



了解 GPT、Gemini 等大型语言模型的原理(通俗易懂)
《How Large Language Models Work》(大型语言模型的工作原理)将多年关于大型语言模型(LLMs)的专家研究成果,转化为一本可读性强、内容聚焦的入门读物,帮助你掌握这些令人惊叹的系统。书中清晰解释了 LLM 的工作机制,介绍了优化与微调方法,以及如何构建高效、可靠的 AI 应用流程和管道。
**你将在本书中学到:
如何测试与评估 LLM * 如何使用人类反馈、监督微调和检索增强生成(RAG)技术 * 如何降低错误输出、高风险失误和自动化偏差的风险 * 如何构建人机交互系统 * 如何将 LLM 与传统机器学习方法相结合
本书由 Booz Allen Hamilton 的顶尖机器学习研究人员撰写,包括研究员 Stella Biderman、AI/ML 研究总监 Drew Farris 和新兴 AI 研究总监 Edward Raff。他们用通俗易懂的语言,深入浅出地讲解了 LLM 和 GPT 技术的运作原理,适合所有读者阅读和理解。
技术背景介绍
大型语言模型为“人工智能”中的“I”(智能)赋予了实质含义。通过连接来自数十亿文档中的词语、概念与模式,LLM 能够生成类似人类的自然语言回应,这正是 ChatGPT、Claude 和 Deep-Seek 等工具令人惊艳的原因所在。在这本内容翔实又富有趣味的书中,来自 Booz Allen Hamilton 的全球顶尖机器学习研究人员将带你探讨 LLM 的基本原理、机遇与局限,并介绍如何将 AI 融入组织与应用中。
图书内容简介
《How Large Language Models Work》将带你深入了解 LLM 的内部运作机制,逐步揭示从自然语言提示到清晰文本生成的全过程。书中采用平实语言,讲解 LLM 的构建方式、错误成因,以及如何设计可靠的 AI 解决方案。同时你还将了解 LLM 的“思维方式”、如何构建基于 LLM 的智能体与问答系统,以及如何处理相关的伦理、法律与安全问题。
**书中内容包括:
如何定制 LLM 以满足具体应用需求 * 如何降低错误输出和偏差风险 * 破解 LLM 的常见误解 * LLM 在语言处理之外的更多能力
适读人群
无需具备机器学习或人工智能相关知识,初学者亦可放心阅读。
作者简介
Edward Raff 是 Booz Allen Hamilton 的新兴 AI 总监,领导该公司机器学习研究团队。他在医疗、自然语言处理、计算机视觉和网络安全等多个领域从事 AI/ML 基础研究,著有《Inside Deep Learning》。Raff 博士已在顶级 AI 会议发表超过 100 篇研究论文,是 Java Statistical Analysis Tool 库的作者,美国人工智能促进协会资深会员,曾两度担任“应用机器学习与信息技术大会”及“网络安全人工智能研讨会”主席。他的研究成果已被全球多个杀毒软件厂商采纳并部署。 Drew Farris 是一位资深软件开发者与技术顾问,专注于大规模分析、分布式计算与机器学习。曾在 TextWise 公司工作,开发结合自然语言处理、分类与可视化的文本管理与检索系统。他参与多个开源项目,包括 Apache Mahout、Lucene 和 Solr,并拥有雪城大学信息学院的信息资源管理硕士学位与计算机图形学学士学位。 Stella Biderman 是 Booz Allen Hamilton 的机器学习研究员,同时担任非营利研究机构 EleutherAI 的执行董事。她是开源人工智能的重要倡导者,参与训练了多个世界领先的开源 AI 模型。Biderman 拥有佐治亚理工学院计算机科学硕士学位,以及芝加哥大学的数学与哲学学士学位。
目录一览
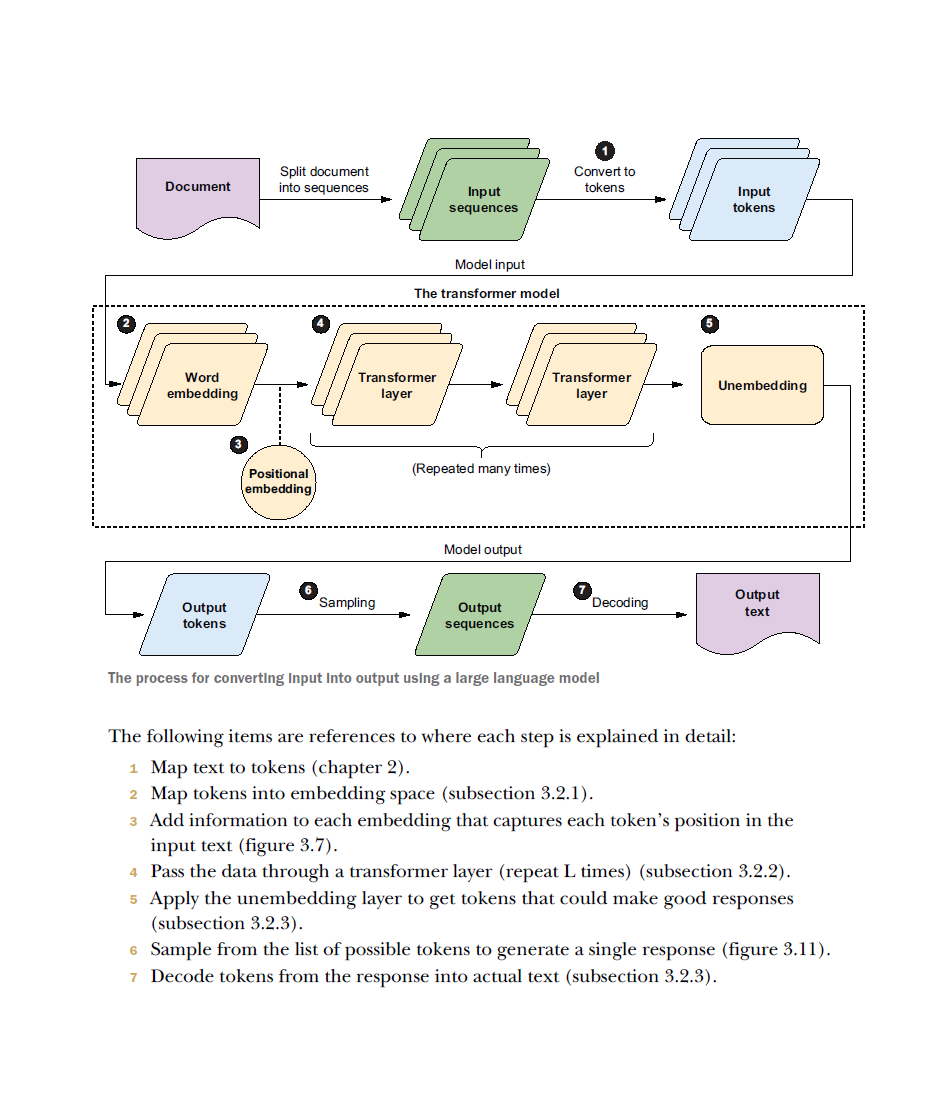
大局观:LLM 是什么? 1. 分词器:LLM 如何“看”世界 1. Transformer:输入如何变成输出 1. LLM 是如何学习的 1. 如何约束 LLM 的行为 1. 超越自然语言处理 1. 对 LLM 的误解、局限与能力 1. 如何用 LLM 设计解决方案 1. 构建与使用 LLM 的伦理问题




