了解 GPT、Gemini 等大型语言模型的原理(通俗易懂)
《How Large Language Models Work》(大型语言模型的工作原理)将多年关于大型语言模型(LLMs)的专家研究成果,转化为一本可读性强、内容聚焦的入门读物,帮助你掌握这些令人惊叹的系统。书中清晰解释了 LLM 的工作机制,介绍了优化与微调方法,以及如何构建高效、可靠的 AI 应用流程和管道。
**你将在本书中学到:
如何测试与评估 LLM * 如何使用人类反馈、监督微调和检索增强生成(RAG)技术 * 如何降低错误输出、高风险失误和自动化偏差的风险 * 如何构建人机交互系统 * 如何将 LLM 与传统机器学习方法相结合
本书由 Booz Allen Hamilton 的顶尖机器学习研究人员撰写,包括研究员 Stella Biderman、AI/ML 研究总监 Drew Farris 和新兴 AI 研究总监 Edward Raff。他们用通俗易懂的语言,深入浅出地讲解了 LLM 和 GPT 技术的运作原理,适合所有读者阅读和理解。
技术背景介绍
大型语言模型为“人工智能”中的“I”(智能)赋予了实质含义。通过连接来自数十亿文档中的词语、概念与模式,LLM 能够生成类似人类的自然语言回应,这正是 ChatGPT、Claude 和 Deep-Seek 等工具令人惊艳的原因所在。在这本内容翔实又富有趣味的书中,来自 Booz Allen Hamilton 的全球顶尖机器学习研究人员将带你探讨 LLM 的基本原理、机遇与局限,并介绍如何将 AI 融入组织与应用中。
图书内容简介
《How Large Language Models Work》将带你深入了解 LLM 的内部运作机制,逐步揭示从自然语言提示到清晰文本生成的全过程。书中采用平实语言,讲解 LLM 的构建方式、错误成因,以及如何设计可靠的 AI 解决方案。同时你还将了解 LLM 的“思维方式”、如何构建基于 LLM 的智能体与问答系统,以及如何处理相关的伦理、法律与安全问题。
**书中内容包括:
如何定制 LLM 以满足具体应用需求 * 如何降低错误输出和偏差风险 * 破解 LLM 的常见误解 * LLM 在语言处理之外的更多能力
适读人群
无需具备机器学习或人工智能相关知识,初学者亦可放心阅读。
作者简介
Edward Raff 是 Booz Allen Hamilton 的新兴 AI 总监,领导该公司机器学习研究团队。他在医疗、自然语言处理、计算机视觉和网络安全等多个领域从事 AI/ML 基础研究,著有《Inside Deep Learning》。Raff 博士已在顶级 AI 会议发表超过 100 篇研究论文,是 Java Statistical Analysis Tool 库的作者,美国人工智能促进协会资深会员,曾两度担任“应用机器学习与信息技术大会”及“网络安全人工智能研讨会”主席。他的研究成果已被全球多个杀毒软件厂商采纳并部署。 Drew Farris 是一位资深软件开发者与技术顾问,专注于大规模分析、分布式计算与机器学习。曾在 TextWise 公司工作,开发结合自然语言处理、分类与可视化的文本管理与检索系统。他参与多个开源项目,包括 Apache Mahout、Lucene 和 Solr,并拥有雪城大学信息学院的信息资源管理硕士学位与计算机图形学学士学位。 Stella Biderman 是 Booz Allen Hamilton 的机器学习研究员,同时担任非营利研究机构 EleutherAI 的执行董事。她是开源人工智能的重要倡导者,参与训练了多个世界领先的开源 AI 模型。Biderman 拥有佐治亚理工学院计算机科学硕士学位,以及芝加哥大学的数学与哲学学士学位。
目录一览
大局观:LLM 是什么? 1. 分词器:LLM 如何“看”世界 1. Transformer:输入如何变成输出 1. LLM 是如何学习的 1. 如何约束 LLM 的行为 1. 超越自然语言处理 1. 对 LLM 的误解、局限与能力 1. 如何用 LLM 设计解决方案 1. 构建与使用 LLM 的伦理问题





