阅读理解之(bidaf)双向注意力流网络
作者:张贵发
研究方向:自然语言处理
阅读理解
机器理解(machinechensition,mc),给定文本资料,根据资料回答问题,这就像我们学生时代的阅读理解,我们需要对给定的文本context和query,给出答案这复杂的过程进行建模。
常见注意力机制特点
注意力机制推动了机器理解的进展,以往工作中的注意力机制通常具有以下一个或多个特征。
首先,计算的注意力权重通常用于从上下文中提取最相关的信息,通过将上下文汇总到固定大小的向量中来回答问题。
其次,在文本域中,它们通常是临时动态的,因此当前时间步的注意权重是上一时间步的所有向量的函数。
第三,它们通常是单向的,查询关注上下文段落或图像。
想要详细了解seq2seq attention请参考:
https://zhuanlan.zhihu.com/p/40920384
bidaf
Introduction(介绍)
论文地址:https://arxiv.org/pdf/1704.04368.pdf
本文介绍了双向注意流(bidaf)网络,它是一个多阶段的层次化过程,它在不同的粒度级别上表示上下文,并使用双向注意流机制在不进行早期总结的情况下获得一个查询感知的上下文表示。
Model(模型)
模型的主要组成部分
Character embedding layer(字符嵌入层)
Word embedding layer(词嵌入层)
Contextual embedding layer(上下文嵌入层)
Attention flow layer(注意流层)
Modeling layer(模型层)
Output layer(输出层)

我们先从架构图入手,首先是对文本内容从字符和词的不同粒度进行embedding,将得到的结果进行拼接,经过双层的LSTM进一步处理,截至前三层,都还是对context和query的文本不同表达。
进入注意流层,这里提供了两个方向的注意力,一种的由context到query,一种是query到centext。值得注意的是这里每一步的注意力并没有依赖之前的注意力值,而是直接流入下一步,有效避免信息损失
经过model的BI-LSTM的处理,用softmax给出答案的起始位置
模拟过程
我们先简单的模拟一下bidaf的过程,char、word进行embedding只是单词进行空间映射,假设我们给定:
context: I am in china
query: where are you
为了简化,这里设定维度是3,进行映射后:
I (0.1,0.1,0.1)
am (0.2,0.2,0.2)
in (0.3,0.3,0.3)
….
那么文本内容就变为

(paper中的d在这里就是3,T就是4,J就是3)
接下来是Contextual Embedding ,其实就是经过了双向的LSTM的处理计算,因为双向维度增加一倍,我在这里没有真正模拟lstm_cell计算,只是简单给出了一样的值:


Context-to-query 注意力计算,就是计算query中每个word与context中word的相似度,相似度越高,重要度也越重要,利用计算得到的相似矩阵,如:
I=0.3where+0.36are+0.42*you
am=0.6where+0.72are+0.84*you
….


Query-to-context 的注意力计算,取出每一行最大值,在这里,由于我们初始值设置简单,正好是最后一列,在这里每一列取出最大值,找出query中每个词对应的context中最相关(相近的词),这样可以保留整体的相关性


I=0.42*I
am=0.84*am
…


Character Embedding(字符嵌入)
将每个词看作字符级一维的图片处理,经过CNN处理,得到单词在字符级别的向量表示。
表示context中第t个词的向量表示
表示query中第j个词的向量表示
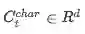
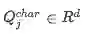
Word Embedding(词嵌入)
词嵌入层是将每个词映射到高维向量空间。本文使用的是Glove,大家也可尝试word2vec。
表示context中第t个词的向量表示
表示query中第j个词的向量表示
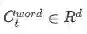
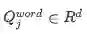
将两种映射后的结果进行拼接,这里使用的是双层的Highway Network。
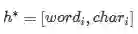
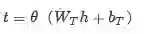

经过上述复杂运算就得到了整合了词和字符信息的context和query表示
T表示context中词的数目
J表示query中词的数目
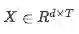
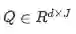
Contextual Embedding(上下文嵌入)
上下文嵌入层利用来自周围单词的上下文提示来优化文字的嵌入。我们使用一个长期短期记忆网络(lstm)在前几层提供的嵌入之上,来模拟单词之间的时间交互。我们在两个方向上放置一个LSTM,并连接两个LSTM的输出。因此得到,
context上下文向量
query问题向量
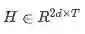
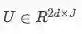
注意,H和U的每一列向量都是二维的,因为前向和后向LSTM的输出是串联的,每一列都有d维的输出。
Attention Flow(注意流层)
注意流层。注意力流层负责链接和融合上下文和query词中的信息。与以前流行的注意力机制不同,注意力流层不用于将查询和上下文总结为单个特征向量。相反,每个时间步骤的注意向量,以及来自前一层的嵌入,都可以流到下一个建模层。这减少了早期总结造成的信息损失。
首先本层的输入为上层的输出即:
context上下文向量
query问题向量
引入共享的相似度矩阵S,S的大小是T乘以J,即
S矩阵中的元素代表的含义:
表示context中第t个word对应query中第j个word的相似度
α是一个可训练的标量函数,它编码两个输入向量之间的相似性 :
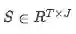


