第二代NumPy?阿里开源超大规模矩阵计算框架Mars
选自 GitHub
机器之心编译
参与:刘晓坤
Mars 是由阿里云高级软件工程师秦续业等人开发的一个基于张量的大规模数据计算的统一框架,目前它已在 GitHub 上开源。该工具能用于多个工作站,而且即使在单块 CPU 的情况下,它的矩阵运算速度也比 NumPy(MKL)快。

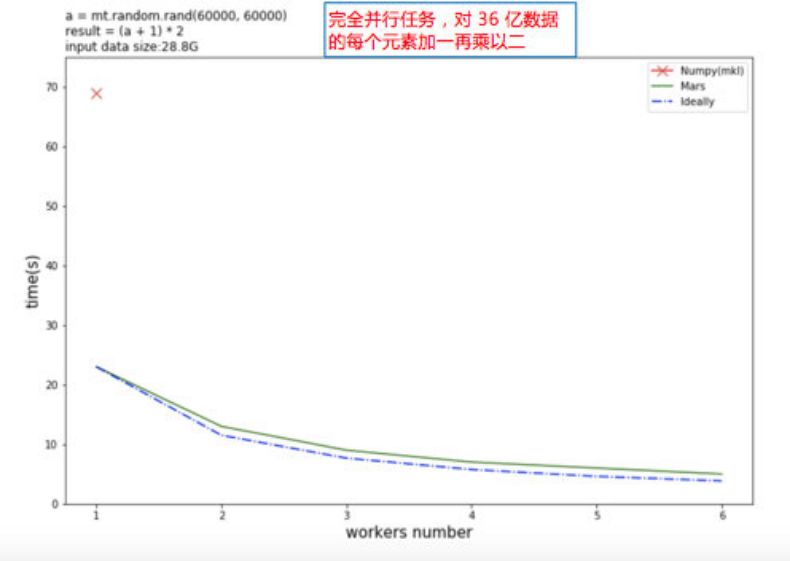
如下图所示,开发者给出了简单的性能对比。对 36 亿的数据的每个元素加一乘以二,测试随工作站数量增加的计算时间变化。红色的叉代表单机 NumPy。Mars 在单机上就能利用多核来加速,多机接近理想值。目前,在张量/矩阵这块,开发者尚未给出标准的 benchmark。
项目地址:https://github.com/mars-project/mars
文档地址:https://mars-project.readthedocs.io/en/latest/index.html
Mars 张量
Mars 张量提供了类似于 NumPy 的接口。
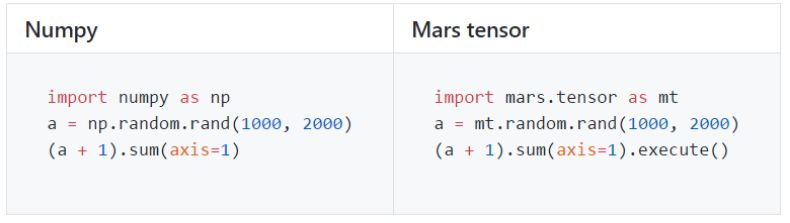
以下是 Mars 支持的 NumPy 接口的子集概览。
算法和数学: +, -, *, /, exp, log 等等。
沿轴缩减(sum, max, argmax 等等)。
大多数数组创建例程(empty, ones_like, diag 等等)。此外,Mars 并不支持在 GPU 上创建数组/张量,但仍然支持创建稀疏张量。
大多数数组操作例程(reshape, rollaxis, concatenate 等等)。
基本索引(通过 ints, slices, newaxes 和 Ellipsis 执行索引)。
沿列表或 numpy 数组的单个轴的 fancy index,例如 x[[1, 4, 8], :5]。
元素运算的通用函数。
线性代数函数,包括乘积(dot, matmul 等等)和分解(cholesky, svd 等等)。
然而,Mars 没有实现整个 Numpy 接口,时间限制还是主要障碍。下面列出了未实现的主要功能:
未知形状的张量不支持所有运算。
只实现了 np.linalg 的少量子集。