摘要——AI 智能体正在经历一场范式转变:从早期由强化学习(Reinforcement Learning, RL)主导,到近年来由大语言模型(Large Language Models, LLMs)驱动的智能体兴起,如今正进一步迈向 RL 与 LLM 能力融合的协同演进。这一演进过程不断增强了智能体的能力。然而,尽管取得了显著进展,要完成复杂的现实世界任务,智能体仍需具备有效的规划与执行能力、可靠的记忆机制,以及与其他智能体的流畅协作能力。实现这些能力的过程中,智能体必须应对始终存在的信息复杂性、操作复杂性与交互复杂性。针对这一挑战,数据结构化有望发挥关键作用,通过将复杂且无序的数据转化为结构良好的形式,从而使智能体能够更有效地理解与处理。在这一背景下,图(Graph)因其在组织、管理和利用复杂数据关系方面的天然优势,成为支撑高级智能体能力所需结构化过程的一种强大数据范式。
为此,本文首次系统性地回顾了图如何赋能 AI 智能体。具体而言,我们探讨了图技术与智能体核心功能的融合方式,重点介绍了典型应用场景,并展望了未来的研究方向。通过对这一新兴交叉领域的全面综述,我们希望激发下一代智能体系统的研究与发展,使其具备利用图结构应对日益复杂挑战的能力。相关资源可在附带的 Github 链接中获取,并将持续更新以服务社区。
关键词:图、图学习、智能体、大语言模型、强化学习、综述
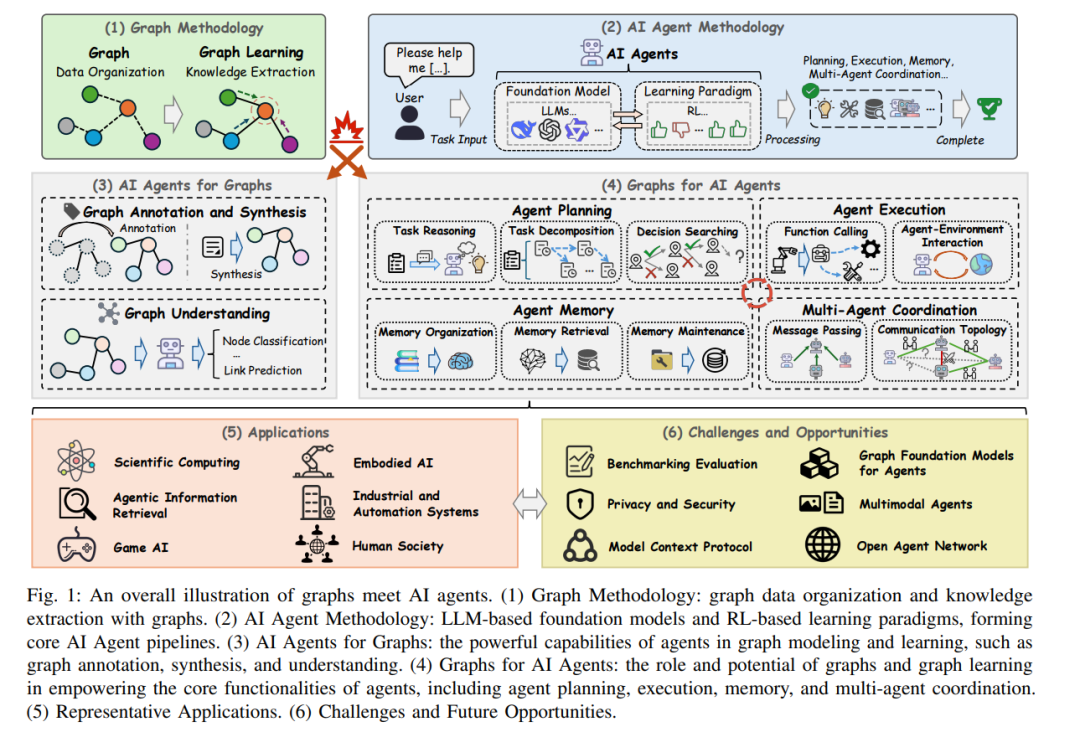
一、引言
在人工智能(AI)快速演进的浪潮中,AI 智能体因其在任务自动化处理方面的巨大潜力而受到广泛关注。智能体的发展历程经历了从早期基于强化学习(Reinforcement Learning, RL)的架构 [1], [2],到近年来由大语言模型(Large Language Models, LLMs)驱动的智能体 [3], [4],再到最新融合 LLM 作为知识基础与 RL 作为任务特定学习范式的紧耦合架构 [5],标志着智能体能力的一次重大飞跃。这一演进使得智能体能够利用 LLM 所蕴含的广泛世界知识理解复杂任务,并通过 RL 优化实现对任务的精准处理。 执行复杂现实任务的 AI 智能体往往需要具备多样化的能力 [6], [7]。高效的任务导航依赖于诸多智能体功能,例如精细化的规划能力、结合外部工具的精确执行能力、可靠的记忆机制,以及与其他智能体的高效协同能力 [8], [9]。然而,由于任务复杂性的存在,智能体在这些功能中常常面临信息、操作符以及交互的错综复杂与混乱无序。因此,亟需一种有效方式来组织和管理所遇数据,以便智能体能够更好地理解和高效处理,从而提升其应对复杂任务的能力。例如,在规划阶段,智能体需要解析非结构化的任务描述并将其重组为可执行的子任务计划;在执行过程中,需合理编排多种外部工具以兼顾效率与准确性;在记忆管理中,需有序整理庞大的内容以便有用信息得以保留并可快速检索;而在多智能体协作中,则需确定合适的协同拓扑结构,以实现有效的信息传递。在面对非结构化数据时,传统智能体通常只能在学习过程中隐式捕捉其中潜在的关联。基于数据中固有的有益关系,采用图为基础的显式建模结构化方法成为应对这一挑战的有前景途径,能够将原始而复杂的输入转化为简洁有序的形式,从而提升智能体的理解力与处理效率。这类结构化信息有助于智能体探索复杂任务并做出更具信息性的决策。 图在各类领域中已展现出广泛的适用性 [10]–[12],并被证明是管理数据、组织含有有价值关系信息的一种强大范式。在构建好的图基础上,图学习(Graph Learning)进一步通过对结构化信息的学习展现出显著成效 [13], [14]。具体而言,图通过将实体表示为节点、显式或隐式关系建模为边,提供了一种有效的数据组织方式。一个合适的图结构是实现智能体数据组织的关键。图结构的构建具有高度灵活性,可根据特定环境、任务、操作符与应用需求自定义图结构 [15]–[17],也可以利用现有的外部知识图谱 [18], [19]。这种灵活性使得图能够广泛嵌入于多种智能体及其多样化功能中。在构建好的图之上,图学习技术还可进一步提供一个强大的知识提取框架,帮助智能体捕捉复杂关系与有意义的信息。这使得图技术成为增强 AI 智能体在复杂场景下能力的理想手段。因此,图与智能体的交叉融合有望大幅提升其对结构化信息的处理与利用能力,进而赋能其在规划、执行、记忆与多智能体协作等方面的关键功能。 分类框架:本综述系统性地探讨了图在信息、操作符与多模型结构化组织中的作用,涵盖了从基于 RL 的智能体到基于 LLM 的智能体范式。考虑到 RL 技术与 LLM 基础模型日益紧密的融合,我们在分析中并未刻意区分图学习在这两类智能体架构中的作用,而是如图 1 所示,从智能体核心功能出发,以图赋能为主线展开讨论。我们重点关注图学习如何增强智能体的四大关键功能:规划、执行、记忆与多智能体协作。此外,本综述还探讨了智能体反过来如何促进图学习技术的发展。最后,在全面回顾的基础上,我们梳理了潜在的应用前景与关键的未来研究方向。通过综述该领域的系统洞察,我们旨在推动新一代能够利用结构化知识应对日益复杂挑战的 AI 智能体的发展。 在本文所探讨的背景下,现有综述主要集中于图技术在强化学习中的应用价值 [20], [21]。而随着 LLM 的快速发展,图学习也被视为提升其能力的有效技术,已有若干综述对该方向进行过探讨 [22], [23]。然而,尽管已有贡献,目前仍缺乏一项系统性地阐述图如何在智能体不同功能中发挥作用的综述。据我们所知,本文为首个系统性探索图技术与智能体多维操作交叉点的研究综述。我们希望通过全面回顾,为构建下一代图赋能智能体提供有价值的研究参考与启发。 本文的主要贡献如下: * 本文首次全面综述了图技术与 AI 智能体之间这一强大而充满潜力的交叉方向; * 我们提出了一种新的分类方法,系统化地梳理了图在智能体不同核心功能(规划、执行、记忆与协作)中的作用,并探讨了智能体如何反过来推动图学习的发展; * 基于本综述,我们进一步分析了图赋能智能体的应用前景、关键挑战以及未来研究方向。
文章结构如下:第二节介绍与本综述相关的基础知识;第三至第七节将根据提出的分类方法,详述各项相关研究;第八与第九节分别探讨图与智能体交叉领域中的潜在应用与未来机会;第十节对全文进行总结归纳。
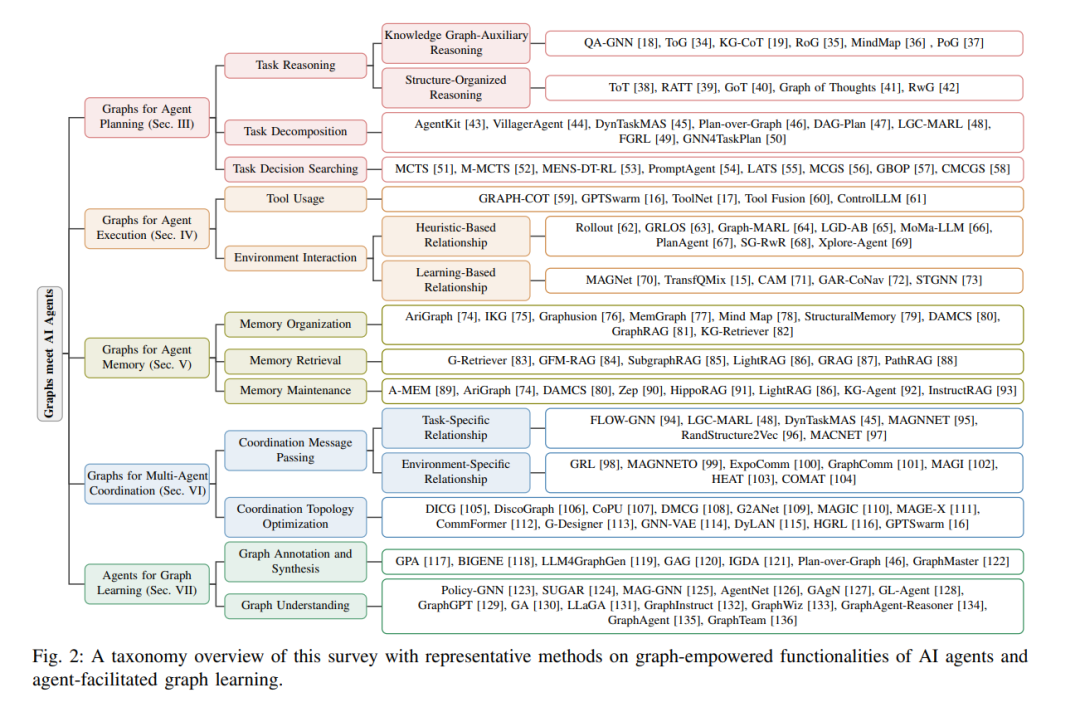
本文提出了一种全新的分类方法,用于系统地探讨图技术与 AI 智能体如何实现相互增强,如图 2 所示。具体而言,在第 III 至第 VI 节中,我们介绍了图学习如何支持智能体的核心功能,包括规划(第 III 节)、执行(第 IV 节)、记忆(第 V 节)以及多智能体协作(第 VI 节)。通过将图与智能体功能之间的协同点加以细分,不仅契合了智能体系统设计中的自然模块化特征,也凸显了图技术在每项功能中所蕴含的独特潜力。 此外,在第 VII 节中,我们进一步探讨了智能体范式如何反过来促进图学习的发展。通过明确考虑这一反向作用,即基于智能体范式如何反哺图学习过程,我们强调了双向创新的重要性,并倡导一种整体视角,即图与智能体协同演化、深度融合,从而激发出超越单向整合的新方法论。 基于这一结构清晰的分类框架,我们将在第 VIII 与第 IX 节中进一步讨论相关应用与未来研究机遇。


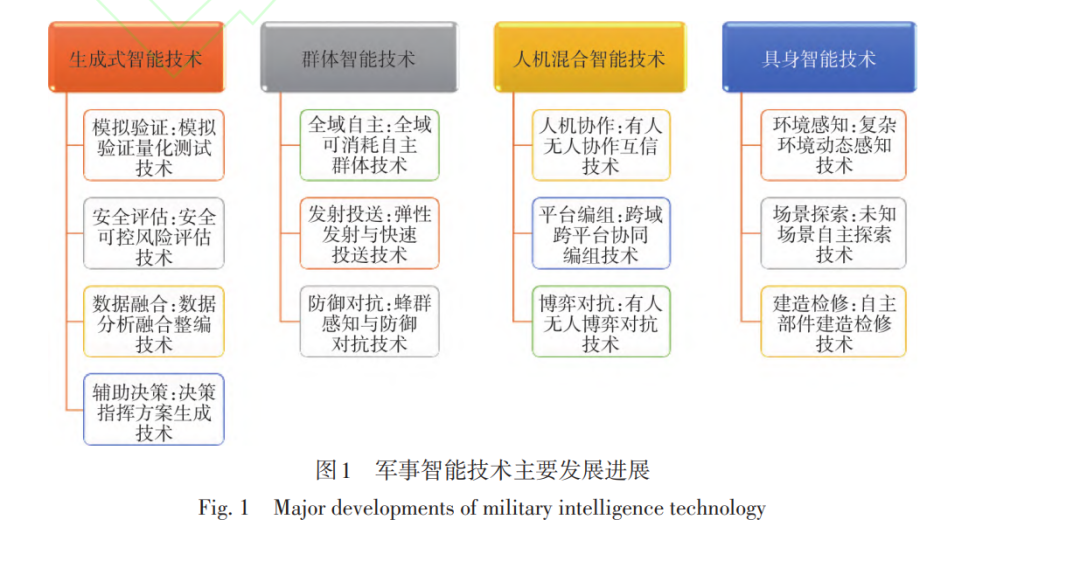
摘 要:人工智能技术作为推动现代战争向智能化战争转型的重要变量,正在深刻改变战争形 态和方式。梳理和总结了2024年人工智能技术在军事智能领域的最新科技进展。综述表明:美、欧 在持续加强人工智能顶层设计、研发投入、机构改革的同时,开始逐渐从安全、成本等角度审视和 调整相关人工智能战略;生成式智能、群体智能、人机混合智能、具身智能等人工智能技术在军事 领域保持较高发展热度,并产出众多里程碑式成果,引领智能无人平台自主感知与跨域协同的军事 智能技术发展趋势;同时,世界主要军事强国正快速将军事智能广泛应用于陆战、海战、空战等多 作战域;未来,类人化数理与因果逻辑推理、全局和本地协同化模型训练、边缘侧低资源模型部署 与推理、大小模型弹性融合实施等,将成为军事智能技术的重要发展方向。 关键词:人工智能;军事智能;生成式智能;群体智能;人机混合智能;具身智能