本书的核心观点是:自人工智能(AI)发展以来,我们能够且应当将过去40至50年视作重大变革来临前的“前奏”。人类认知曾是推动人类发展的核心动力。因此,机器执行人类认知的能力,以及人机团队共同学习、协同思考的能力,将塑造一个崭新的世界。这场变革开创的现实,让我们得以构想这样的未来:后人会将我们生活的时代视为新阶段智人(或无论何种称谓)的起源。唯有数十年后——甚或更久——人类才能获得理解这些变革的恰当视角。在我们这一代,技术不仅是辅助人类的工具;是AI在改变人类。是AI在重构知识与传播的本质。有生以来第一次,改写DNA的可能性不再属于科幻范畴。我们正处于数字时代变革加速的临界点。
本文探讨当AI颠覆基本规则时,如何在此数字时代(DE)加速期引领国家与组织。书中案例源自国家安全领域的经验与视角,但其洞见同样适用于经济、医疗健康、个人安全等其他领域。任何国家、机构及学科均可借鉴本书观点并应用于自身领域。本书遵循一条既宽广又聚焦的道路——宽广到足以引领我们迈向未来,聚焦到贴合现实、切实可行,并阐明我们能够且真正应当采取的行动。我们当下构建的理念、概念与实践,将成为下一代发展的基石。因此,在此阶段赢得竞争的国家或组织,将具备定义并主宰未来的潜力。
本书面向高级领导人、高级军官与高层管理者;面向期望精准把握组织所面临挑战、风险与机遇的国家安全官员及管理者;亦面向所有渴望理解AI潜力与应用的人们。



几十年前,Mumford 曾写道,代数几何“似乎已经获得了一个声誉:它晦涩难懂、门槛极高、抽象无比,其拥护者似乎正密谋接管数学的其他所有分支。”如今,这场革命已全面到来,并从根本上改变了我们对许多数学领域的理解方式。本书为读者提供了这一变革性思想体系的坚实基础,通过非正式但严谨的讲解方式,帮助读者在掌握强大技术工具的同时建立直观理解。 本书以范畴思维和层的讨论为起点,逐步引出“几何空间”的概念,并以概型和簇为代表展开阐述,随后进一步讨论这些几何对象的具体性质。接下来的章节涵盖了维数与光滑性、向量丛及其自然推广、重要的上同调工具及其应用等主题。对于一些关键但进阶的内容,书中也通过带星号的部分进行了补充。 主要特色包括:
提供全面系统的入门指导,有望成为该领域的权威教材; * 包含丰富的练习,强调“做中学”的学习方式; * 几乎不设前置要求,从范畴论和层论一直发展到交换代数与上同调代数,构建学生所需的全部工具; * 采用以实例为驱动的方式,帮助建立扎实的数学直觉; * 既是面向研究生的自包含教材,也是研究人员的重要参考书籍。
















