为什么2018年AI领域缺乏突破性进展?

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
回答来自 Xavier Amatriain,前机器学习研究员,目前担任多支工程技术团队负责人。
如果要对 2018 年全年的机器学习发展状况做出简要总结,那么我可能会给出以下结论:
AI 炒作与恐惧情绪开始逐渐降温。
人们更多关注公平性、可解释性或者因果关系等具体问题。
深度学习仍然地位稳固,并在实践当中超越图像分类这一传统应用方向(特别是在自然语言处理方面表现良好)。
AI 框架领域的对抗正在升温,要想在这一领域占据一席之地,发布自己的框架已经势在必行。
下面,让我们更详尽地对上述观点做出阐述。
如果说 2017 年代表着人工智能恐惧与炒作情绪全面来临的元年,那么 2018 年似乎是我们开始冷静下来的一年。虽然某些统计数字表明 AI 恐惧情绪仍然存在,但随着大量实际问题的出现,人们开始更多将关注重点放在具有现实意义的方向之上。与此同时,媒体及关注者们似乎开始认为,虽然自动驾驶汽车及其它类似技术正在推进,但在短时间内仍然不可能全面落地。不过目前也有人在为一些糟糕的观点发声,认为我们应该规范 AI 本身,而非着力规范 AI 产生的结果。
我们很高兴地看到,今年整个行业开始将关注重点放在更为具体且拥有解决可能的问题身上。举例来说,从业者们围绕公平性原则进行了大量讨论——除了与这一主题相关的各类会议(例如 FATML 以及 ACM FAT)之外,谷歌公司还开始发布在线课程(https://www.blog.google/technology/ai/new-course-teach-people-about-fairness-machine-learning/amp/)。
除此之外,今年得到广泛重视的议题还包括人工智能的 可解释性、解释能力以及因果关系。
首先从因果关系谈起,它之所以重新成为人们的关注焦点,主要是因为 Judea Pearl 出版的《The Book of Why》。作者除了下定决心撰写这样一本“具有普遍接受性”的论著之外,还借助 Twitter 等媒体平台着力提升关于因果关系这一重要问题的讨论热情。事实上,不少大众媒体都将这本书视为对现有人工智能方法的一种“挑战”。
同样值得一提的是,ACM Recsys 大会上获得最佳论文奖的论文,其核心内容正是讨论如何实现因果关系的嵌入(详见〈关于因果关系嵌入的建议〉,「Causal Embeddings for Recommendations」)。话虽如此,也有不少其他作者认为因果关系在某种程度上代表着理论研究出现了“分心”——在他们看来,整个行业应该多关注更具体的问题,例如可解释性与解释能力。说到解释能力,该领域的最大亮点之一当数 Anchor 论文与代码的正式发表——该项目出自著名的 LIME 模型的开发团队。
尽管深度学习能否作为最为普遍的人工智能范式这一问题仍然存在不少争议(我个人也一直在参与此类讨论),Yann LeCun 与 Gary Marcus 之间的思想碰撞也早已迭代了无数次,但可以肯定的有两点:第一,深度学习绝不会就此止步;第二,深度学习还远没有达到其能够达到的高度。更具体地讲,在 2018 年年内,深度学习方法确实在计算机视觉之外的领域——从语言处理到医疗保健——取得了前所未有的成功。
事实上,深度学习最重大的影响很可能出现在自然语言处理(简称 NLP)领域,这也是我们在今年当中亲眼见证的最为有趣的进展。如果一定要在今年之内选出最令人印象深刻的 AI 应用,那么我个人的榜单上一定全都是自然语言处理类选项(而且全部来自谷歌)。位列榜首的是谷歌公司极具实用性的智能组合(https://ai.googleblog.com/2018/05/smart-compose-using-neural-networks-to.html?m=1),其次则是师出同门的 Duplex 对话系统。
使用语言模型这一概念源自 Fast.ai 的 UMLFit 项目(这里推荐大家参阅〈了解 UMLFit〉,“Understanding UMLFit”),且极大加快了突破性进展的实现速度。除此之外,Allen 的 ELMO、Open AI 的 transformers 乃至近期谷歌推出的 BERT(目前已经击败众多 SOTA)都是这种进步的直接体现。这些模型堪称“自然语言处理领域的 Imagenet 时刻”,它们能够提供随时可用的预训练与通用模型,亦可针对特定任务进行微调。当然,除了语言模型之外,今年还出现了其它一些有趣的进步——例如 Facebook 的多语言嵌入(https://code.fb.com/ml-applications/under-the-hood-multilingual-embeddings/)等等。值得强调的是,我们还看到上述乃至更多其它方法被快速整合至通用性更高的自然语言处理框架当中——包括 AllenNLP 以及 Zalando 的 FLAIR。
说到框架,今年的“AI 框架之战”可谓持续升温、愈演愈烈。令人惊讶的是,正如 PyTorch 1.0 发布公告中所言,PyTorch 似乎正在缩小其与 TensorFlow 之间的差距。尽管 Pytorch 在生产环境中的表现仍然不够理想,但其在这方面的进步速度绝对不容质疑;而 TensorFlow 则在可用性、说明文档质量以及学习资源方面迎来改善。
有趣的是,PyTorch 之所以拥有如此强劲的发展势头,很可能得益于 Fast.ai 库将其作为指定框架。话虽如此,谷歌公司显然意识到了这一切,并正在朝着正确的方向前进——例如将 Keras 列为首选框架,以及将 Paige Bailey 等顶尖开发领导者引入项目等等。总而言之,我们都能够从这些卓越的资源当中获益,因此请大家静静期待美好明天的到来!