报告深入探讨了人工智能技术在多个行业中的应用现状与未来趋势,为政府、企业及相关研究机构提供了详尽的数据支持和战略建议。
首先,报告从宏观角度出发,分析了全球及中国的人工智能产业发展背景,指出随着计算能力的提升、大数据时代的到来以及算法模型的不断优化,AI正以前所未有的速度改变着各行各业。接着,通过对智能制造、智慧医疗、金融科技、智慧城市等领域的具体案例研究,展示了AI如何通过提高效率、降低成本来推动产业升级转型,并指出了当前面临的主要挑战,如数据安全问题、伦理道德考量等。
此外,还特别强调了跨学科融合对于促进AI创新的重要性,呼吁加强基础科学研究与应用实践之间的联系。最后,报告提出了构建开放合作生态系统的倡议,鼓励社会各界共同参与制定行业标准、培养专业人才,以实现更加健康可持续的发展模式。
整体而言,这份研究不仅全面反映了现阶段我国乃至全世界范围内“人工智能+”行业的最新进展,也为相关从业者把握机遇、应对风险提供了重要参考。








**
**








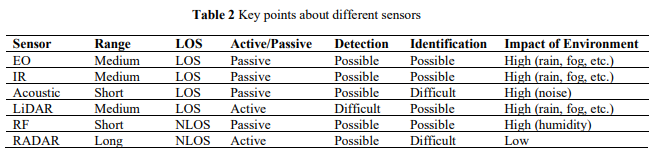
确保私营机构、公共机构及国家机构安全的首要任务,是具备可靠应对恶意低空、慢速、小型(LSS)无人机系统(UAS)的能力。无论和平或战争时期,全球诸多案例——诸如机场空域屡遭入侵、针对民众的未遂袭击,以及当前乌克兰冲突事件——均印证此类无人机构成的关键威胁。本综述整合现役反无人机系统(C-UAS),涵盖传感器与(低附带损伤)效应器组件,并在可行时对比实战经验与技术预期成效。
本研究范畴内,典型C-UAS系统架构包含三个子系统:(i)传感器系统、(ii)效应器系统、(iii)C2指挥控制系统。由单组或多组传感器构成的传感系统,负责采集环境信息(含背景与目标数据);由单组或多组拦截单元构成的效应系统,承担瘫痪、摧毁或接管敌识无人机的任务;C2系统贯通上述两子系统:基于传感器情报决策最优效应方案以达成效能最大化。认知C-UAS系统所用传感器/效应器特性,以及不同外部参数对系统效能的影响,是构建最适系统的关键要素。即便突发意外状况,C2交互界面也应确保传感器/效应器协同最大化“杀伤链”成功率。本节旨在初步展示反无人机系统中各类传感器与效应器技术。


几十年前,Mumford 曾写道,代数几何“似乎已经获得了一个声誉:它晦涩难懂、门槛极高、抽象无比,其拥护者似乎正密谋接管数学的其他所有分支。”如今,这场革命已全面到来,并从根本上改变了我们对许多数学领域的理解方式。本书为读者提供了这一变革性思想体系的坚实基础,通过非正式但严谨的讲解方式,帮助读者在掌握强大技术工具的同时建立直观理解。 本书以范畴思维和层的讨论为起点,逐步引出“几何空间”的概念,并以概型和簇为代表展开阐述,随后进一步讨论这些几何对象的具体性质。接下来的章节涵盖了维数与光滑性、向量丛及其自然推广、重要的上同调工具及其应用等主题。对于一些关键但进阶的内容,书中也通过带星号的部分进行了补充。 主要特色包括:
提供全面系统的入门指导,有望成为该领域的权威教材; * 包含丰富的练习,强调“做中学”的学习方式; * 几乎不设前置要求,从范畴论和层论一直发展到交换代数与上同调代数,构建学生所需的全部工具; * 采用以实例为驱动的方式,帮助建立扎实的数学直觉; * 既是面向研究生的自包含教材,也是研究人员的重要参考书籍。








摘要——强化学习(Reinforcement Learning, RL)是解决序列决策问题的重要机器学习范式。近年来,得益于深度神经网络的快速发展,该领域取得了显著进展。然而,当前RL的成功依赖于大量训练数据和计算资源,且其跨任务泛化能力有限,制约了其在动态现实环境中的应用。随着持续学习(Continual Learning, CL)的兴起,持续强化学习(Continual Reinforcement Learning, CRL)通过使智能体持续学习、适应新任务并保留既有知识,成为解决上述局限性的重要研究方向。本文对CRL进行了系统梳理,围绕其核心概念、挑战和方法展开论述:首先,详细回顾现有研究,对其评估指标、任务设定、基准测试和场景配置进行归纳分析;其次,从知识存储/迁移视角提出新的CRL方法分类体系,将现有方法划分为四种类型;最后,剖析CRL的特有挑战,并为未来研究方向提供实践性见解。 关键词——持续强化学习,深度强化学习,持续学习,迁移学习
一、引言
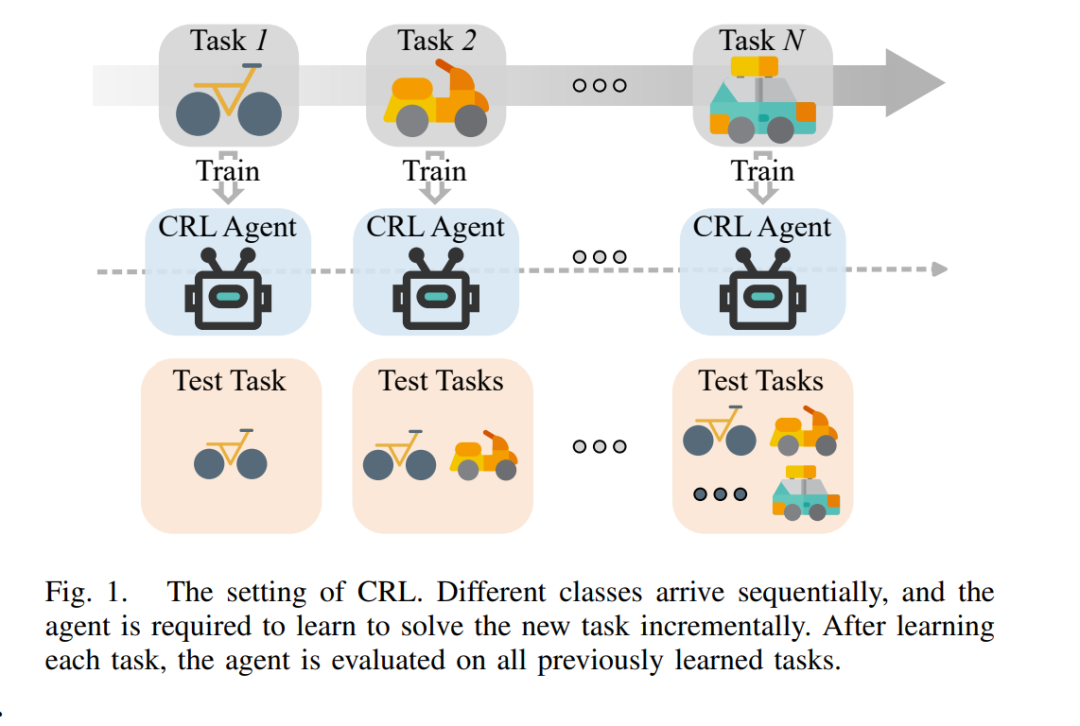
强化学习(Reinforcement Learning, RL)已成为机器学习中的一种强大范式,使智能体能够通过与环境的交互学习最优的决策策略 [1]。当强化学习与深度神经网络的表示学习能力相结合时,便产生了深度强化学习(Deep Reinforcement Learning, DRL),其在多个领域取得了显著的成功 [2]。DRL 展现了在解决高维复杂决策问题方面的巨大潜力,从精通国际象棋、日本将棋和围棋等棋类游戏 [3],到推动科学发现,如蛋白质结构预测 [4]、量子计算误差校正 [5],以及大型语言模型的训练 [6],[7]。此外,DRL 也被广泛应用于现实世界中的控制任务,如热电联产系统优化 [8]、托卡马克核聚变反应堆中等离子体配置控制 [9],以及实现安全的自动驾驶 [10]。 尽管 DRL 已取得诸多成就,但其当前的成功主要归因于在特定任务上学习固定策略的能力,通常需要大量的训练数据和计算资源 [11]。这为 DRL 在现实应用中的部署带来了重大挑战。具体来说,现有的 DRL 算法普遍缺乏跨任务高效迁移知识或适应新环境的能力。面对新任务时,这些算法通常需要从头开始学习,导致样本效率低下以及泛化能力差 [12]–[14]。 为应对上述挑战,研究人员开始探索如何使 RL 智能体避免灾难性遗忘并有效迁移知识,其最终目标是推动该领域向更具类人智能的方向发展。人类在解决新任务时,能够灵活地利用已有知识,同时不会显著遗忘已掌握的技能 [15]。受到这一能力的启发,持续学习(Continual Learning, CL),又称终身学习或增量学习,旨在构建能够适应新任务并保留过往知识的学习系统 [16]–[19]。CL 面临的核心挑战在于稳定性与可塑性的平衡——即在维持已学知识稳定性的同时,又具备足够的灵活性来适应新任务。其总体目标是构建能在整个生命周期内持续学习和适应的智能系统,而不是每次面对新任务时都从零开始。当前 CL 的研究主要聚焦于两个方面:灾难性遗忘的缓解以及知识迁移的实现。灾难性遗忘指的是学习新任务会导致模型覆盖并遗失先前已学任务的知识;而知识迁移则是指利用过往任务中积累的知识来提升新任务(甚至是已见任务)的学习效率与表现。成功解决这两个问题对于构建稳健的持续学习系统至关重要。 持续强化学习(Continual Reinforcement Learning, CRL),又称终身强化学习(Lifelong Reinforcement Learning, LRL),是 RL 与 CL 的交叉领域,旨在突破当前 RL 算法的多种局限,构建能够持续学习并适应一系列复杂任务的智能体 [20],[21]。图 1 展示了 CRL 的基本设置。与传统 DRL 主要聚焦于单一任务性能最优化不同,CRL 更强调在任务序列中保持并增强泛化能力。这种焦点的转变对于将 RL 智能体部署于动态、非平稳环境中尤为关键。 需要指出的是,“lifelong” 与 “continual” 两个术语在 RL 文献中常被交替使用,但不同研究中的定义与使用方式可能存在显著差异,从而引发混淆 [22]。一般而言,大多数 LRL 研究更强调对新任务的快速适应,而 CRL 研究更关注避免灾难性遗忘。本文采用更广义的 CRL 作为统一术语,呼应当前 CL 研究中同时兼顾这两个方面的趋势。 CRL 智能体需实现两个核心目标:(1)最小化对先前任务知识的遗忘;(2)利用已有经验高效学习新任务。达成这两个目标将有助于克服 DRL 当前的局限,推动 RL 技术向更广泛、更复杂的应用场景拓展。最终,CRL 旨在实现类人的终身学习能力,使其成为推动 RL 研究的重要方向。 目前,关于 CRL 的综述工作仍相对较少。部分综述文献 [18],[23] 对 CL 领域进行了全面回顾,包括监督学习与强化学习。值得注意的是,Khetarpal 等人 [21] 从非平稳 RL 的视角对 CRL 进行了综述,首先对通用 CRL 问题进行了定义,并通过数学刻画提出了不同 CRL 形式的分类体系,强调了非平稳性所涉及的两个关键属性。然而,该综述在 CRL 中的一些重要方面——如挑战、基准测试与场景设置等——缺乏详细的对比与讨论,而这些因素对于指导实际研究至关重要。此外,过去五年中 CRL 方法数量快速增长。鉴于此,本文旨在系统回顾近年来关于 CRL 的研究工作,重点提出一种新的 CRL 方法分类体系,并深入探讨知识在 CRL 中的存储与迁移机制。 本综述深入探讨了 CRL 这一不断发展的研究领域,旨在弥合传统 RL 与现实动态环境需求之间的差距。我们全面审视了 CRL 的基本概念、面临的挑战与关键方法,系统性地回顾了当前 CRL 的研究现状,并提出了一套将现有方法划分为不同类别的新分类体系。该结构化方法不仅清晰地描绘了 CRL 研究的整体图景,也突出了当前的研究趋势与未来的潜在方向。我们还从策略、经验、动态与奖励等多个角度审视方法间的联系,为优化 CRL 的学习效率与泛化能力提供了细致的理解。此外,我们也关注推动 CRL 边界的新兴研究领域,并探讨这些创新如何助力构建更复杂的人工智能系统。 本综述的主要贡献体现在以下几个方面: 1. 挑战分析:我们强调了 CRL 所面临的独特挑战,提出其需要在可塑性、稳定性与可扩展性三者之间实现平衡; 1. 场景设定:我们将 CRL 场景划分为终身适应、非平稳学习、任务增量学习与任务无关学习,为不同方法提供了统一的对比框架; 1. 方法分类:我们提出了一种基于知识存储与迁移方式的新 CRL 方法分类体系,涵盖策略导向、经验导向、动态导向与奖励导向方法,帮助读者结构性地理解 CRL 策略; 1. 方法综述:我们对现有 CRL 方法进行了最全面的文献回顾,包括开创性工作、最新发表的研究成果以及有前景的预印本; 1. 开放问题:我们讨论了 CRL 当前的开放问题与未来研究方向,如任务无关的 CRL、评估与基准建设、可解释知识建模以及大模型的集成使用。
表 I 展示了本文的结构安排。接下来的内容如下:第二节介绍 RL 与 CL 的基础背景,有助于理解 CRL 的核心理念;第三节概述 CRL 的研究范畴,包括定义、挑战、评价指标、任务设置、基准与场景分类;第四节详细介绍我们提出的 CRL 方法分类体系,并回顾现有方法,按知识类型划分为策略导向(第四节 B)、经验导向(第四节 C)、动态导向(第四节 D)与奖励导向(第四节 E)四类;第五节探讨 CRL 的开放问题与未来发展方向;第六节为本文的总结与展望。