类似 sort 的难以并行执行的运算没有实现。
Mars 张量并没有实现类似 tolist 和 nditer 等的接口,因为其在大型张量上的迭代或循环是非常低效的。
架构
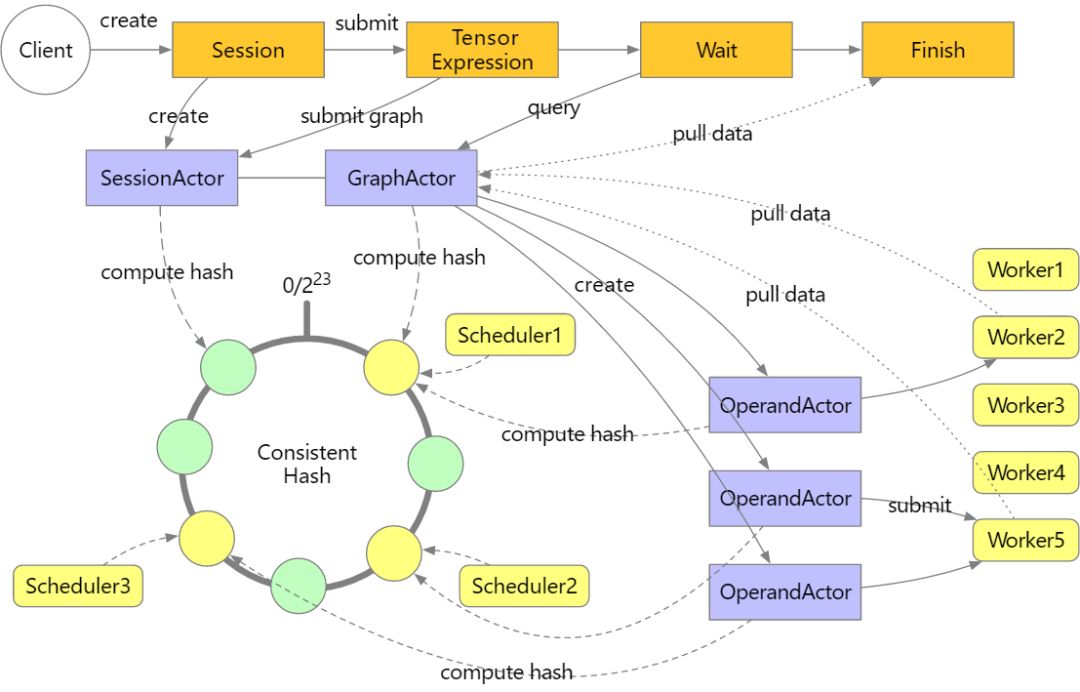
Mars 为张量的分布式执行提供了一个库。分布式应用程序使用 mars.actors 提供的 actor 模型构建,由三部分组成:调度器、工作站和 Web 服务。
用户使用张量构建的图形提交任务。Web 服务接收张量图并将它们发送到调度器,其中图形被编译成操作数(operand)图,在提交给工作站之前进行分析和分区。然后,调度器创建并分散操作数 actor,这些操作数 actor 在给定一致哈希的情况下控制其他调度器上的工作站任务执行,然后激活操作数并以拓扑顺序执行。当执行与终止张量相关的所有操作数时,图形将被标记为已完成,客户端可以从调度器代理的工作站中提取结果。整个过程如下图所示。
图准备
当张量图提交到 Mars 调度器时,给定在数据源中传递的块(chunks)参数时将生成由操作数和块构成的图。
图构成
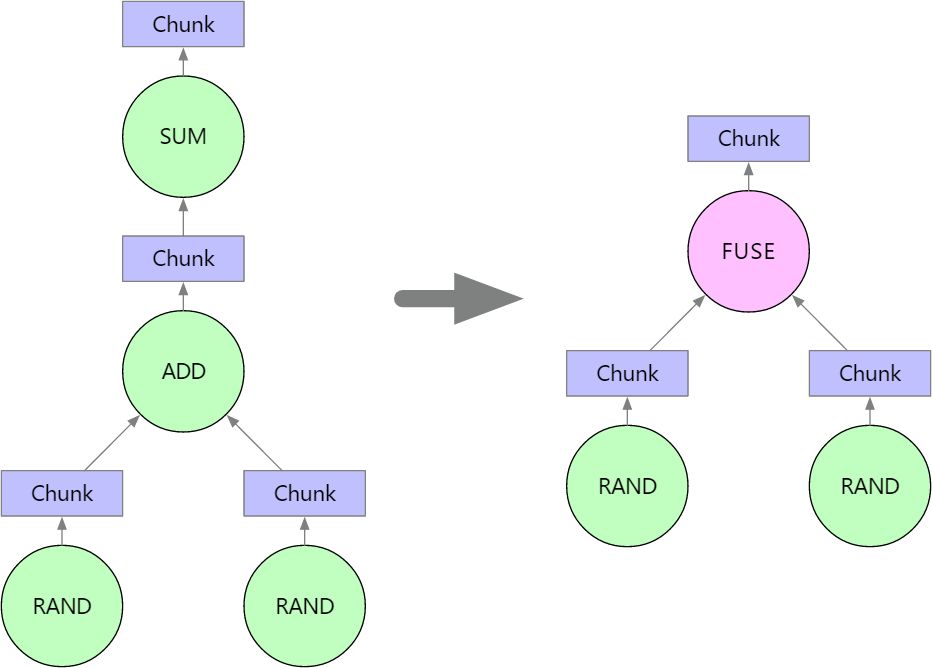
在将张量图平铺到块图之后,我们将组合相邻节点以减小图形尺寸以及利用加速库(例如 numexpr)。目前,Mars 仅合并形成没有分支的单个链的操作数。例如,执行代码时:
import mars.tensor as mt
a = mt.random.rand(100, chunks=100)
b = mt.random.rand(100, chunks=100)
c = (a + b).sum()
Mars 将把操作数 ADD 和 SUM 组合成一个 FUSE 节点。RAND 操作数被排除,因为它们不与 ADD 和 SUM 形成一条线。
调度策略
当正在执行操作数图时,正确选择执行顺序将减少存储在集群中的数据总量,从而降低块被溢出到磁盘中的可能性。正确选择工作站还可以减少执行中转移所需的数据量。
操作数选择
