如何挖掘科学知识?UIUC最新WWW22教程-科学文献数据挖掘:现代自然语言处理技术:任务、数据和工具
TheWebConf是中国计算机学会(CCF)推荐的A类国际学术会议,由国际万维网会议委员会(IW3C2)和主办地地方团队合作组织,每年召开一次,今年是第31届会议。本年度论文录用率为17.7%,TheWebConf即将召开,来自Xuan Wang, Hongwei Wang, Heng Ji, Jiawei Han等学者的《现代自然语言处理科研数据挖掘》教程,值得关注!


本教程针对对科学网络挖掘的自然语言处理(NLP)技术感兴趣的研究人员和从业人员。探索网络上大量快速增长的科学文献对科学发现非常有益。然而,由于缺乏自然语言环境下的专业领域知识、科学写作中复杂的句子结构以及科学知识的多模态表示,科学网络挖掘尤其具有挑战性。
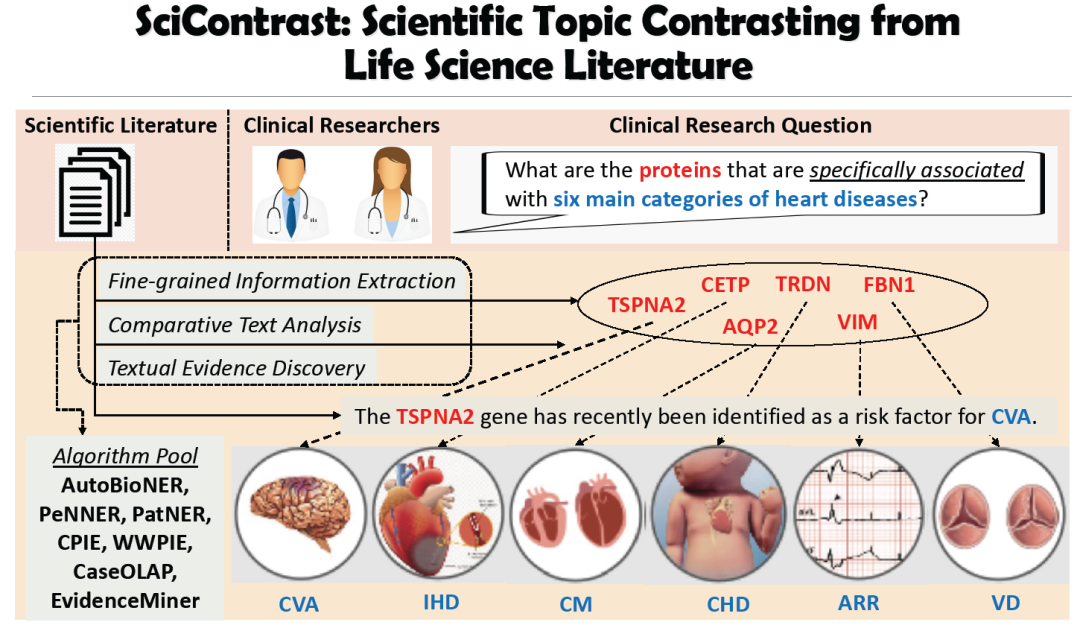
本教程全面介绍了在科学网络挖掘中使用自然语言处理技术的最新研究和发展,重点是生物医学和化学领域。首先,我们介绍了web挖掘在科学领域的动机和独特的挑战。然后讨论了一套从科学文献中有效地进行信息提取(命名实体识别、关系提取和事件提取)、信息检索(文本证据检索、跨模态分子检索和化学反应跟踪)的方法,以及它们在反应预测中的应用。最后,我们通过演示真实世界的数据集(COVID-19和有机化学文献),说明如何提取和检索信息,以及它们如何帮助进一步的探索性分析,来结束我们的教程。本文还讨论了自然语言处理技术在科学网络挖掘中的研究问题和未来发展方向。
https://xuanwang91.github.io/2021-12-19-www22-tutorial/
目录内容:
引言 Introduction [Slides]
科学信息抽取与分析,Scientific Information Extraction and Analysis [Slides]
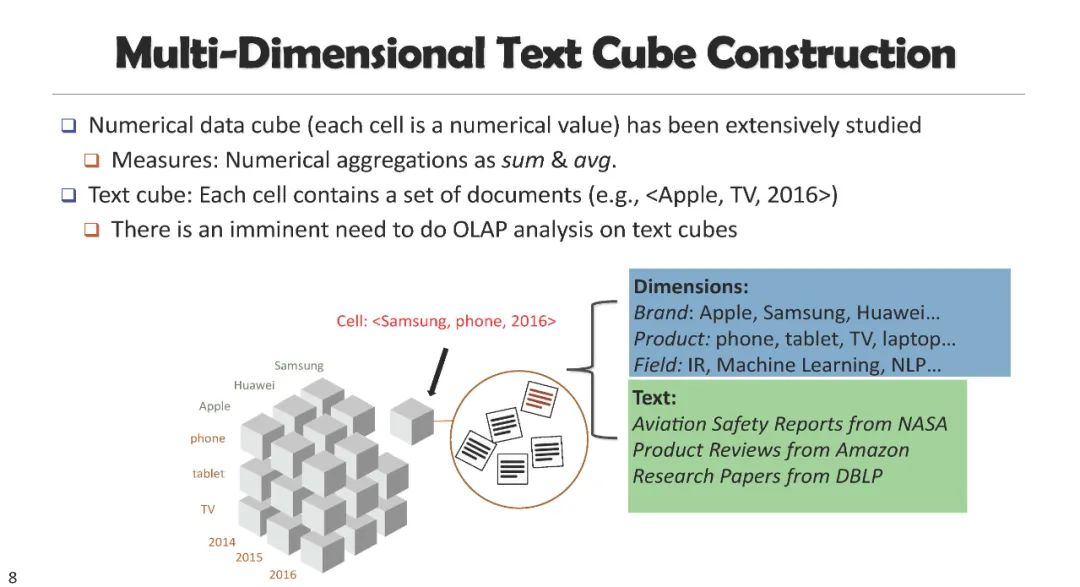
科学信息搜索与证据挖掘,Scientific Information Search and Evidence Mining [Slides]
总结与未来方向。Summary and Future Directions [Slides]
讲者:

