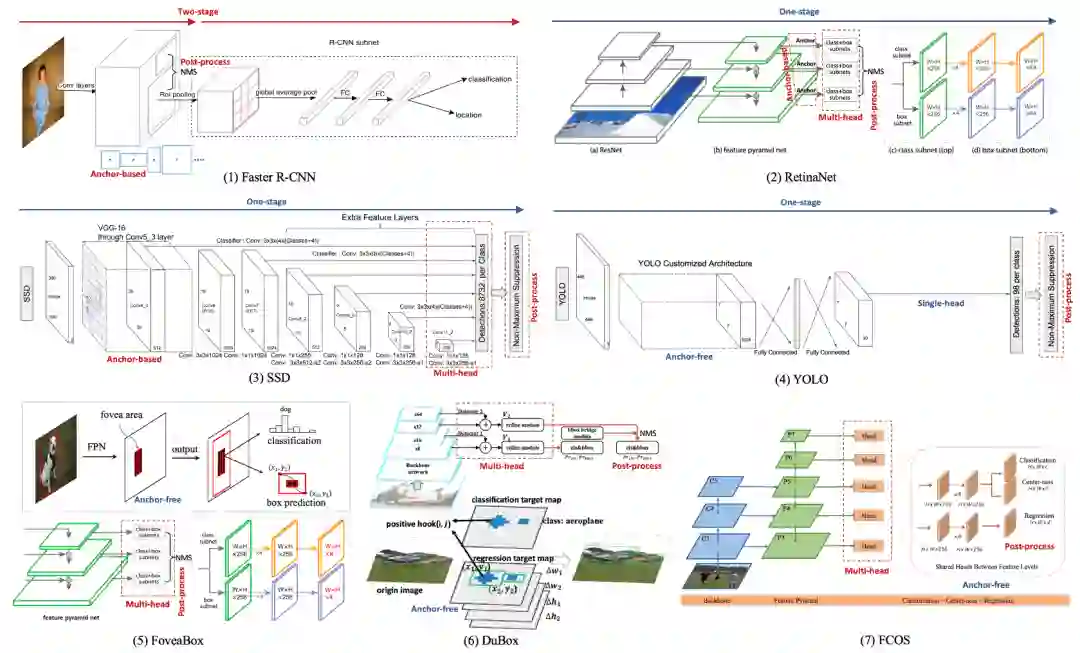
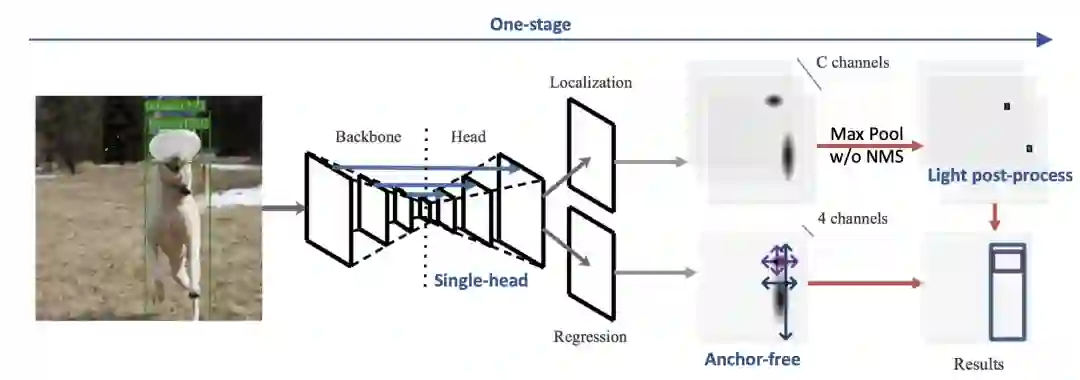
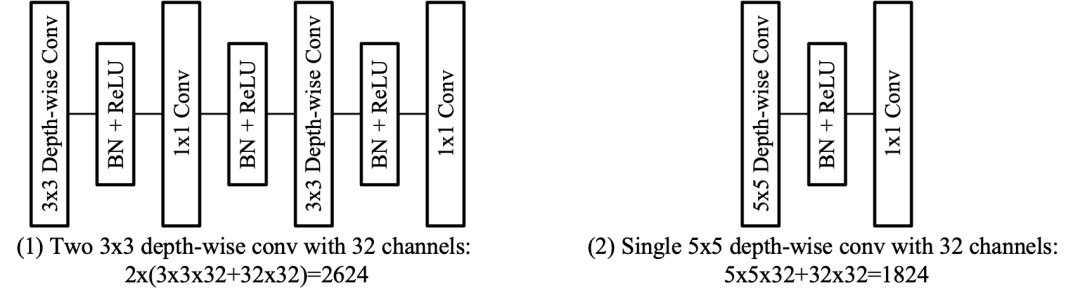
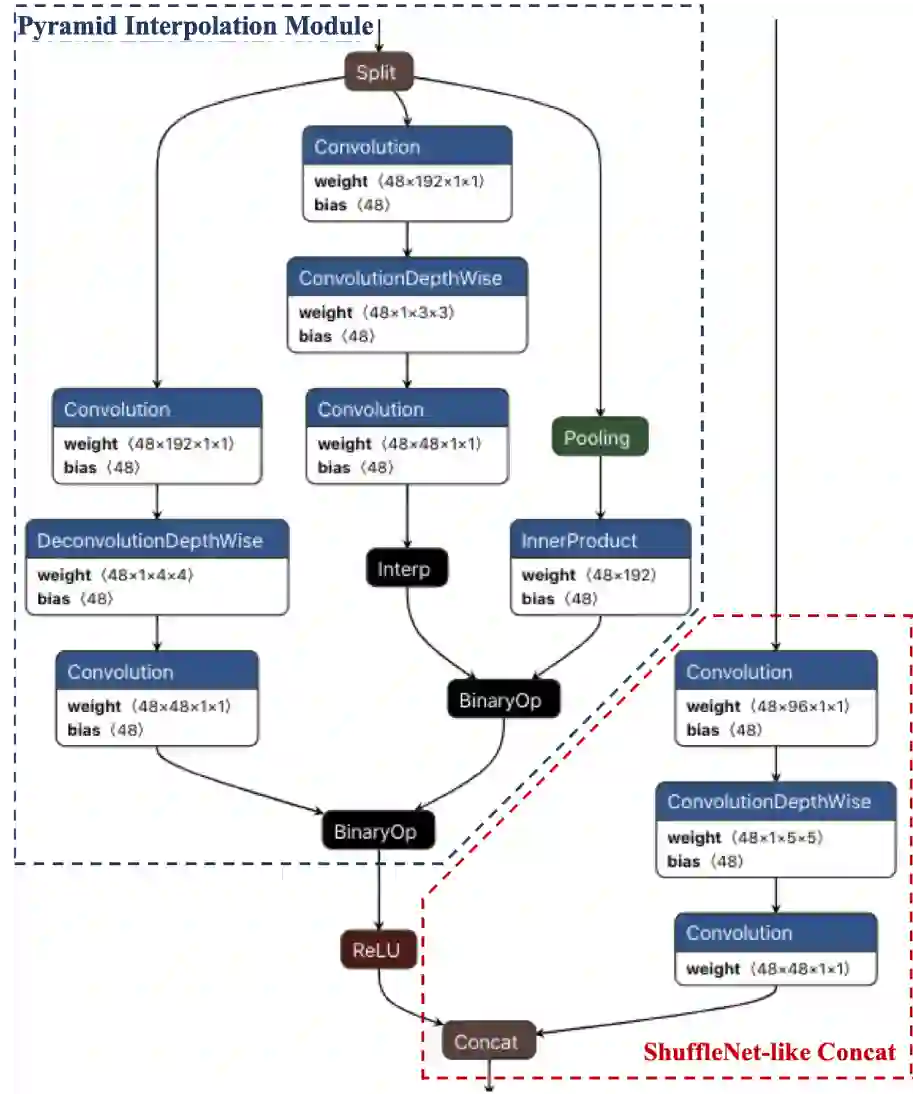
[1] Girshick, Ross. "Fast R-CNN." international conference on computer vision (2015): 1440-1448.
[2] Ren, Shaoqing, et al. "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks." IEEE Transactions on Pattern Analysis and Machine Intelligence 39.6 (2017): 1137-1149.
[3] He, Kaiming, et al. "Mask R-CNN." international conference on computer vision (2017): 2980-2988.
[4] Redmon, Joseph, et al. "You Only Look Once: Unified, Real-Time Object Detection." computer vision and pattern recognition (2016): 779-788.
[5] Redmon, Joseph, and Ali Farhadi. "YOLO9000: Better, Faster, Stronger." computer vision and pattern recognition (2017): 6517-6525.
[6] Redmon, Joseph, and Ali Farhadi. "YOLOv3: An Incremental Improvement." arXiv: Computer Vision and Pattern Recognition (2018).
[7] Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." european conference on computer vision (2016): 21-37.
[8] Lin, Tsungyi, et al. "Focal Loss for Dense Object Detection." international conference on computer vision (2017): 2999-3007.
[9] Lin, Tsungyi, et al. "Feature Pyramid Networks for Object Detection." computer vision and pattern recognition (2017): 936-944.