本文中选择的标量函数是:
是可训练的权重向量
○是元素乘法
[;]是向量行上的拼接,隐式乘法是矩阵乘法
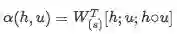
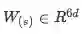
接下来我们用s来获得注意点和注意向量:
Context-to-query Attention(C2Q):
Context-to-query Attention(C2Q):针对context中的每个单词,计算query中每个单词与context当前单词t的相关度。用来表示query中words在单词t上的权重weight。
所有注意力和为1,这里做了归一化。注意力的计算通过softmax实现:
那么每个被注意到的query vector的计算如下Query-to-context Attention(Q2C):
Query-to-context Attention(Q2C)则是表示针对query中的每个单词,计算context中的每个单词与query当前词j的相关度,这里的相关其实就是哪一个上下文词与其中一个query词最相似,因此对于回答最为重要,
上式的含义是先取S中每一列的最大值形成一个新的向量 , 然后对这个新的向量求相关度:
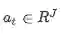
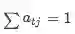
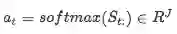
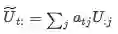

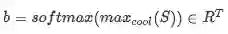

Modeling(建模层)
建模层的输入是G,它对上下文词的查询感知表示进行编码。建模层的输出捕获基于query的上下文词之间的交互。这与上下文嵌入层不同,上下文嵌入层捕获独立于查询的上下文词之间的交互。我们使用两层双向LSTM,每个方向的输出大小为d。因此,我们得到一个矩阵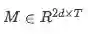
Output Layer(输出层)
输出层是特定于应用程序的。bidaf的模块化特性允许我们根据任务轻松地交换输出层,而架构的其余部分保持完全相同。
该层其实是根据任务而定, 对于Squad 数据集而言,是为了寻找信息片段的开始位置和结束位置, 有很多种方式, 本文用到的是:
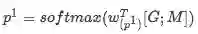
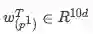
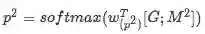
其中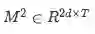
最后的损失函数,采用交叉熵:
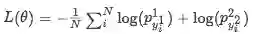
Dataset(数据集)
数据集
SQuAD 是斯坦福大学于推出的数据集,一个阅读理解数据集,给定一篇文章,准备相应问题,需要算法给出问题的答案。原始地址下载速度比较慢,在此提供了已下载好的数据(dev-v1.1.json与train-v1.1.json),同时运行需要的glove文件也在此网盘中,请自行下载
百度网盘:https://pan.baidu.com/s/1yUC6yp0-VTh3aWwCgnT7TQ
提取码:f8de
实验
这里给出tensorflow1.2后的版本,原有版本太低,需要修改代码太多,https://github.com/allenai/bi-att-flow/tree/dev
如果是低版本注意:代码调整:
from tensorflow.python.ops.rnn_cell import _linear 替换为 from
tensorflow.contrib.rnn.python.ops.core_rnn_cell import _linearconcat 中位置替换如 concat_out = tf.concat(2, outs) concat_out =
tf.concat( outs,2)_linear函数中参数修改,这个根据自己的版本api
…
低版本与高版本代码中都缺少部分参数:在basic.cli中参加参数,我这里是随机给定的参数默认值
flags.DEFINE_string("out_dir", "", "Shared path []")
flags.DEFINE_string("save_dir", "", "Shared path []")
flags.DEFINE_string("log_dir", "", "Shared path []")
flags.DEFINE_string("eval_dir", "", "Shared path []")
flags.DEFINE_string("answer_dir", "", "Shared path []")
flags.DEFINE_integer("max_num_sents", 256, "para size th [256]")
flags.DEFINE_integer("max_sent_size", 256, "para size th [256]")
flags.DEFINE_integer("max_ques_size", 256, "para size th [256]")
flags.DEFINE_integer("max_word_size", 256, "para size th [256]")
flags.DEFINE_integer("max_para_size", 256, "para size th [256]")
flags.DEFINE_integer("word_emb_size", 256, "para size th [256]")
flags.DEFINE_integer("word_vocab_size", 256, "para size th [256]")
flags.DEFINE_integer("char_vocab_size", 256, "para size th [256]")
flags.DEFINE_integer("emb_mat", 256, "para size th [256]")
flags.DEFINE_float("new_emb_mat", 0.5, "Exponential")
Model 重要参数
我的运行环境是gpu,16G。batch_size = 60, 如果内存小,建议调小batch_size,不然会有oom。初始学习率 = 0.5, epoch = 12, dropout = 0.2,hidden_size=100,num_steps=20000,
输出文件保存在当前的out目录下:

本文由作者投稿并且原创授权AINLP首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。