Xuan Wang,伊利诺伊大学厄巴纳-香槟分校计算机科学系博士生。她的研究方向是在最少人工监督的情况下,从大量非结构化语料库中挖掘和构建结构化知识,强调在生物和健康科学中的应用。她分别于2017年和2015年获得伊利诺伊大学厄巴纳香槟分校(University of Illinois at urbana - champae)的统计学硕士学位和生物化学硕士学位,并于2013年获得清华大学生物科学学士学位。她是2020-2021年YEE院士奖的获得者。

王鸿伟,伊利诺伊大学厄巴纳-香槟分校计算机科学系博士后。他的研究兴趣包括机器学习和数据挖掘,特别是图表示学习机制、算法,以及它们在现实数据挖掘场景中的应用,如知识图谱、推荐系统、社交网络和情感分析。2018年获上海交通大学计算机科学系博士学位,2014年获上海交通大学ACM班学士学位。他于2019年至2021年在斯坦福大学计算机科学系从事博士后研究。获2020年中国计算机学会优秀博士学位论文奖、2018年谷歌博士奖学金。

季姮,美国伊利诺伊大学厄巴纳香槟分校计算机系终身正教授。于清华大学获得学士和硕士学位,纽约大学获得博士学位。致力于自然语言处理研究,尤其是信息抽取和知识库构建。于2016和2017年被世界经济论坛选为年轻科学家以及全球未来计算委员会委员。她获得的奖项包括人工智能领域十大新星以及美国自然科学基金职业生涯奖。

Jiawei Han(韩家炜),是伊利诺伊大学厄巴纳-尚佩恩分校计算机科学系的Bliss教授。他因知识发现和数据挖掘研究方面的贡献而获得许多奖励,包括ACM SIGKDD创新奖(2004)、IEEE计算机学会技术成就奖(2005)和IEEE W.Wallace McDowell奖(2009)。他是ACM和IEEE会士。他还担任《ACM Transactions on Knowledge Discovery from Data》的执行主编(2006—2011)和许多杂志的编委,包括《IEEE Transactions on Knowledge and Data Engineering》和《Data Mining Knowledge Discovery》





专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NPSW” 就可以获取《如何挖掘科学知识?UIUC最新WWW22教程-科学文献数据挖掘:现代自然语言处理技术:任务、数据和工具》专知下载链接