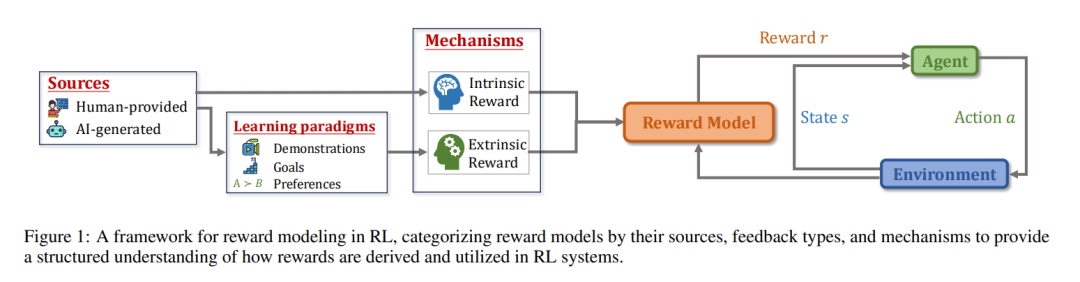
在强化学习(RL)中,智能体不断与环境交互,并利用反馈来改进其行为。为了引导策略优化,引入奖励模型作为期望目标的代理,使得当智能体最大化累积奖励时,也能切实满足任务设计者的意图。近年来,学术界和工业界的研究者都聚焦于构建既能与真实目标高度对齐,又能促进策略优化的奖励模型。 本文综述对深度强化学习领域中的奖励建模技术进行了系统回顾。我们首先介绍奖励建模的背景与基础知识;随后,以“来源”“机制”和“学习范式”为维度,对最新的奖励建模方法进行分类梳理;在此基础上,探讨这些技术的多种应用场景,并回顾评估奖励模型的常用方法。最后,我们总结了值得关注的未来研究方向。 总体而言,本综述涵盖了既有方法与新兴方法,填补了当前文献中缺乏系统性奖励模型综述的空白。
1 引言
近年来,**深度强化学习(Deep Reinforcement Learning, DRL)**这一结合了强化学习(RL)与深度学习(DL)的机器学习范式,在多个领域的应用中展现出巨大潜力。例如,AlphaGo [Silver et al., 2016] 展示了强化学习在博弈类场景中进行复杂决策的能力;InstructGPT [Ouyang et al., 2022] 强调了强化学习在对齐语言模型与人类意图中的不可替代作用;通过大规模强化学习训练的智能体,如 OpenAI-o1 和 DeepSeek-R1 [Guo et al., 2025],展现出了与人类相当甚至超越人类的推理智能。与监督学习(SL)中要求智能体模仿和复现数据集中的行为不同,强化学习的核心优势在于使智能体能够基于自身行为的结果进行探索、适应与优化,从而实现前所未有的自主性和能力。 奖励机制是强化学习的核心组成部分,实质上定义了任务中的目标,并引导智能体优化其行为以达成该目标 [Sutton et al., 1998]。正如多巴胺在生物系统中激励和强化适应性行为一样,强化学习中的奖励鼓励智能体探索环境,引导其朝向期望的行为发展 [Glimcher, 2011]。然而,尽管在研究环境中奖励函数通常是预先定义好的 [Towers et al., 2024],但在许多真实世界的应用中,奖励往往不存在或难以明确指定。因此,当代强化学习研究的一个重要方向,是如何从多种类型的反馈中提取有效的奖励信号,以便后续使用标准的强化学习算法对智能体策略进行优化。 尽管奖励建模在强化学习中扮演着至关重要的角色,现有的综述文献 [Arora and Doshi, 2021; Kaufmann et al., 2023] 通常聚焦于特定子领域,如逆强化学习(IRL)与基于人类反馈的强化学习(RLHF),而较少将奖励建模作为一个独立课题进行系统梳理。为填补这一空白,本文对奖励模型进行了系统性回顾,涵盖其理论基础、关键方法和在多种强化学习场景中的应用。我们提出了一个新的分类框架,用以回答以下三个基本问题: 1. 来源(The source):奖励来自哪里? 1. 机制(The mechanism):是什么驱动智能体的学习? 1. 学习范式(The learning paradigm):如何从不同类型的反馈中学习奖励模型?
此外,我们特别关注了基于基础模型(如大语言模型 LLMs 与视觉-语言模型 VLMs)的奖励建模的最新进展,该方向在已有综述中关注较少。本文所构建的奖励建模框架如图 1 所示。 具体而言,本文的结构安排如下: 1. 奖励建模背景(第2节):介绍强化学习与奖励模型的基础知识; 1. 奖励模型的分类(第3至第5节):提出奖励建模的分类框架,分别从来源(第3节)、学习驱动机制(第4节)以及学习范式(第5节)三个维度进行划分。同时,我们在表1中列出了近期相关文献,并依照该框架进行归类; 1. 应用与评估方法(第6与第7节):探讨奖励模型在实际场景中的应用,以及常用的评估方法; 1. 未来方向与讨论(第8节):总结全文,并展望该领域的潜在研究方向。



