AI知识搜索利器:基于ElasticSearch构建专知实时高性能搜索系统
【导读】今天向大家介绍下ElasticSearch在专知搜索中的使用。ElasticSearch是一个基于Lucene的搜索服务器,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。我们利用ES对专知的AI内容库进行了索引,用户可以快速找到所需AI知识资源。下面由我们专知团队后台支柱李泳锡同学向大家分享下。
ElasticSearch简介
【导读】今天向大家介绍下ElasticSearch在专知搜索中的使用。ElasticSearch是一个基于Lucene的搜索服务器,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。我们利用ES对专知的AI内容库进行了索引,用户可以快速找到所需AI知识资源。下面由我们专知团队后台支柱李泳锡同学向大家分享下。
ElasticSearch简介
Elasticsearch(以下简称ES)是一个基于Apache Lucene的实时分布式搜索分析引擎,它能够让你以极低的时间开销去探索你的数据。
现如今,数据已经成为信息社会最为重要的生产资料,对于一些简单的查询,普通的数据库已经能够满足,但如果打算对数据进行更加细粒度的检索时,往往需要设计各种复杂、低效的查询脚本,甚至有的需求根本无法满足,而这,正是ES存在的意义所在。
虽然,ES中没有一个单独的组件是全新的,但其革命性的成果在于将各种已经存在的分散组件整合成了一个单一、一致、实时的应用。为初学者降低了搜索门槛的同时,也兼顾了实现复杂需求的扩展能力。这使得ES不仅成为很多大公司的宠儿,同时也得到了许多中小型创业公司的青睐。
下面将向大家介绍ES的基本概念、安装过程、实用组件、以及在专知中的应用效果。
ES基本概念
ES基本概念
首先,让我们了解一下ES中的基本概念与特征。
索引(index)
ElashticSearch将它的数据存储在一个或多个索引(index)中,用SQL领域的属于来类比,索引就像数据库,可以向索引写入文档或者从索引中读取文档,并通过在ElasticSearch内部使用Lucene将数据写入索引中检索数据,需要注意的数,ElasticSearch中的索引可能由一个或多个Lucene索引构成,具体细节由ElasticSearch的索引分片(shard)、复制(replica)机制及其配置决定。
文档(document)
文档(document)是ElasticSearch世界中的主要实体(对Lucene来说也是如此)。对所有使用ElasticSearch的案例来说,它们最终都可以归结为对文档的搜索。文档由字段构成,每个字段有它们的字段名以及一个或多个字段值(在这种情况下,该字段被称为是多值的,即文档中有多个同名字段)。文档之间可能有个字不同的字段集合,且文档并没有固定的模式或强制的结构。另外,这些规则也适用于Lucene文档。事实上,ElasticSearch的文档最后都存储为Lucene文档了。从客户端的角度来看,文档是一个JSON对象。
映射(mapping)
进入索引前,所有文档都要先进行分析,用户可以设置一些参数,来确定将文本切割为词条的方案,那些词条应该被过滤掉,或哪些附加处理是有必要被调用的。此外,ElasticSearch也提供了各种特性,如排序时所需的字段内容信息。这就是映射(mapping)扮演的角色,存储所有这种元信息。
类型(type)
ElasticSearch中每个文档都有阈值对应的类型(type)定义,这允许用户在一个索引中存储多种文档类型,并为不同文档类型提供不同的映射。
节点(node)
每个ES服务实例被称为节点(node)。
集群(cluster)
当数据量或查询压力超过单机负载时,需要多个节点来协同处理,所有这些节点组成的系统成为集群(cluster)。ES几乎无缝的集成了集群功能,即使某些节点因为宕机或执行管理任务不可用时,ES集群也可以提供可靠的服务。
分片(shard)
正如我们之前提到的那样,集群允许系统存储的数据总量超过单机容量。为了满足这个需求,ES将数据三步倒多个物理Lucene索引上。这些Lucene索引成为分片(shard),二散布着西分片的过程叫做分片处理(sharding)。ES会自动完成分片处理,并且让这些分片呈现出一个大索引的样子。
副本(replica)
分片处理允许用户向ES集群推送超过单机容量的数据。副本(replica)则解决了访问压力过大时单机无法处理所有请求的问题。副本通过为每个分片创建冗余的副本,在查询时将请求分散到各个副本上,加快处理进度。及时某个分片所在节点宕机,ES也可以使用其副本,所以一旦有需要可随时调整副本的数量。
ES使用
ES使用
ES生态系统中有着大量的扩展工具,可以满足开发者的各类开发需求。为了顺利使用ES,首先需要安装ES;其次,由于我们应用场景为中文检索,而ES的自带分词器主要面向英文,在中文场景下会将每个汉字分开,因此需要额外安装中文分词工具IK帮助我们根据关键词分词;最后,为了方便我们监控ES的各类指标,需安装head组件对ES进行可视化管理。
ES安装
安装 Elasticsearch
只有一个要求,就是要安装最新版本的JAVA。你可以到官方网站下载它:www.java.com.
确保java安装成功之后,可以在这里下载到最新版本的 Elasticsearch: elasticsearch.org/download.
