PAI通过流式机器学习算法解决实时热点新闻挖掘案例

感谢大家的支持,上一篇”脱裤子“创造了收视纪录。最近一直忙着PAI的产品化建设,终于,我们上线了业内首个工业级OnlineLearning功能,欢迎大家试用PAI的在线机器学习引擎,这是一次模型训练架构的颠覆,也是未来的机器学习发展趋势

(本实验会用到流式机器学习算法,正处于邀测状态,需要申请开通,目前只支持华北2(北京)区域)
PAI地址:https://data.aliyun.com/product/learn
流式机器学习算法申请:https://data.aliyun.com/paionlinelearning
打开新闻客户端,往往会收到热点新闻推送相关的内容。新闻客户端作为一个承载新闻的平台,实时会产生大量的
新闻,如何快速挖掘出哪些新产生的新闻会成为成为热点新闻,决定着整个平台的新闻推荐质量。

如何从平台中海量的新闻素材中找到最有潜力成为热点的新闻需要使用机器学习相关的算法,传统做法是将每天获取的历史咨询下载并且离线训练模型,再将生成的热点发现模型推上线供第二日使用。但是这种离线训练所生成的模型往往缺乏时效性的属性,因为每天热点新闻都是实时产生的,用过去的模型预测实时产生的数据显然是缺乏对数据时效性的理解。
针对这种场景,PAI平台开创性的提出来Online-Learning的解决方案,通过流式算法和离线算法的结合,既能够发挥离线训练对大规模数据的强大处理能力,又能够发挥流式机器学习算法对实时模型的更新能力,做到流批同跑,完美解决模型时效性的问题。今天就以实时热点新闻挖掘案例为例,为大家介绍PAI OnlineLearning的解决方案。
实验流程
1.切换新版
进入PAI后,点击“体验新版”按钮即可开启试用(目前OnlineLearning只支持新版,且与旧版不兼容)可在模板中一键创建类似于本文介绍的案例,数据和流程都已经内置,开箱即用
模板打开,点击运行后效果(模板目前为简化版本)
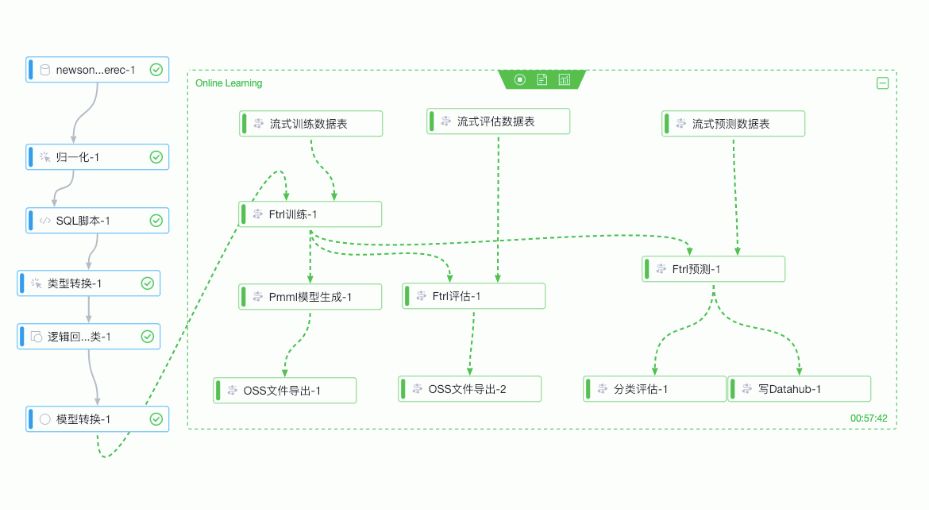
2.实验流程介绍
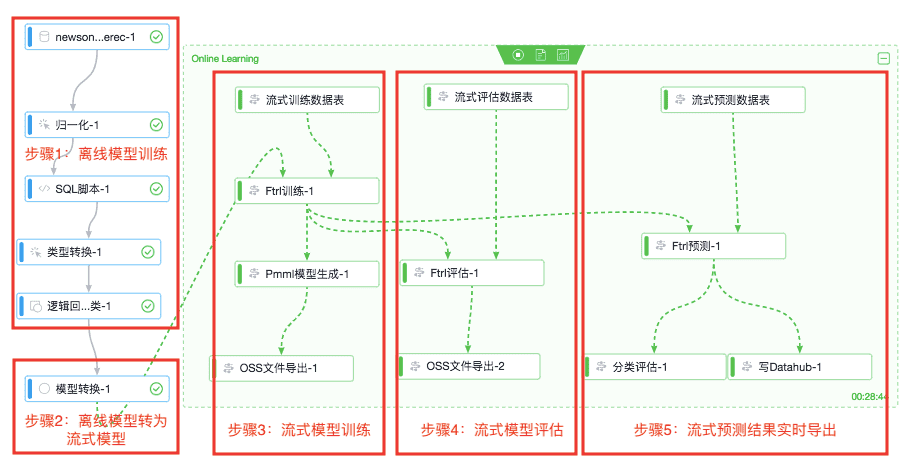
(注:PAI中离线计算组件用蓝色标识,流式计算组件由绿色标识,流式组件相连将形成计算组,因为流式组件需要多个组件的运行停止状态一致)
