再发力!Facebook AI何恺明等最新研究MoCo(动量对比学习)第二版,超越Hinton的SimCLR,刷新SOTA准确率
【导读】无监督学习再发力!Facebook AI 研究团队的陈鑫磊、樊昊棋、Ross Girshick、何恺明等人提出了第二版动量对比(MoCo)的无监督训练方法。使用一个MLP投影头和更多的数据增强——建立了比Hinton前一久的SimCLR更强的基准,并且不需要大量的训练。

对比式无监督学习最近取得了令人鼓舞的进展,例如动量对比(MoCo)和SimCLR。在本文中,我们通过在MoCo框架中实现SimCLR的两个设计改进来验证它们的有效性。通过对MoCo的简单修改——即使用一个MLP投影头和更多的数据增强——我们建立了比SimCLR更强的基准,并且不需要大量的训练。我们希望这将使最先进的无监督学习研究更容易获得。代码将被公开。
最近关于从图像中进行无监督表示学习的研究[16,13,8,17,1,9,15,6,12,2]都集中在一个中心概念上,即对比学习[5]。结果是非常有希望的:例如,动量对比(MoCo)[6]表明,在多个检测和分割任务中,无监督前训练可以超越其图像监督后,而SimCLR[2]进一步减少了无监督和监督前预训练表示之间的线性分类器性能的差距。
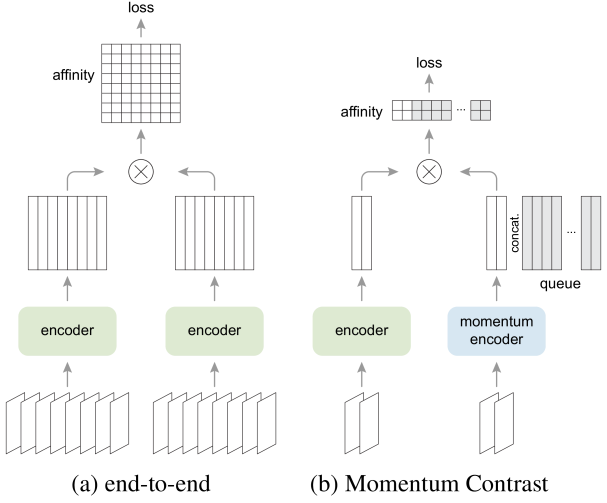
图1:对比学习的两种优化机制的批处理透视图。图像被编码到一个表示空间中,在这个表示空间中计算成对的相似度。
方法
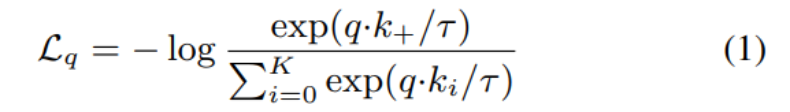
改进设计
SimCLR[2]在三个方面改进了实例识别的端到端变体:(i)能够提供更多负样本的更大的批处理(4k或8k);(ii)将输出的fc投影头[16]替换为MLP头;(三)数据扩充能力增强。
在MoCo框架中,大量的负样本是现成的;MLP头和数据扩充与对比学习的实例化方式是正交的。接下来,我们研究MoCo中的这些改进。
实验设置
在1.28M的ImageNet[3]训练集上进行无监督学习。(i) ImageNet线性分类:对特征进行冻结,训练监督线性分类器;我们报告了1种crop(224×224),验证准确率排名第一。(ii) 迁移到VOC目标检测[4]:更快的R-CNN检测器[14](c4 -主干)在VOC 07+12训练集上对所有条目(包括监督和MoCo v1基线)进行端到端微调,我们对VOC进行24k迭代微调,高于[6]中的18k。并在VOC 07测试集上使用COCO标准[10]进行评估。我们使用与MoCo[6]相同的超参数(除非特别指出)和代码库。所有结果使用标准大小的ResNet-50[7]。