正确的执行顺序可以显着减少集群中存储的对象数量。我们在下图中显示树缩减的示例,其中椭圆表示操作数,矩形表示块。红色表示正在执行操作数,蓝色表示操作数已准备好执行。绿色表示存储块,而灰色表示释放块或操作数。假设我们有 2 个工作站,所有操作数的工作负载是相同的。两个图都显示了在 5 个时间单位后执行的一个操作数选择策略。左图显示了以层次结构顺序执行节点的场景,而右图显示了以深度优先顺序执行图表的场景。左图的策略将 6 个块存储在集群中,而右图仅存储 2 个。
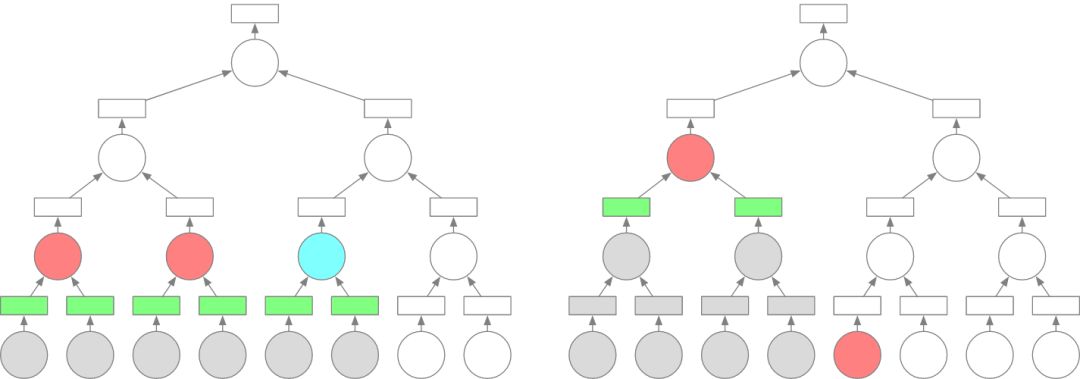
鉴于我们的目标是在执行期间减少存储在集群中的数据量,我们在准备执行时为操作数设置优先级:
1. 深度较大的操作数应较早执行;
2. 较深操作数所需的操作数应较早执行;
3. 首先执行输出尺寸较小的操作数。
操作数状态
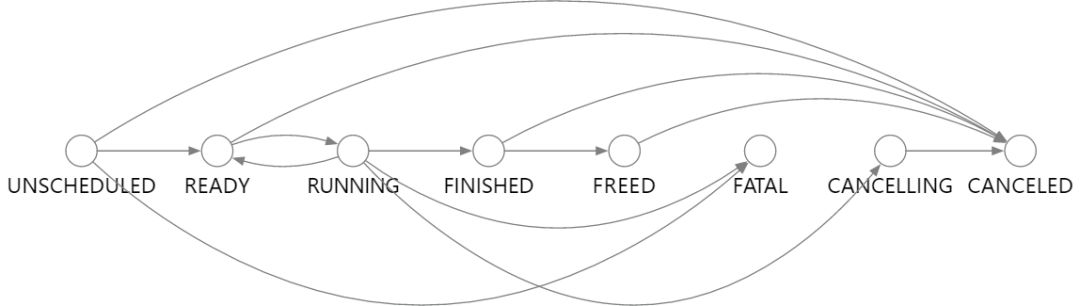
Mars 中的每个操作数都由 OperandActor 独立调度。执行被设计为状态转换过程。我们为每个状态分配一个状态处理函数来控制执行过程。最初初始化 actor 时,每个操作数都处于 UNSCHEDULED 状态。当满足某些条件时,操作数切换到另一个状态并执行相应的操作。如果从 KV 存储中恢复操作数,则将加载调度器崩溃时的状态并恢复状态。状态转换图如下所示:
工作站中的执行
当一个操作数在工作站中执行时,它将首先分配内存。然后加载来自其他工作站或已经溢出到磁盘的文件的数据。之后,所需的所有数据都在内存中,并且可以开始计算。计算完成后,工作站会将结果放入共享内存缓存中。这四种状态可以在下图中看到。

易于向内扩展和向外扩展
Mars 可以向内扩展到单机,也可以向外扩展到有数千台计算机的集群。本地和分布式版本都共享相同的代码,因此随着数据增加从单机迁移到集群是很简单的。
在单机上运行包括基于线程的调度,以及捆绑整个分布式组件的本地集群调度。Mars 也很容易通过启动集群中不同机器上的 mars 分布式运行时的不同组件来扩展到一个集群。
线程化
execute 方法将默认在单机的基于线程的调度器上运行。
import mars.tensor as mt
a = mt.ones((10, 10))
a.execute()
用户可以明确地创建一个 session。
from mars.session import new_session
session = new_session()
session.run(a + 1)
(a * 2).execute(session=session)
# session will be released when out of with statementwith new_session() as session2:
session2.run(a / 3)
本地集群
用户可以从单机上的分布式运行时启动本地集群,本地集群模式需要 mars 分布式版本。
from mars.deploy.local import new_cluster
# cluster will create a session and set it as default
cluster = new_cluster()
# run on the local cluster
(a + 1).execute()
# create a session explicitly by specifying the cluster's endpoint
session = new_session(cluster.endpoint)
session.run(a * 3)
分布式
在集群中每个节点都安装了分布式版本之后,一个节点可以被选为调度器,另一个节点作为 web 服务,剩下其它节点作为工作站。调度器可以通过以下命令启动:
mars-scheduler -a <scheduler_ip> -p <scheduler_port>
web 服务可以通过以下命令启动:
mars-web -a <web_ip> -s <scheduler_ip> --ui-port <ui_port_exposed_to_user>
工作站可以通过以下命令启动:
mars-worker -a <worker_ip> -p <worker_port> -s <scheduler_ip>
在所有 mars 进程启动后,用户可以运行:
sess = new_session('http://<web_ip>:<ui_port>')
a = mt.ones((2000, 2000), chunks=200)
b = mt.inner(a, a)
sess.run(b)
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