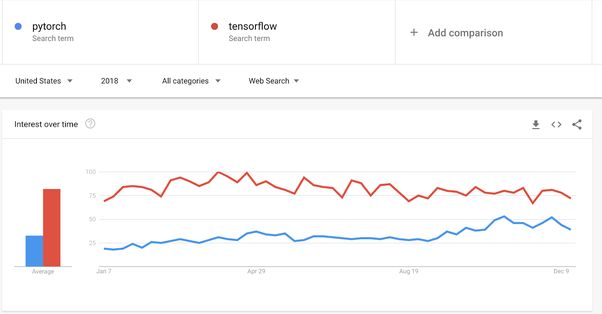
另一个有趣的点在于,强化学习在框架领域当中也迎来了相当强劲的发展势头。虽然我认为目前的强化学习进展无法与几年前的态势相比肩(最近真正具有份量的成果只有 DeepMind 的 Impalawork),但令人意外的是,这一年当中几乎所有主要 AI 参与方都发布了自己的 RL 框架。谷歌公司发布了用于学术研究的 Dopamine 框架,Deep Mind(同样属于谷歌内部机构)则推出竞争性 TRFL 框架。Facebook 方面也不甘落后,发布了 Horizon 框架;此外微软公司拥有自己的 TextWorld 框架——专门面向基本文本的代理训练。总之,希望这些开源项目能够帮助我们在 2019 年迎来更多值得期待的强化学习研究进展。
谈到框架这个话题,自然不能忽略谷歌公司最近以 TensorFlow 为基础发布的 TFRank。毫无疑问,排名机制是深度学习技术最为重要的应用之一,而且其目前得到的重视程度仍然相对偏低。
在很多人看来,深度学习技术已经成功消除了智能化过程中对数据资源的需求,但实际情况远非如此。
这一领域当中近期涌现出不少解决方案,用于对数据质量进行改进。举例来说,虽然数据增量机制已经不是什么新鲜事物,而且成为众多深度学习应用的核心所在,但今年谷歌仍然进一步推出了其 auto-augment——这是一套深层强化学习方案,用于自动增强训练数据。
业内还出现一种更为极端的思路,即利用合成数据训练深度学习模型。这种作法已经经历了一段时间的验证,而且不少人将其视为人工智能未来发展的关键。英伟达公司就在其《利用合成数据训练深度学习(Training Deep Learning with Synthetic Data)》这篇论文当中提出了不少有趣的新颖想法。而在我们发表的《向专家学习(Learning from the Experts)》一文中,作者还展示了如何将由专家系统生成的合成数据与实际数据相结合,从而共同用于深度学习系统训练。
最后,同样有趣的是通过使用“弱监督”机制显著减少数据准备所带来的大量手工标记需求。Snorkel 是个非常重要的项目,旨在通过提供通用框架促进这一方法的实现。
尽管人工智能领域各类基础性突破有所增加,但在我看来其绝对数量仍然不够乐观。
在这方面,我并不太赞同 Hinton 提出的,目前的创新缺失问题源自“行业当中年轻从业者太多而资深从业者太少(https://www.wired.com/story/googles-ai-guru-computers-think-more-like-brains/)”的结论——当然,我承认目前科学界确实存在着“突破性成果往往来自高龄研究者(https://phys.org/news/2011-11-breakthrough-scientific-discoveries-longer-dominated.html)”的现象。
在我看来,目前缺乏突破性成果的主要原因,在于现有方法及其变体仍有着大量有趣的实践性应用空间,因此从业者们很难或者不愿冒险探索那些尚不具备实用意义的方向。考虑到当下大多数研究工作是由巨头级企业赞助这一现状,上述结论也更加符合逻辑。
无论如何,今年当中还是出现了一篇非常重要的、对一系列现有假设提出挑战的论文,即《对序列建模类通用卷积与递归网络的实证评估(An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling)》。虽然其中采用的仍然是以经验性为基础的已知方法,但这篇论文仍然打开了新型实证方法的大门,并证明人们传统意义上认为最优的方法实际上并非最优。另一篇极具探索性的论文则是最近获得 NeurIPS 最佳论文奖的《神经常微分方程(Neural Ordinary Differential Equations)》,其中对深度学习中的一些基础性概念发起冲击,包括层概念本身。