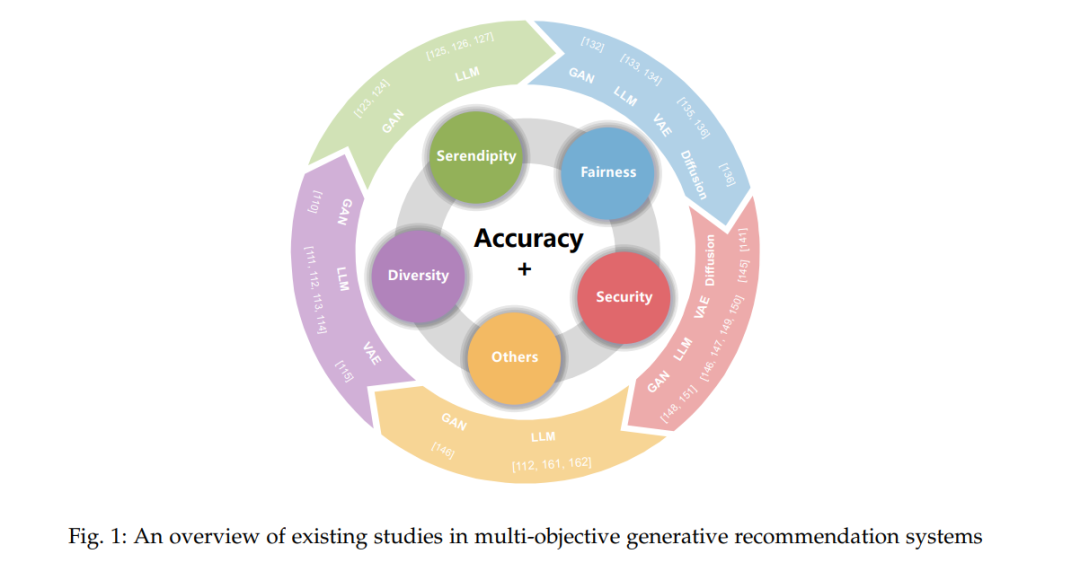
摘要——随着生成式人工智能(Generative AI)的快速发展,尤其是大语言模型的不断突破,推荐系统正朝着更具通用性的方向演进。与传统方法不同,生成式人工智能不仅能够从复杂数据中学习模式和表示,还具备内容生成、数据合成和个性化体验等能力。这种生成能力在推荐系统中发挥着关键作用,能够缓解数据稀疏问题,并提升系统的整体性能。当前,基于生成式 AI 的推荐系统研究已取得了丰富成果。与此同时,推荐系统的目标也已超越单一的准确性要求,催生了大量面向多目标优化的研究,试图在推荐中综合考虑多种目标。然而,据我们所知,目前尚缺乏基于生成式 AI 技术的多目标推荐系统的系统性综述研究,相关文献仍存在明显空白。为填补这一研究空缺,本文对融合生成式 AI 的多目标推荐系统研究进行了系统梳理,按照优化目标对现有工作进行分类整理。同时,我们总结了相关的评估指标和常用数据集,并进一步分析了该领域面临的挑战与未来发展方向。 关键词——多目标优化,推荐系统,生成式人工智能,大语言模型
1 引言 在大数据时代,推荐系统已成为应对信息过载问题的关键工具,帮助用户高效地发现有价值的内容。它们被广泛应用于音乐、新闻、职位推荐等多个领域 [1]–[3],通过过滤海量信息流,显著提升用户体验。推荐系统的发展已历经数十年,从最初的协同过滤方法 [4]–[7] 和内容推荐方法 [8], [9],到后来的混合模型 [10]、基于图神经网络的方法 [11],以及深度学习方法 [12], [13],不断演进以满足日益增长的个性化和可扩展性需求。
近年来,生成式人工智能(Generative AI)的突破显著改变了推荐系统的格局。正如文献 [14] 所指出的,基于生成技术的推荐系统已成为该领域的新兴研究方向。生成对抗网络(GANs)[15]、变分自编码器(VAEs)[16]、扩散模型 [17] 和大语言模型(LLMs)[18] 等技术,使得推荐系统能够更丰富地进行数据合成并实现更深层次的上下文理解。其中,大语言模型在处理多模态数据(文本、图像、视频)和生成上下文感知的推荐内容方面展现出强大能力,带来了前所未有的灵活性。与传统模型依赖历史数据预测用户偏好不同,生成模型可以模拟用户交互、增强稀疏数据集,并生成个性化内容,从而为推荐范式的创新开辟了新路径。
生成模型在推荐系统领域展现出巨大潜力。目前的研究主要集中在单一目标任务,例如通过合成数据提升准确性,或利用大语言模型增强可解释性。然而,对准确性的过度关注可能导致“过滤泡沫”(filter bubble)现象 [19],使用户被限制在重复或同质化的内容中,抑制探索行为并削弱长期参与度。考虑到生成式人工智能在推理和理解方面的先进能力,其在多目标推荐中的应用也极具前景。 研究社区已广泛探索在传统推荐系统框架下平衡多种目标的多目标推荐系统(MORS)[20]–[23],但在融合生成式 AI 技术方面,相关研究仍属稀缺。因此,将多目标优化整合进生成式推荐系统,是一个亟待深入研究的方向。
为填补这一空白,本文系统调研了使用生成技术实现多目标推荐的现有研究。我们特别强调,任何关于推荐系统附加目标(如多样性、偶然性或公平性)的讨论,都隐含地将准确性作为基础性前提。因此,我们将多目标推荐系统(MORS)定义为:优化准确性之外其他目标的推荐系统。 本综述识别出当前生成式推荐系统中除准确性外的主要目标包括:多样性、偶然性、公平性与安全性;此外还涉及新颖性、可控性、效率与鲁棒性等附加目标。我们聚焦于推荐系统中广泛应用的四类生成技术:GANs、扩散模型、VAEs 与大语言模型。针对每一类目标,我们深入回顾了主流的模型架构与评估指标,并总结相关发展挑战,旨在为未来的多目标生成式推荐研究提供基础性见解。
本文的主要贡献如下:
本文为首个将生成式人工智能(包括 GANs、VAEs、扩散模型和大语言模型)与多目标推荐系统(MORS)结合的全面综述,提出了一个面向目标的分类框架,系统回顾了四类关键目标(多样性、偶然性、公平性、安全性)下模型架构、优化策略和评估指标的发展与局限性。 * 我们系统总结了不同目标领域(如公平性与偶然性)下的专用评估指标与对应基准数据集,为实验设计提供标准化参考。 * 我们还讨论了生成式 MORS 研究中的核心挑战,并展望了未来的发展方向,包括改进评估指标、设计适用于 LLM 的高级策略、融合多种生成技术以提升推荐质量等。此外,我们强调跨学科合作(如伦理学、社会学)的重要性,以构建更加公平透明的推荐系统。这些见解为学术界与工业界的进一步探索与创新奠定了基础。
文章结构概览:
第 2 节综述推荐系统、生成式推荐系统和多目标推荐系统的相关文献,构建研究背景。 第 3 节介绍本文涵盖的四类主要生成技术。 第 4 节作为核心部分,系统梳理基于生成技术的多目标推荐系统,按超越准确性的目标进行分类,介绍相关定义、模型与评估指标。 第 5 节总结各类目标下常用的推荐数据集。 第 6 节探讨每类关键目标面临的主要挑战。 最后在第 7 节对全文进行总结。



在每一章的开头,你会在右侧页边栏找到一个小的图表,旨在让你了解该场景发生时世界的情况。若要了解这些数字的含义的更详细解释,以及我们方法的更多更详细的信息,请访问ai-2027.com。 我们预测,未来十年的超级人工智能的影响将是巨大的,将超过工业革命的影响。OpenAI、谷歌DeepMind和Anthropic的首席执行官都预测,通用人工智能将在未来5年内到来。萨姆·奥特曼表示,OpenAI的目标是“真正意义上的超级智能”和“光辉的未来。”人们很容易将其视为只是炒作。这将是严重的错误——它不只是炒作。我们并不想自己炒作人工智能,但我们认为超级智能在本世纪末到来是极有可能的。 我们不会在所有事情上都正确——这大都是猜测。但在整个项目过程中,我们进行了大量的背景研究、专家访谈和趋势外推,以做出我们能做出的最明智的猜测。此外,我们的团队在预测方面有着优异的记录,尤其是在人工智能方面。首席作者DanielKokotajlo在4年前撰写了一个类似的情景,名为“2026年将是什么样子”,其时效性出奇地好,而EliLifland是一位顶尖的竞赛预测家。 如果我们正处于超级智能的边缘,社会远未做好准备。很少有人甚至试图阐述通过超级智能发展的任何可行路径。我们撰写《AI2027》就是为了填补这一空白,提供急需的具体细节。我们希望看到世界上有更多这样的工作,尤其是来自不同意我们观点的人们。我们希望通过这样做,引发关于我们走向何方以及如何驶向积极未来的广泛讨论。 我们通过反复问自己“接下来会发生什么”来撰写这个场景。我们从当前时代开始,撰写第一个时期(直到2025年中期),然后是下一个时期,直到达到结局。我们并没有试图达到任何特定的结局。然后我们放弃了它,重新开始,很多次,直到我们得到了一个我们认为可信的完成场景。在我们完成第一个结局——赛车结局之后,我们写了一个新的替代分支,因为我们还想描绘一种更充满希望的方式,在大致相同的前提条件下结束。