步骤1:离线模型训练
本文使用的数据是3万条来自UCI开放数据集提供的新闻文本数据。
地址:https://archive.ics.uci.edu/ml/datasets/Online+News+Popularity
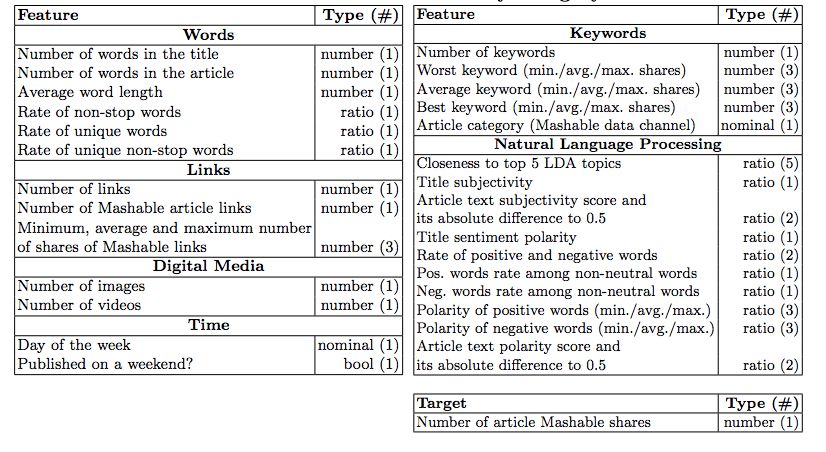
数据组成:包含新闻的URL以及产生时间,另外还包含了58个特征以及1个目标值,目标值“share”是新闻的分享次数,建模过程中将share字段利用sql组件处理成一个二分类问题,新闻share次数超过10000次为热点新闻,小于10000次为非热门新闻
特征的组成如下图所示:
利用逻辑回归模型训练生成一个二分类模型,这个模型用来评估新闻是否会成为热点新闻。
(注:目前PAI OnlineLearning只支持逻辑回归算法)
步骤2:离线模型转换成流式模型
通过“模型转换”组件,可以将离线生成的逻辑回归模型转换成流式算法可读取的流式模型。
步骤3:流式模型训练
从步骤3开始就进入了流式算法组件的步骤,PAI平台提供多种流式数据源,本案例以Datahub为例。
Datahub地址:https://datahub.console.aliyun.com/datahub
Datahub是一种流式数据对列,支持JAVA、PYTHON等多种语言采集方式,在具体使用过程中可以通过Datahub链接用户实时产生的数据以及PAI的训练服务。注意:Datahub输入的数据流格式需要与离线训练的数据流的字段完全一致,这样才可以对离线的模型进行实时更新。
Ftrl训练组件:左侧输入的是转化为流式的离线模型,右侧输入是流式数据表
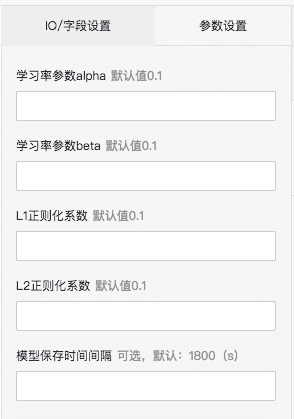
FTRL算法基本等同于流式的逻辑回归算法,在使用过程中需要按照LR算法配置参数,需要注意”模型保存时间间隔参数“的配置,这个参数决定了实时计算产生模型的时间周期。
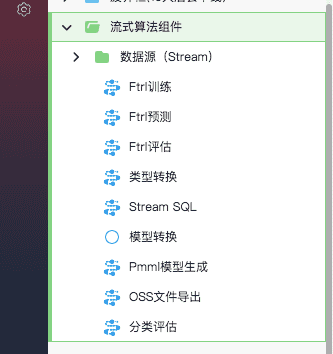
新版PAI已经内置了大量流式算法组件:
####
PMML模型生成组件:将输出的模型转化成PMML格式
OSS文件导出:将模型导出到用户自己的OSS中,可以自己设置名称的前缀和后缀,生成模型可在OSS中查看,如下图