或通过以下代码安装
curl -L -O http://download.elasticsearch.org/PATH/TO/LATEST/$VERSION.zip unzip elasticsearch-$VERSION.zip cd elasticsearch-$VERSION
运行Elasticsearch
通过如下代码运行
./bin/elasticsearch //普通运行模式./bin/elasticsearch -d//后台运行模式
测试运行
执行如下代码
curl 'http://localhost:9200/?pretty'
提示应如下所示:
{ "name" : "dJmeHvM", "cluster_name" : "elasticsearch", "cluster_uuid" : "0X-RlzVHSl6tSZ6pC4TRoQ", "version" : { "number" : "5.5.1", "build_hash" : "19c13d0", "build_date" : "2017-07-18T20:44:24.823Z", "build_snapshot" : false, "lucene_version" : "6.6.0" }, "tagline" : "You Know, for Search"}
IK安装
elasticsearch-analysis-ik 是一款中文的分词插件,支持自定义词库。
下载IK源码:
git clone https://github.com/medcl/elasticsearch-analysis-ikgit checkout tags/v5.0.1 根据ES版本切换IK版本号
安装IK至ES:
mvn package mkdir $ESHOME/plugins/ik //假设ES安装目录为$ESHOMEcp $IKHOME/target/releases/elasticsearch-analysis-ik-{version}.zip /usr/share/elasticsearch/plugins/ik // 假设IK安装目录为IKHOME cd $ESHOME/plugins/ik unzip elasticsearch-analysis-ik-{version}.zip
至此IK安装完毕。
head安装
安装nodejs
wget https://nodejs.org/dist/v8.4.0/node-v8.4.0-linux-x64.tar.xz tar xvf node-v8.4.0-linux-x64.tar.xz
至此node安装完毕,为了方便使用,在~/.bashrc文件末尾加入如下配置
export NODE_HOME=/xxx/node-v8.4.0-linux-x64//xxx为node文件夹所在路径 PATH=$PATH:$NODE_HOME/bin source ~/.bashrc// 令配置生效
此时输入node -v,如果输出了node版本号,则说明安装成功
安装grunt
grunt是一个很方便的构建工具,可以进行打包压缩、测试、执行等等的工作,5.0里的head插件就是通过grunt启动的。因此需要安装一下grunt:
npm install grunt-cli
安装head组件
git clone git://github.com/mobz/elasticsearch-head.git cd $HEADHOME //$HEADHOME为head的下载路径 npm install //安装依赖 grunt server // 启动服务
至此,head组件安装成功,可在本机通过浏览器访问localhost:9100域名,使用head功能。
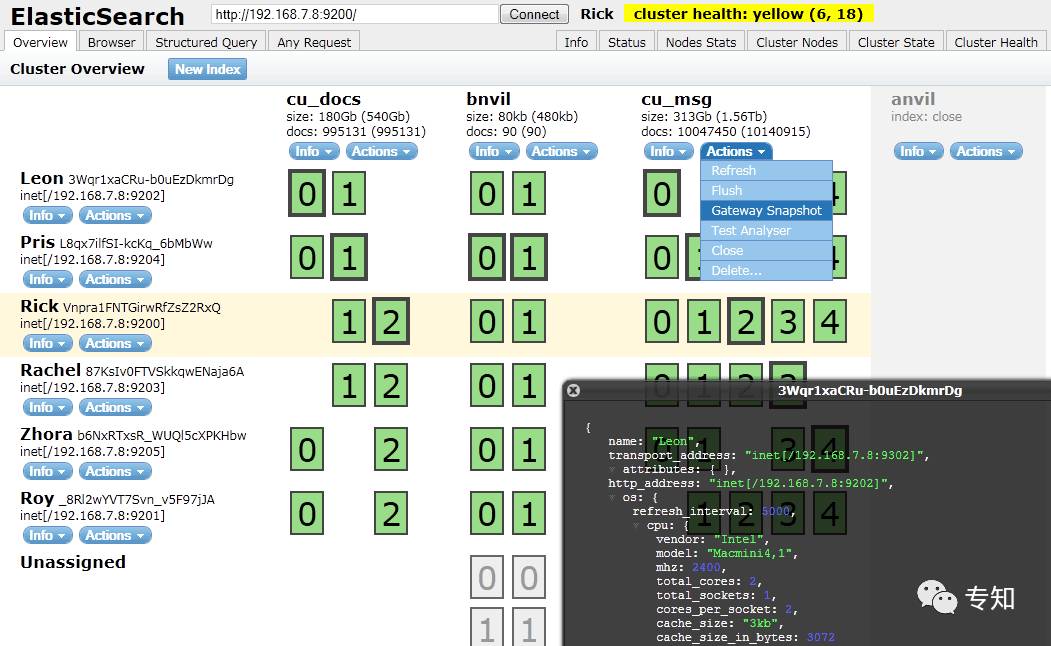
ES在专知中的应用
ES在专知中的应用
为了更好的方便用户检索平台历史内容,我们基于ES工具构建了专知的站内搜索引擎。并采用mongo-connector为mongo与ES实现了实时同步能力。
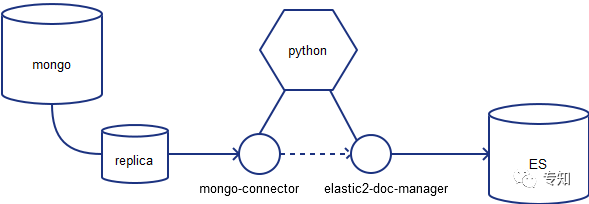
目前专知支持上万级别存量文档检索,并实现了增量文档实时级索引构建,以及毫秒级的文档检索响应能力。
欢迎大家使用专知!点击阅读原文即可访问,访问获取更多专知技术算法资源。
同时请,关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法等内容。扫一扫下方关注。

阅读更多:了解使用专知,为你提供一站式AI知识服务。
专知主题知识树可视化系列-一图了解大数据分析、编程语言、系统架构的知识体系大全
专知内容生产基石-数据爬取采集利器WebCollector 介绍