印太地区已成为世界的中心,这归因于该地区贡献了全球GDP约60%的份额,且全球65%的人口位于此地。这标志着全球重心发生了重大转变——从主导世界至少五百年的大西洋(transAtlantic)架构转移至此。因此,印太地区的海上交通线(SLOCs)和贸易航线上,如今可见货轮、原油运输船和散货船的交通活动,每年有超过90,000艘船只穿越马六甲海峡。尽管对全球经济具有如此核心意义,印太地区仍面临诸多安全挑战,例如领土争端(大陆与海上皆有)、海盗活动、“暗船”行为、非法、未报告和无管制(IUU)捕捞、有组织犯罪、人口贩运、武器贩运、毒品问题以及生态问题。因此,亟需高效有效的海洋领域态势感知(Maritime Domain Awareness, MDA)(以补充该地区国家在陆上的法律法规工作),目的是维护海上良好秩序与安宁,在国家主权管辖范围内的领海、专属经济区和国家管辖范围以外的公海维护法治,并促进全球和平与安全。
本出版物深入探讨了印太地区的海洋领域态势感知(MDA),通过深入研究新兴技术的潜力、区域合作以及在提升海洋安全方面整合天基资产以加强监视与合作的可能性。在承认各国确保有效MDA的能力存在差异且需要通过合作加以提升的同时,评估了某些国家——尤其是美国、日本和澳大利亚——在此方面的角色。本书内的每篇论文都突显了印太地区海洋安全中一个独特但又相互关联的方面。
首章深入探讨了MDA在历史上的演变,以及对其术语本身理解的演变。强调了MDA从狭隘地关注安全关切转向更全面理解的过程,该理解包含了生态、环境和经济维度。该论文强调MDA关乎跟踪船舶、防止非法活动、保障和监控全球贸易航线并使其远离犯罪活动;同时,它也逐渐被理解为包括海洋资源的可持续性,以及解决有关国际法和全球治理的问题。该论文承认,海洋领域对于确保安全、安保和经济繁荣的重要意义及其对更广泛的区域和全球安全架构的影响,正日益得到认可。
第二章探讨了在印太地区加强MDA的区域合作。此方面强调区域行为体之间中心对中心的信息交流、建立信任和共享能力建设的必要性。它指出“四方安全对话”(Quad)的“印太海洋领域态势感知(IPMDA)”倡议在此领域采取积极和具体步骤的重要性,邀请其他志同道合的国家加入这些工作,并倡导其他集团采取类似的协调和行动倡议,例如环印度洋联盟(IORA)、环孟加拉湾多领域经济技术合作倡议(BIMSTEC)、东盟防长扩大会议(ADMM-Plus)和印太海洋倡议(IPOI)。它对设在印度古尔格拉姆的“信息融合中心-印度洋地区”(Information Fusion Centre-IOR)的工作给予了积极评价。作者强调,印太地区的海上安全不能仅靠一国的单边政策和行动来实现,而需要一种协作方法来应对这一全球公域中的关切。
第三章审视了彻底革新海洋监视的技术进步。指挥官阿布吉特·辛格(Abhijit Singh)追溯了海洋监控从基本雷达和自动识别系统(AIS)发展到更尖端技术的演变过程,这些技术包括基于卫星的地球观测(EO)、人工智能(AI)、无人机、射频(RF)检测和基于网络的平台。他阐述了在MDA国家政策框架以及该领域双边和区域合作与能力建设框架中,整合技术进步相关考量的必要性。
第四章探讨了印太地区的地缘政治重要性,特别关注水下领域态势感知(Underwater Domain Awareness, UDA)。他主张需要定制化或本土化的框架、水声技术(acoustic technologies)和海洋空间规划(Marine Spatial Planning, MSP),以适应该地区特殊的热带、赤道水下挑战范畴。
第五章强调第四次工业革命(4IR)解决方案——人工智能(AI)、机器学习、大数据、机器人技术和自动化——正在如何重塑海洋领域。该论文展示了这些技术对船舶运营、港口活动、物流升级和海洋监视的影响,并强调需要通过合作、能力建设和最佳实践交流来跟上这些技术的发展步伐。
第六章专注于空间技术(卫星)对印太地区海洋领域态势感知的影响。概述了合成孔径雷达(SAR)、自动识别系统(AIS)和气象卫星等卫星系统对于实时掌握海洋领域态势的重要性。本章阐述了天基资产在有效管理和扩大海洋领域覆盖范围方面的重大作用。
这里所涵盖的论文对于寻求解决该地区在海洋领域所面临复杂挑战的政策制定者、安全专家、从业人员和研究人员至关重要。通过强调新兴技术、区域内及区域间合作与可持续发展实践之间的相互联系,本出版物旨在成为宝贵的资源,指导未来旨在加强海洋治理和安全的努力。本文提出的建议将有助于指导制定政策,以建立印太地区乃至更广泛区域的和平、安全与可持续的海洋秩序。
提纲:
- 重新定义21世纪的海域感知
- 加强印太地区海域感知能力的区域合作与能力建设
- 海域感知的最新趋势
- 水下领域感知(UDA)框架——印度洋-太平洋战略空间热带水域海域感知(MDA)的新视角
- 通过新兴技术提高海洋领域感知
- 太空技术在提高印太地区海域感知中的作用


近年来,以大模型为代表的新一代人工智能技术迎来爆发式增长,成为推动产业升级、促进经济发展和引领社会进步的重要力量。智能体作为大模型应用的主要形态,高度贴合日益复杂的提质增效需求。加快推动智能体技术应用将成为推进人工智能与实体经济深度融合的重要抓手,是推动我国人工智能产业加速进入“模型研发-应用盈利-反哺科研”正向循环的可行路径。
2025年6月22日,中国信息通信研究院(简称“中国信通院”)人工智能研究所在华为开发者大会2025上联合发布了《智能体技术和应用研究报告(2025年)》,中国信通院人工智能研究所平台与工程化部主任曹峰对报告进行了深入解读。







摘要——近年来,视觉-语言预训练(Vision-Language Pretraining)作为一项融合视觉与文本模态优势的变革性技术,催生了强大的视觉-语言模型(VLMs)。依托于网络规模的预训练数据,这些模型展现出卓越的零样本推理能力。然而,在面对特定领域或专业任务时,其性能常常出现显著下降。为解决该问题,研究社区日益关注如何将 VLM 中蕴含的丰富知识迁移或泛化到多样的下游应用中。 本文旨在全面梳理 VLM 泛化的研究设定、方法体系、评测基准与实验结果。我们首先分析典型的 VLM 架构,并依据迁移模块的不同,将现有文献划分为基于 Prompt(提示)、基于参数、以及基于特征的方法三大类。随后,结合经典迁移学习(Transfer Learning, TL)设定,进一步总结与探讨各类方法的差异与特点,提出 VLM 时代下迁移学习的新解读。此外,本文还系统介绍了主流 VLM 泛化评测基准,并对各类方法在不同任务中的表现进行了详尽对比。
随着大规模通用预训练的不断演进,本文也探讨了视觉-语言模型与最新多模态大语言模型(Multimodal Large Language Models, MLLMs,如 DeepSeek-VL)之间的关联与差异。通过从“泛化”这一全新且实用的视角系统梳理视觉-语言研究的快速进展,本文有助于清晰描绘当前与未来多模态研究的整体格局。 关键词——视觉-语言模型,迁移学习,提示调优,鲁棒微调,领域泛化,测试时自适应,无监督领域适应,多模态大语言模型

1 引言
深度神经网络已在众多实际应用中取得显著成果。以视觉模型为例,从 AlexNet【1】到 ResNet【2】再到 Vision Transformer【3】,模型规模与表示能力都得到了极大提升。然而,高效训练这些大规模模型往往需要大量标注数据与巨大的计算资源。为了解决这一问题,“基础模型”(foundation model)的概念应运而生——即在大规模数据集上预训练通用模型,以便将其知识迁移到各种下游任务中【4】。例如,预训练于 ImageNet【5】上的 ResNet 系列已成为图像分类【2】、目标识别【6】等视觉任务的重要基石。 自然语言处理领域也经历了类似的发展,从 Transformer【7】、BERT【8】到 GPT-2【9】与 GPT-3【10】,均在各自的单模态任务中取得卓越表现,但它们本质上缺乏对多模态信息的感知与推理能力。 如图 1 所示,对比式语言-图像预训练(contrastive language-image pretraining)范式的出现【11】彻底重塑了视觉-语言学习格局。Radford 等人提出的 CLIP【11】模型利用 4 亿网页爬取的图文对进行对比学习:将语义匹配的图文拉近、不匹配的拉远,从而实现了跨任务的强大零样本泛化能力,覆盖图像分类【11】、目标检测【12】、视频检索【13】等任务。后续研究通过扩大与去噪预训练数据集【14】【15】【16】、探索多样的预训练策略【17】【18】、引入多语言数据【19】【20】【21】,进一步增强了 VLM 的能力。 尽管 VLM 在通用任务上表现出色,但其预训练知识在特定领域的下游任务上泛化能力有限。若无合适的迁移方式,预训练的 VLM 往往难以处理分布外(OOD)数据,如遥感图像【22】或精细类别图像【23】【24】。传统的“预训练-微调”范式仍适用,但在 VLM 中直接微调可能破坏其对齐的视觉-语言表示,导致性能下降【25】【26】【27】。 因此,如何以尽可能低的计算与标注成本将 VLM 中的知识优雅地泛化至下游任务,已成为研究热点。考虑到 VLM 的多模态特性,研究者们尝试将单模态领域成熟的迁移策略,如 Prompt Tuning【28】、Adapter 插件【29】、知识蒸馏【30】,扩展应用于 VLM【26】【31】【32】【33】。借助其庞大的通识知识,VLM 正逐步成为“任务无关型”求解器,在无监督领域适应(UDA)【34】【35】【36】、领域泛化(DG)【37】【38】【39】、测试时自适应(TTA)【40】【41】【42】等迁移学习场景中设立了新基线。 面对这种趋势,我们提出了关键问题:在 VLM 时代,知识迁移有何不同?
为此,本文对 VLM 的泛化能力展开系统文献综述。