MLP头 在[2]之后,我们将MoCo中的fc头替换为2层MLP头(隐藏层2048-d,使用ReLU)。注意,这只影响到非监督训练阶段;线性分类或迁移阶段不使用这个MLP头。[2]之后,我们寻找一个最佳的τ关于ImageNet线性分类准确率:

使用默认τ= 0.07[16,6],训练的MLP头提高从60.6%至62.9%;切换到MLP的最优值(0.2),准确度度提高到66.2%。表1(a)显示了它的检测结果:与ImageNet上的大飞跃相比,检测增益更小。
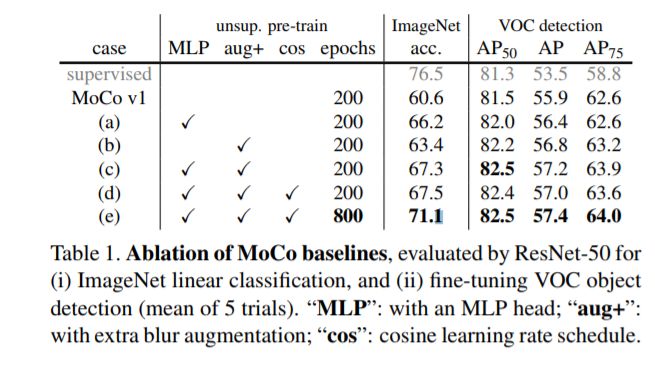
数据增强 我们通过在[2]中加入模糊增强来扩展[6]中的原始增强(我们发现在[2]中更强的颜色失真在我们更高的基线中有递减的增益)。单独的额外增加(即(no MLP)将ImageNet上的MoCo基线提高了2.8%,达到63.4%,见表1(b)。有趣的是,它的检测准确率比单独使用MLP要高,表1(b)与(a),尽管线性分类准确度要低得多(63.4%比66.2%)。这说明线性分类精度与检测中的迁移性能不是单调相关的。对于MLP,额外的增强将ImageNet的精度提高到67.3%,见表1(c)。
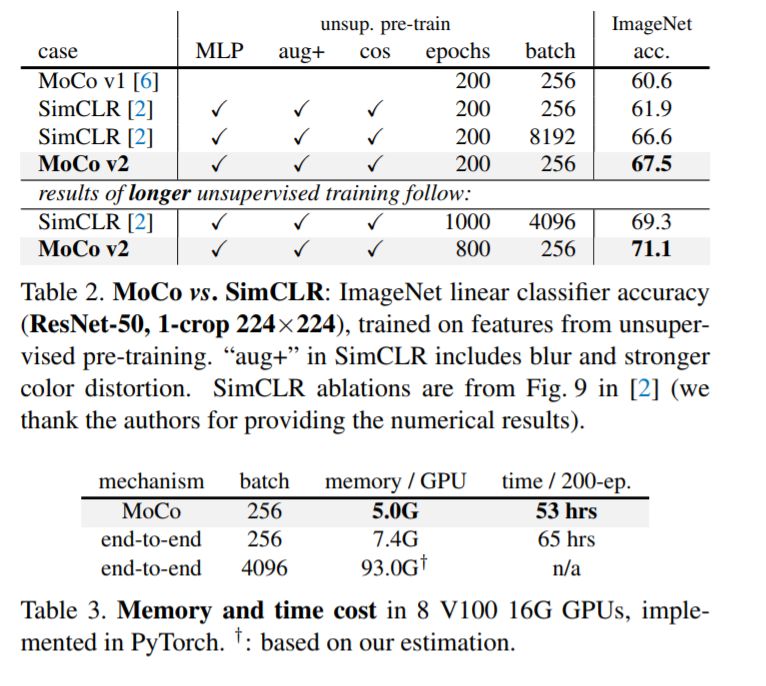
与SimCLR进行比较 表2将SimCLR[2]与我们的结果MoCo v2进行了比较。为了公平比较,我们还研究了SimCLR采用的一个余弦(半周期)学习速率调度[11]。表1(d, e)。MoCo v2使用200个epoch和256个批量大小的预训练,在ImageNet上达到67.5%的准确率,比SimCLR在相同epoch和批量大小下的准确率高5.6%,比SimCLR的大批量结果高66.6%。通过800-epoch的预训练,MoCo v2达到了71.1%,超过了SimCLR的69.3%,达到了1000个epoch。
计算成本
在表3中,我们报告了实现的内存和时间成本。端到端案例反映了GPU中的SimCLR成本(而不是[2]中的TPUs)。即使在高端的8-GPU机器上,4k的批处理大小也是难以处理的。而且,在相同的批处理大小为256的情况下,端到端变体在内存和时间上仍然更昂贵,因为它向后传播到q和k编码器,而MoCo只向后传播到q编码器。
表2和表3表明,为了获得良好的准确性,不需要大的训练批处理。我们研究的改进只需要对MoCo v1进行几行代码更改,我们将公开代码以方便将来的研究。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MOCO” 就可以获取《Facebook AI何恺明等最新研究MoCo(动量对比学习)第二版,超越Hinton的SimCLR,刷新ImageNet准确率》论文专知下载链接