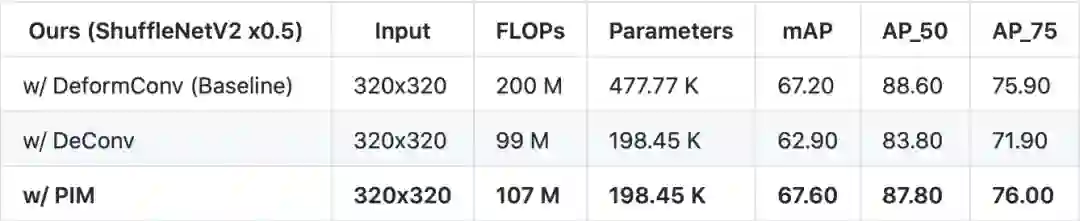
[10] Dai, Jifeng, et al. "Deformable Convolutional Networks." international conference on computer vision (2017): 764-773.
[11] Yu, Jiahui, et al. "UnitBox: An Advanced Object Detection Network." acm multimedia (2016): 516-520.
[12] Huang, Lichao, et al. "DenseBox: Unifying Landmark Localization with End to End Object Detection." arXiv: Computer Vision and Pattern Recognition (2015).
[13] Chen, Shuai, et al. "DuBox: No-Prior Box Objection Detection via Residual Dual Scale Detectors." arXiv: Computer Vision and Pattern Recognition (2019).
[14] Kong, Tao, et al. "FoveaBox: Beyond Anchor-based Object Detector." arXiv: Computer Vision and Pattern Recognition (2019).
[15] Tian, Zhi, et al. "FCOS: Fully Convolutional One-Stage Object Detection." international conference on computer vision (2019): 9627-9636.
[16] Law, Hei, and Jia Deng. "CornerNet: Detecting Objects as Paired Keypoints." european conference on computer vision (2019): 765-781.
[17] Zhou, Xingyi, Dequan Wang, and Philipp Krahenbuhl. "Objects as Points." arXiv: Computer Vision and Pattern Recognition (2019).
[18] Liu, Zili, et al. "Training-Time-Friendly Network for Real-Time Object Detection." arXiv: Computer Vision and Pattern Recognition (2019).
[19] Rezatofighi, Hamid, et al. "Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression." computer vision and pattern recognition (2019): 658-666.
[20] Ma, Ningning, et al. "ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design." european conference on computer vision (2018): 122-138.
[21] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-Net: Convolutional Networks for Biomedical Image Segmentation." medical image computing and computer assisted intervention (2015): 234-241.
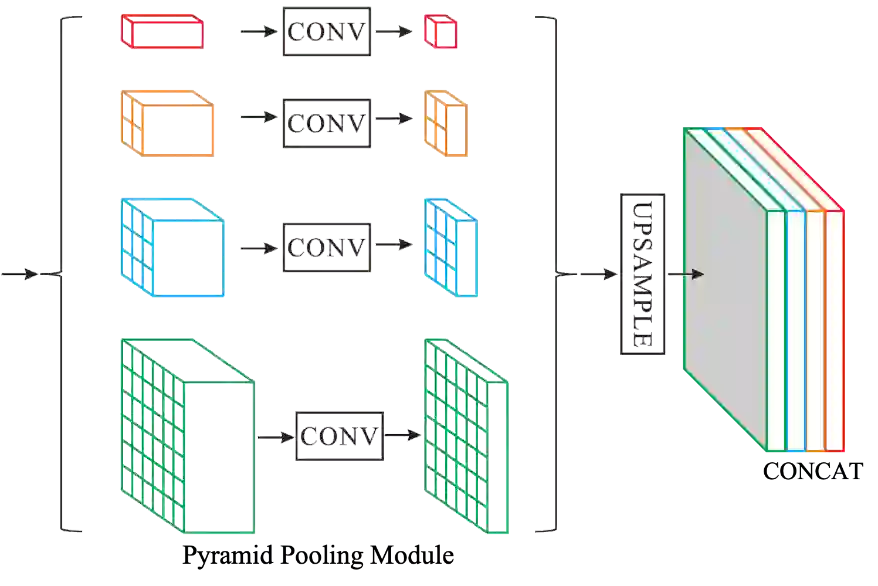
[22] Zhao, Hengshuang, et al. "Pyramid Scene Parsing Network." computer vision and pattern recognition (2017): 6230-6239.
[23] Li, Zeming, et al. "Light-Head R-CNN: In Defense of Two-Stage Object Detector." arXiv: Computer Vision and Pattern Recognition (2017).
[24] Wang, Jun, Xiang Li, and Charles X. Ling. "Pelee: A Real-Time Object Detection System on Mobile Devices." neural information processing systems (2018): 1967-1976.