步骤4:流式模型评估
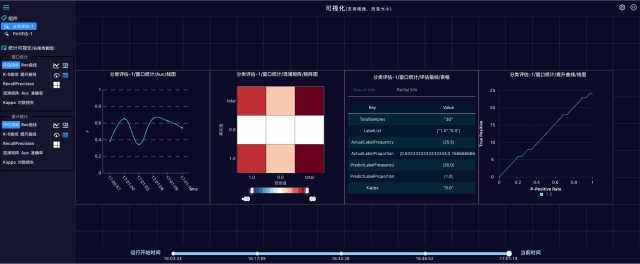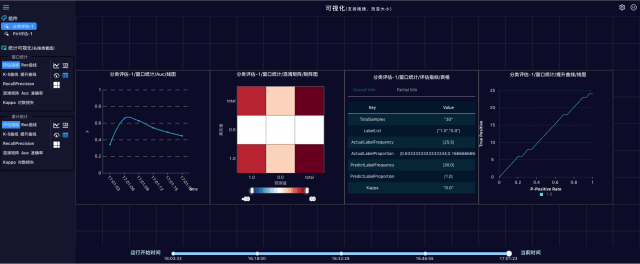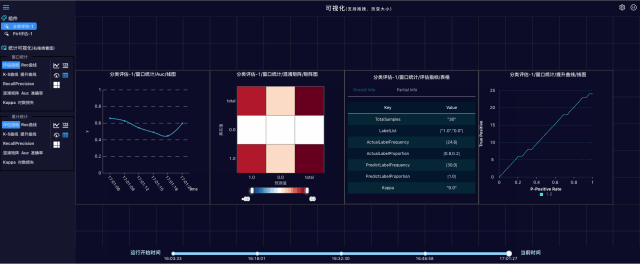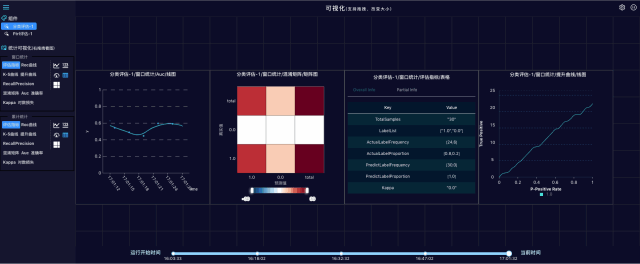
流式模型评估指的是利用评估数据对Ftrl训练生成的模型进行评估,输出的评估指标也可以写入OSS,评估指标与模型一一对应。每个模型和评估指标都有一个ID,如果ID一致,说明模型和评估指标是对应关系,如下图:

