最新《空间众包》综述论文,34页pdf

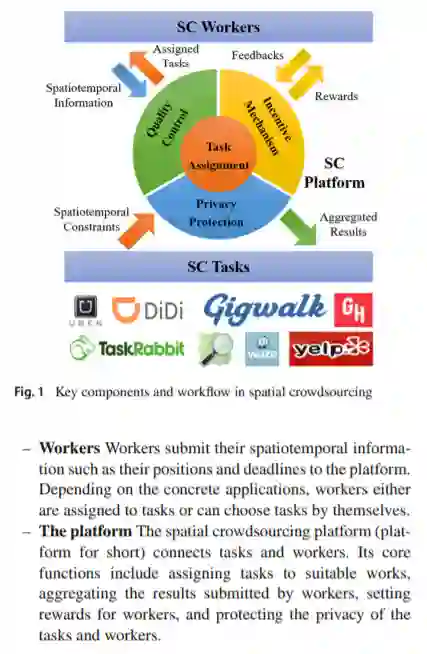
众包是一种计算范式,在这种范式中,人类积极参与计算任务,特别是那些本质上人类比计算机更容易完成的任务。空间众包是移动互联网和共享经济时代众包中日益流行的一种,任务是时空的,必须在特定的地点和时间完成。事实上,空间众包激发了最近一系列的产业成功,包括城市服务的共享经济(Uber和Gigwalk)和时空数据收集(OpenStreetMap和Waze)。本调查深入探讨了空间众包的独特性带来的挑战和技术。特别地,我们确定了空间众包的四个核心算法问题: (1)任务分配,(2)质量控制,(3)激励机制设计,(4)隐私保护。我们对上述四个问题的现有研究进行了全面和系统的回顾。我们还分析了具有代表性的空间众包应用程序,并解释了它们是如何通过这四个技术问题实现的。最后,我们讨论了未来空间众包研究和应用中需要解决的开放问题。
https://link.springer.com/article/10.1007/s00778-019-00568-7
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SC34” 可以获取《最新《空间众包》综述论文,34页pdf》专知下载链接索引



登录查看更多
相关内容
Arxiv
3+阅读 · 2020年7月20日



相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2020年7月20日