研究动机与贡献
现有综述多聚焦于 VLM 的预训练阶段,如模型结构、预训练目标与数据集【43】【44】【45】。虽然部分工作提及了迁移学习【43】,但其覆盖面有限,尤其缺乏对不同迁移设定之间差异的探讨。本文是首个专注于 VLM 迁移与泛化能力 的系统综述。我们以主流的双分支架构(如 CLIP【11】)为基础,识别并归类迁移的关键模块,具体如下: 1. Prompt-based 方法:仅调节文本提示嵌入以控制模型行为【31】【32】【40】; 1. Parameter-based 方法:有策略地更新预训练参数【46】【47】【48】,或通过知识蒸馏引入新参数【33】【38】【39】; 1. Feature-based 方法:对提取到的特征进行后处理,如引入可学习模块【26】【35】或构建免训练缓存机制【27】【41】【49】。
我们结合迁移学习研究中的经典设定【4】【50】【51】,重新审视这些 VLM 方法,并分析其在不同迁移设定中的特性差异。随后,我们系统汇总了适用于各类迁移任务的主流基准数据集,并提供基于模型结构与方法设计的性能比较。
同时,本文还涵盖了 VLM 与多模态大语言模型(MLLM)之间的融合。近年来,大语言模型(LLM)取得突破性进展【52】【53】【54】【55】,将对齐语言的视觉编码器(如 CLIP)与 LLM 相连接,并以大规模多模态指令数据进行训练,构建出视觉-语言大模型(MLLM)。这些模型在视频理解、视觉问答、图像字幕、分割与识别等任务中展现出强大的泛化能力【18】【56】【57】【58】。 作为另一类通用视觉-语言模型,本文对 MLLM 的基本构建框架、模型类型、使用的预训练数据与目标,以及其在多任务中的表现进行全面总结,并呈现当前该领域的研究图谱(如图 3 所示)。
综述贡献总结如下:
系统回顾 VLM 泛化研究进展:涵盖无监督领域适应、领域泛化、小样本适应、测试时自适应等迁移学习任务;据我们所知,这是首个专注于 VLM 泛化的综述工作。 1. 提出三类关键迁移方法分类:Prompt-based、Parameter-based 与 Feature-based,并在各类迁移设定下深入分析其技术细节与适用场景。 1. 收集主流评测基准并对比方法性能:从泛化设定、模型结构与设计角度出发,提供公平、系统的性能评估。 1. 引入并分析 MLLM 的发展与代表模型:总结其结构、组成模块、泛化能力、训练数据与目标,为理解视觉-语言研究的前沿进展提供参考。 1. 提出当前挑战与未来方向:识别现阶段研究瓶颈,并展望可行的研究路径与潜力。
文章结构如下:
第 2 节介绍 VLM 相关基础知识及所涉及的迁移学习设定; * 第 3 节讨论 Prompt-based 方法,分为训练时提示(3.1)与测试时提示(3.2); * 第 4 节介绍 Parameter-based 方法,包括参数微调(4.1)与知识蒸馏(4.2); * 第 5 节探讨 Feature-based 方法,包括可学习适配器(5.1)与免训练缓存机制(5.2); * 第 6 节总结主流基准与方法性能评估; * 第 7 节介绍现代 LLM 如何增强与泛化 VLM,构成 MLLM; * 第 8 节总结当前进展并讨论未来的研究方向。





在俄罗斯乌克兰战场观察到的无人机广泛使用——无论是在部署机群的规模上,还是在交战双方作战中的普遍存在性上——似乎都满足了一场真正军事革命的条件。“无人化”(Dronization)不能被简化为纯粹的技术革新或特定类别的装备。它是一种变革性原则,可与上世纪(20世纪)的摩托化和机械化相提并论。它体现在无人机向消耗性、适应性工具的演变,“参与式战争”的出现,以及作战样式向“多火种、多领域”作战的转变。对于欧洲部队模式而言,乌克兰的例子应推动建立支持“无人化”所需的数字化、工业化和人力生态系统:构建统一的信息与决策支持系统,在武装部队内部培育“无人机文化”,并且短期内聚焦于“无人化”的“高端”领域——即远程打击能力。

“无人化”与21世纪“新军队”问题
呼应了二十世纪(20世纪)初的辩论,乌克兰战争证明了战场火力的复兴以及新释放力量的融合——当时由工业化推动,如今则由数字化驱动。这场变革的核心在于21世纪“新军队”的问题。要达成如此关键的转折点,不仅需要在战术领域——装备和程序——而且更需要在组织层面,甚至更重要的是在认知结构层面——也就是战争本身的定义、胜利理论和战略文化——实现发明与改革的协同效应。
无论是前线部队因作战紧迫性而触发,还是由自上而下的指令发起,“军事事务革命”(revolution in military affairs)迫使所有交战方都必须适应,尽管它们的应对方式会因其偏好、对利害关系的理解以及可用资源的不同而有所差异。由于战争既是进行战争社会的反映,也是其表现形式,一场军事革命必然预示或伴随着生产方式、社会经济秩序以及军民动员机制的转变。
“无人化”显然符合这些条件。它不仅仅是一种技术演进,其影响也非仅仅是渐进式的或局限于特定类型武器。它代表着一个更广泛的军事转型过程,类似于二十世纪的机械化和摩托化。它不仅影响作战构想,也影响生成、构建和运用力量所需的组织。然而,迄今为止,相关辩论往往仍是碎片化的。在“陆-空濒海”(Ground-Air Littoral)概念下,美军正在分析战术领域精确打击范围扩展和规模扩大所产生的影响。
他们的重点在于其制空权模式下,融合地面火力、空袭和电子战所产生的摩擦。在学术界,讨论的中心是信息时代中公民和军事参与的新形式。据说这种范式正在助长一场由联网个体直接资助和塑造防务努力的“众筹战争”。在乌克兰,活动人士和志愿者描述了一种“社会的技术军事化”(technological militarization of societies),使他们能够通过创新的力量抵消俄罗斯的数量优势。这些讨论突显了一个共同现象的不同维度,尽管它们尚未真正相互交融,尽管一些研究正开始弥合差距。要点并非宣称无人机是一种神奇武器,而是对其所引发的深刻变革进行综合阐述。由此观之,“无人化”似乎是数字化、网络化和自动化的催化剂——这三种长期存在的趋势,如今正渗透并重塑社会、经济,以及必然的,战争艺术。因此,属于中心集权动员机制和工业时代“宏技术”(macrotechnology)的典型产物——“发动机战争”——正被一场服务器和处理器战争所取代,这是全球化经济的特征,但却是个体化的,由信息的提取和应用所推动。




