append(np.array(out.size()))
input_ = out
total_nums =0
fori inrange(len(out_sizes)):
s =out_sizes[i]
nums =np.prod(np.array(s))
total_nums += nums
cost_size =total_nums * type_size /1000/1000
print(cost_size)
# 约为320.5M
正向计算结果约为320.5M,反向x2,约为641M
如何优化
出了模型层面的优化,其他的显存优化主要有以下几点:
减少batch,减少每次的输入图像数量
多使用下采样,池化层等
一些神经网络层可以进行小优化,利用relu层中设置inplace
PyTorch 0.4推出了一个新功能,能够在一定程度上解决显存不足的问题,测量主要是拿时间换空间。它的实现方式是将一个计算过程分成很多份,我们就可以先计算一部分,保存后一部分需要的中间结果,然后再计算后一部分。
也就是说,新的checkpoint允许我们只存储反向传播所需要的部分内容。如果当中缺少一个输出(为了节省内存而导致的),checkpoint将会从最近的检查点重新计算中间输出,以便减少显存使用:
比如,我们有一个1000层的全连接:
input=torch.rand(1, 10)
# 1000 个 10 x 10 的全连接层
layers = [nn.Linear(10, 10) for _ inrange(1000)]
model = nn.Sequential(*layers)
output = model(input)
这个模型如果正常运行将占用海量显存,因为计算中会产生很多的中间变量。现在我们可以使用checkpoint节省资源占用。
input = torch.rand(1, 10, requires_grad=True)
layers = [nn.Linear(10, 10) for _ in range(1000)]
# 计算第一部分
def run_a(*args):
x = args[0]
for layer in layers[:500]:
x = layer(x)
return x
# 计算第二部分
def run_b(*args):
x = args[0]
for layer in layers[500:-1]:
x = layer(x)
return x
from torch.utils.checkpoint import checkpoint
result_a = checkpoint(run_a, input)
result_b = checkpoint(run_b, result_a)
total_result = layers[-1](result_b)
output = total_result.sum()
output.backward()
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知