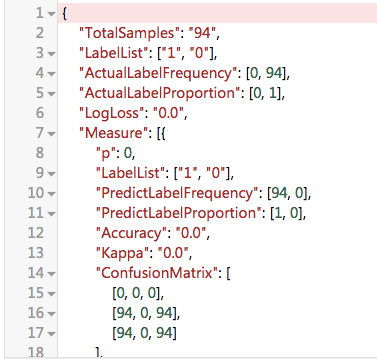
评估指标是一个json格式文件,包含精确率、准确率、混淆矩阵等指标:
步骤5:流式预测结果实时导出
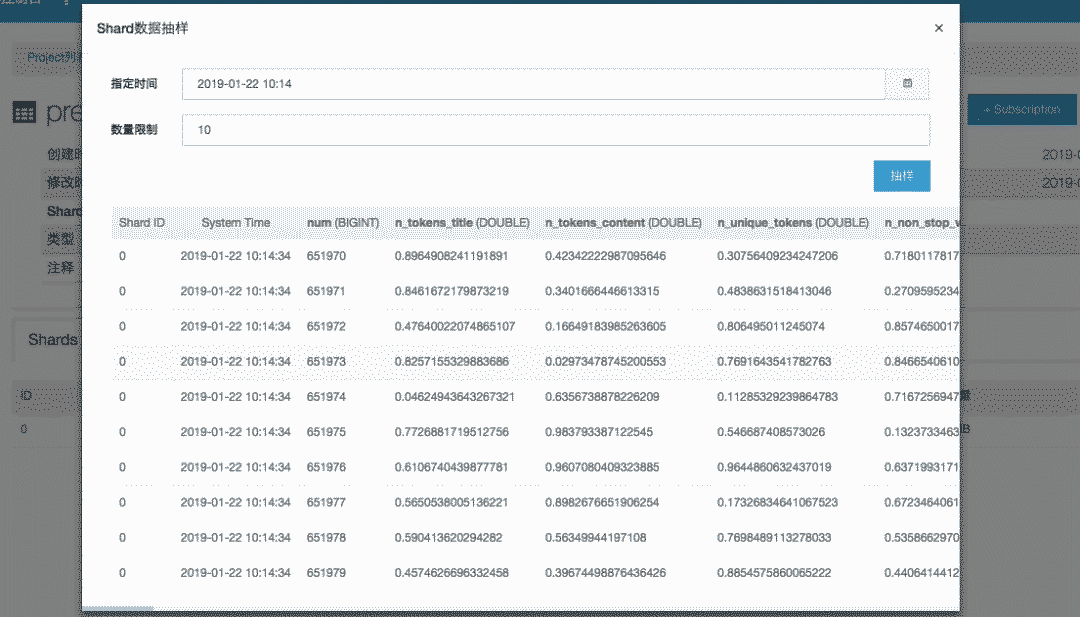
可以利用实时生成的模型做实时数据预测,实时的预测结果可以写出到datahub中,如下图:
同时如果输入的预测数据集包含label,还可以添加分类评估组件,可以打开组关系中的最右边按钮:

打开实时的流式预测结果评估页面:
3.模型使用介绍
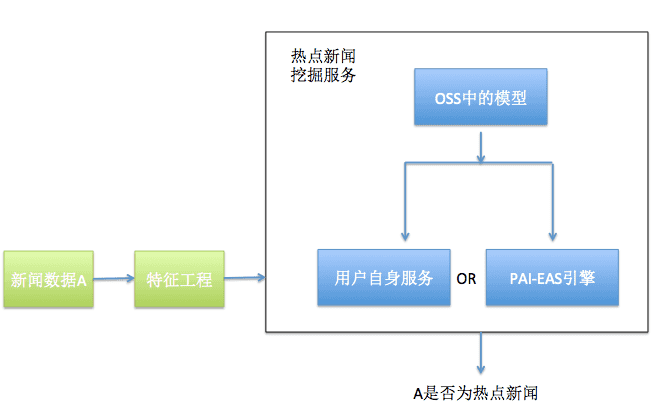
通过以上步骤已经产生了新闻热点预测模型,生成的模型已经存入OSS,可以直接在PAI-EAS在线预测服务引擎进行部署也可以下载下来在本地预测引擎使用。新闻数据进来后先要做特征工程(同”步骤1:离线模型训练“中的特征处理方式),然后将特征工程处理结果输入”热点新闻挖掘服务“,将会返回新闻是否是热点新闻。
总结
通过本文的案例,实现了将离线历史数据生成LR模型推送到实时训练环境,再利用实时生成的数据对模型进行更新, 这种实时训练的架构可以完美解决实时热点新闻对于新闻推荐模型的影响问题。欢迎大家试用并给出建议。

珍惜每一刻每一秒
去充实自己

微信号:凡人机器学习