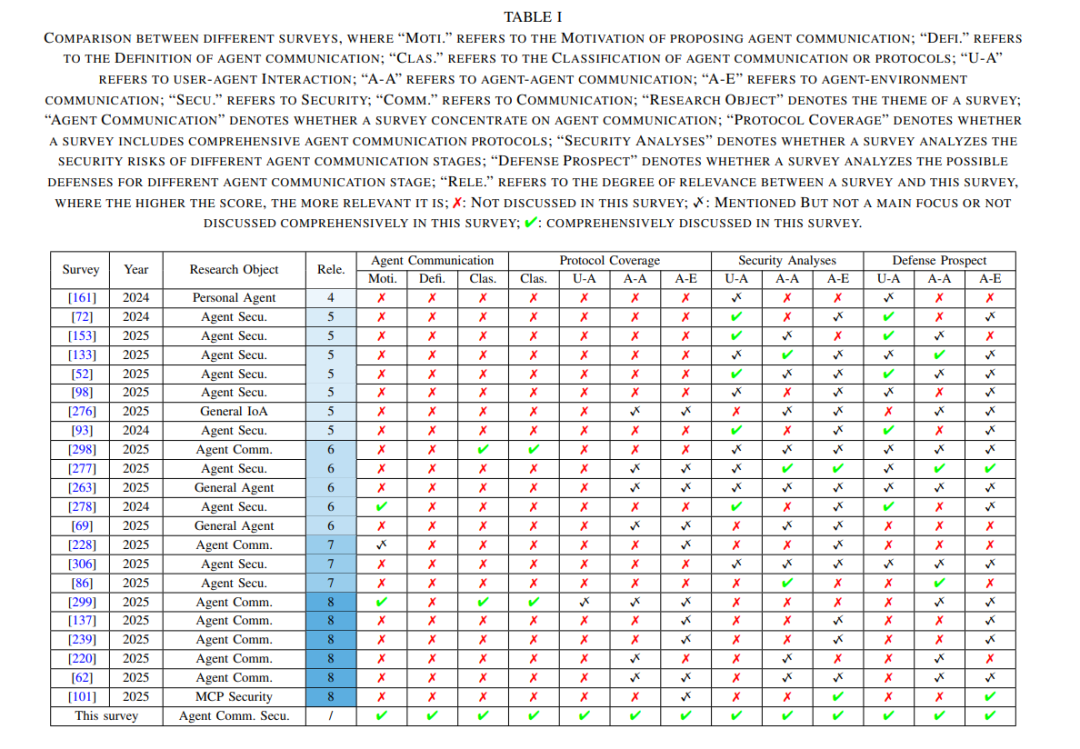
摘要——近年来,基于大语言模型(LLM)驱动的AI智能体展现出前所未有的智能性、灵活性与适应性,正在迅速改变人类的生产方式与生活方式。如今,智能体正经历新一轮的演化:它们不再像传统LLM那样孤立运行,而是开始与多种外部实体(如其他智能体与工具)进行通信,以协同完成更复杂的任务。在这一趋势下,智能体通信被视为未来AI生态系统的基础支柱,许多组织也在近几个月内密集推出相关通信协议(如Anthropic的MCP和Google的A2A)。然而,这一新兴领域也暴露出显著的安全隐患,可能对现实场景造成严重破坏。为帮助研究者迅速把握这一前沿方向,并促进未来智能体通信的发展,本文对智能体通信的安全问题进行了系统性综述。具体而言,我们首先明确界定了“智能体通信”的概念,并将其完整生命周期划分为三个阶段:用户-智能体交互、智能体-智能体通信以及智能体-环境通信。随后,我们针对每个通信阶段详细解析相关通信协议,并根据其通信特性剖析潜在的安全风险。在此基础上,我们总结并展望了各类安全威胁可能的防御对策。最后,本文还讨论了该领域仍待解决的关键问题与未来研究方向。 关键词:大语言模型、AI智能体、智能体通信、攻击与安全
一、引言
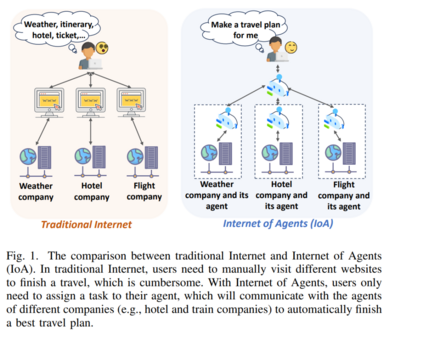
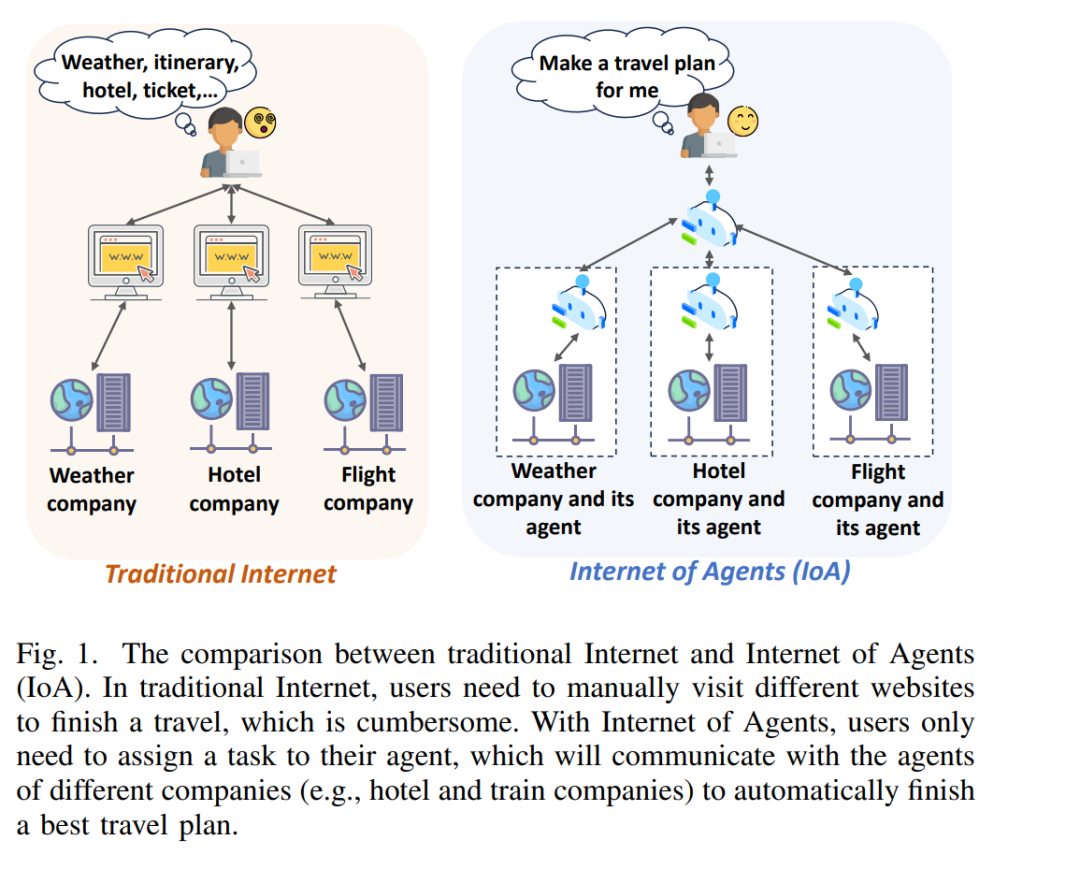
大语言模型(LLM)的出现引发了人工智能(AI)领域的革命性进展,在理解复杂任务方面展现出前所未有的能力【308】。更重要的是,LLM极大推动了人类所期望的理想AI形式——智能体(agent)的发展。与主要扮演聊天机器人的LLM不同,智能体具备更全面的能力(如感知、交互、推理与执行),使其能够独立完成现实世界中的任务。例如,当用户希望制定旅行计划时,LLM只能以文本形式提供最佳方案,而智能体则可以将方案转化为实际行动,如查询天气、购买机票和预订酒店。智能体大大加速了企业智能化转型的进程,其市场规模预计将以每年46%的速度增长【222】。可以预见,智能体将颠覆现代社会的生产与生活模式,深刻改变未来商业格局。因此,发展和推广智能体已成为各大国家和头部科技企业的战略重点。 当前,智能体正朝着面向特定领域的定制化实体方向演进,即针对特定场景和任务进行专门设计。在这一背景下,如图1所示,许多任务往往需要多个智能体协作完成,这些智能体可能分布于全球互联网上。在这种条件下,智能体通信成为未来AI生态系统的基础,能够支持智能体发现具备特定能力的其他智能体、访问外部知识、分派任务及完成其他交互。基于这一庞大的通信需求,越来越多的研究社区和企业开始抢占先机,投身于智能体通信的发展。 2024年11月,Anthropic提出了模型上下文协议(Model Context Protocol,MCP)【16】,这是一个通用协议,允许智能体调用外部环境,如数据集、工具和API。MCP在近几个月内迅速引起广泛关注,截至目前,已有数百家企业宣布接入MCP,包括OpenAI【203】、Google【87】、Microsoft【53】、Amazon【21】、阿里巴巴【10】和腾讯【251】,MCP软件包的每周下载量已超过300万次【17】。2025年4月,Google又提出了Agent to Agent协议(A2A)【218】,该协议支持智能体之间的无缝通信与协作。自发布以来,A2A获得了包括Microsoft【188】、Atlassian【149】和PayPal【229】等多家企业的广泛支持。由此可见,智能体通信的突破正带来迅速且深远的变革,并将成为AI生态系统不可或缺的一部分。 然而,智能体通信的迅猛发展也带来了复杂的安全风险,可能对AI生态系统造成严重破坏。例如,不同组织间的智能体协作显著扩大了攻击面,可能引发严重的安全威胁,包括但不限于隐私泄露、智能体伪造、智能体欺凌以及拒绝服务(DoS)攻击。由于智能体通信研究尚处于初期阶段,急需对整个通信生命周期中存在的安全问题进行系统性回顾。顺应这一趋势,本文旨在对现有的智能体通信技术进行全面梳理,分析其中的安全风险,并探讨相应的防御对策。我们相信本研究将对广泛读者群体有所帮助,无论是投身于智能体研发的科研人员,还是刚入门的AI初学者。 本文的主要贡献如下: * 首次系统性综述智能体通信:我们首次提出智能体通信的定义,并按通信对象将其划分为三个阶段:用户-智能体交互、智能体-智能体通信、智能体-环境通信。该分类覆盖了智能体通信的完整生命周期,同一阶段的通信协议通常具有相似的攻击面,有助于后续研究更方便地进行分析与评估。 * 深入分析智能体通信发展过程中的安全风险:我们讨论了已发现的攻击方式以及尚未揭示的潜在威胁。分析表明,用户-智能体交互主要面临来自恶意或错误用户输入的威胁,智能体之间的通信则易受到来自其他智能体或中间人的攻击,而智能体-环境通信则可能被受损的外部工具和资源所影响。 * 详细探讨有针对性的防御对策:我们指出了针对已识别安全风险的可能防护方向。例如,用户-智能体交互需要有效过滤多模态输入;智能体-智能体通信需要强大的机制来监控、归档、审计并量化协作中行为的责任;智能体-环境通信则应依赖于对外部环境中“中毒”内容的强力检测机制。 * 最后讨论开放问题与未来研究方向:我们不仅指出了急需发展的防护技术,还强调相关法律与监管体系亦需尽快完善。只有技术和法规双轮驱动,才能切实保障智能体通信在现实中的安全性。
文章结构
如图2所示,本文的组织结构如下:第二节对比相关综述,突出本文的创新点;第三节介绍研究所需的基础知识;第四节提出智能体通信的定义与分类;第五至第七节依次介绍用户-智能体交互、智能体-智能体通信、智能体-环境通信中的协议、安全风险及防御对策;第八节讨论该领域的开放问题与未来研究方向;第九节为本文的总结。