Layer Normalization原理及其TensorFlow实现
Layer Normalization原理及其TensorFlow实现
本文参考文献
Ba J L, Kiros J R, Hinton G E. Layer normalization[J]. arXiv preprint arXiv:1607.06450, 2016.
被引次数:72
如今深度学习面临的一个最大挑战就是训练时间太长以及硬件的计算能力有待提升,我们可以有很多种方法加速我们的模型的训练过程,例如购买一个Nvidia Tesla K80,或者购买一个谷歌研发的Tensor Process Unit,或者使用多个机器与显卡构建分布式平台,这些都是硬件上的改进,而上一期我们讲的由谷歌科学家提出来的Batch Normalization算法(参见:Batch Normalization原理及其TensorFlow实现)则属于软件上的改进,该方法借鉴自以往参数的白归一化,并且将其应用到深度神经网络的每个mini-batch之中,从而尽力避免深度神经网络中出现的internal covariate shift,大大提升了训练速度,尤其是对于卷积神经网络而言。
我们大体上可以总结出Batch Normalization具有以下几个特点:
Batch Normalization操作是放在每一层的激活函数之前;
每一层都会对应一个Batch Normalization操作,并且每个Batch Normalization中都含有两个可以学习的参数beta和gamma;
Batch Normalization的算法流程是依赖于batch size的,因为在Batch Normalization变换时,是使用一个mini-batch的均值和方差来计算的;
Batch Normalization通过保证输入具有相同的分布,有效避免了internal covariate shift;
原始Batch Normalization论文中给出的实验结果是针对CNN用于图像分类问题的,并且Batch Normalization在CNN和DNN中表现都很好,然而,我们不禁要问,Batch Normalization用于RNN上效果如何呢?然而,由于RNN与普通的DNN相比最大的区别就是它的动态性,即在每个序列的长度可能不一样,所以这就会导致每个时刻在一个mini-batch内部会具有不同个数的样本,回顾Batch Normalization算法,其需要统计一个mini-batch内样本的均值和标准差,这就遇到问题了,可能有读者会提出使用padding来使得一个mini-batch内的所有样本长度保持一致,但是这样做使得统计的结果就不准确了,因此,在RNN中,不适合使用Batch Normalization,取而代之的是今天要讲的Layer Normalization,该论文出自多伦多大学Hinton组,相信大家应该都非常熟悉Hinton了,拥有非常传奇人生的深度学习大牛,目前就职于谷歌。
还有一个需要注意的是,在Batch Normalization中,虽然没有明确说明batch size需要满足的条件,但是由于我们使用一个mini-batch中的统计量来估计整个数据集的期望值的,因此如果batch size设置过小,则导致估计的期望值明显不准确。那么本文要讲的Layer Normalization就很好地克服了这个缺点,总的来说,Layer Normalization具有以下两个明显的特点:
Layer Normalization在训练阶段和测试阶段所执行的算法是一样的
Layer Normalization不依赖于batch size,即使是对于batch size为1的情况照样适用,因而Layer Normalization可以用于RNN中
下面来看一下Layer Normalization算法的具体细节,同Batch Normalization的作用一样,Layer Normalization也是为了避免神经网络中出现internal convariate shift,Layer Normalization也是希望可以固定输入的均值和方差,只不过它不是在mini-batch水平上来做,而是从层的角度来切入,如下公式所示,H是指一层的神经元个数,一层里面的所有神经元都共享均值和标准差,但是前提是对于一个训练序列,当训练序列不同时,这些统计量是需要重新计算的。

在RNN中,由于每个时刻实际上可以认为是一个单独的层,于是对于每个时刻,Layer Normalization得到的统计量实际上是不一样的,如下图公式所示,在每个时刻,Layer Normalization需要计算该层所有输入的均值和标准差,然后做归一化,并且乘上缩放因子以及添加偏置项。
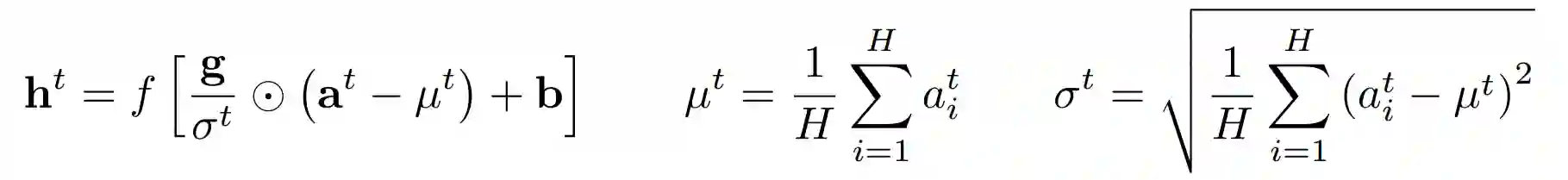
最后,我们来比较一下Batch Normalization,Weight Normalization以及Layer Normalization三者之间的差异:
Batch Normalization
对于batch size比较小的时候,效果非常不好,而batch size越大,那么效果则越好,因为其本质上是要通过mini-batch得到对整个数据集的无偏估计;
在训练阶段和推理阶段的计算过程是不一样的;
在CNN上表现较好,而不适用于RNN甚至LSTMWeight Normalization
计算简单,易于理解
相比于其他两种方法,其训练起来不太稳定,非常依赖于输入数据的分布Layer Normalization
不依赖于batch size的大小,即使对于batch size为1的在线学习,也可以完美适应;
训练阶段和推理阶段的计算过程完全一样
适用于RNN或LSTM,而在CNN上表现一般
Layer Normalization原理部分就介绍到这里,接下来动手实现一下基于LSTM的Layer Normalization,这里我们只用基于TensorFlow的LSTMCell来稍作修改一下即可,在每个门的激活函数之前加上Layer Normalization,代码仅供参考。
#coding=utf-8
import tensorflow as tf
def layer_norm(inp, eps=1e-5, scope=None):
# eps is for math stability
# inp must be a 2-D tensor
assert(len(inp.get_shape()) == 2)
mean, var = tf.nn.moments(inp, [1], keep_dims=True)
scope = '' if scope==None else scope
with tf.variable_scope(scope + 'layer_norm'):
gain = tf.get_variable('gain',
shape=[inp.get_shape()[1]],
initializer=tf.constant_initializer(1))
bias = tf.get_variable('bias',
shape=[inp.get_shape()[1]],
initializer=tf.constant_initializer(0))
ln = (inp - mean) / tf.sqrt(var + eps)
return ln * gain + bias
class LayerNormalizedLSTMCell(tf.contrib.rnn.RNNCell):
def __init__(self, num_units, forget_bias=1.0, activation=tf.nn.tanh):
# forget bias is pretty important for training
self._num_units = num_units
self._forget_bias = forget_bias
self._activation = activation
@property
def state_size(self):
return tf.nn.rnn_cell.LSTMStateTuple(self._num_units, self._num_units) @property
def output_size(self):
return self._num_units
def __call__(self, inputs, state, scope=None):
with tf.variable_scope(scope or type(self).__name__):
c, h = state
concat = tf.nn.rnn_cell._linear([inputs, h], 4 * self._num_units, False)
i, j, f, o = tf.split(1, 4, concat)
# add layer normalization for each gate before activation
i = layer_norm(i, scope = 'i/')
j = layer_norm(j, scope = 'j/')
f = layer_norm(f, scope = 'f/')
o = layer_norm(o, scope = 'o/')
new_c = (c * tf.nn.sigmoid(f + self._forget_bias) + tf.nn.sigmoid(i) *
self._activation(j))
# add layer_normalization in calculation of new hidden state
new_h = self._activation(layer_norm(new_c, scope = 'new_h/')) * tf.nn.sigmoid(o)
new_state = tf.nn.rnn_cell.LSTMStateTuple(new_c, new_h)
return new_h, new_state题图:Hubble Ultra Deep Field 2014
你可能会感兴趣的文章有:
Batch Normalization原理及其TensorFlow实现
Maxout Network原理及其TensorFlow实现
Network-in-Network原理及其TensorFlow实现
如何基于TensorFlow实现ResNet和HighwayNet
深度残差学习框架(Deep Residual Learning)
推荐阅读 | 如何让TensorFlow模型运行提速36.8%
推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)
深度学习每日摘要|坚持技术,追求原创