有趣的是,最后一篇论文的撰写动机,在于作者在医疗保健数据(更具体地讲,电子健康记录)研究中的发现。很明显,如果不涉及人工智能与医疗保健两大行业的交集内容(这也是我在 Curai 的研究重点所在),我无法对这篇论文做出总结。遗憾的是,这部分交集可说的太多,恐怕需要另开一篇文章才能解释清楚。
总而言之,在这里我只向大家推荐 MLHC 大会(https://www.mlforhc.org/)与 ML4H NeurIPS 研讨会(https://ml4health.github.io/2018/)上发布的几篇相关论文。我们 Curai 团队提交的论文在 MLHC 与 ML4H 上都得到了通过,感兴趣的朋友可以参阅这些重要的文献资料,从而快速了解目前整个行业的发展态势。
Julia Computing 公司(2015 至今)联合创始人兼 CEO Viral Shah 在回答中针对新兴编程语言 Julia 在原生支持机器学习应用方面的进展做了总结:
2017 年,我们在 Julia 社区进行了一轮机器学习 / 人工智能调查,并撰写了一篇关于研究结果的博文,即《关于机器学习与编程语言(On Machine Learning and Programming Languages)》。我们在这篇博文当中得出以下结论:
机器学习模型已经成为一种高度通用的信息处理系统,能够构建起更高级别且更为复杂的抽象;递推、递归、高阶模型,甚至是堆栈机器与语言解释器,都可通过基础组件的组合实现。机器学习是一种新的编程范式,且其中存在一些奇怪的特性——包括数值性、可微分性以及并行性。
2018 年,我们专注于在 Julia 当中建立新功能,用以原生支持机器学习应用。我们在《为机器学习构建语言与编译器(Building a Language and Compiler for Machine Learning)》这篇博文当中汇报了我们在这方面的进展。
我们在 NeurIPS 2018 大会上的 MLSYS 研讨会中通过 4 张海报展示了相关进展。下面,我们将对 2018 年的整体进展做出总结:
通过 Julia 语言内的整体 AD 工作关注微分编程。这项工作的大部分内容通过 Julia 编译器 1.0 版本中的改进(https://julialang.org/blog/2018/08/one-point-zero)以及 Cassette.jl 实现,旨在向 Julia 编译器当中注入新的、特定于上下文的行为。如此一来,以 Zygote.jl 为代表的各类工具包就能够利用这些功能以实现 Julia 中的源到源 AD(https://arxiv.org/abs/1810.07951)。
原生针对性硬件加速器。Julia 现在可以通过 CUDAnative.jl 工具包生成 PTX,从而原生运行在 GPU 之上(https://docs.google.com/presentation/d/1l-BuAtyKgoVYakJSijaSqaTL3friESDyTOnU2OLqGoA/edit#slide=id.p)。此外,Broadcast GPU 内核中的动态自动微分(https://arxiv.org/abs/1810.08297)也显示出超越现有工具的性能优势。在 TPU 方面,Julia 可以通过 XLA.jl 工具包使用 XLA 编译器。
这些功能都已经被打包在 Julia 框架当中供研究人员以及用户使用。《利用 Flux 实现 Fashionable 建模(Fashionable modeling with Flux)》论文对 Flux.jl 框架做出了详尽阐述。最后,Knet.jl 框架能够利用多种手写 CUDA 内核,同时也是目前速度最快的深度学习框架之一。
原文链接:
https://www.quora.com/What-were-the-most-significant-machine-learning-AI-advances-in-2018
今日荐文
点击下方图片即可阅读

2019年,被高估的AI与数据科学该如何发展?
本周是 2018 年的最后一周了,这一年你有哪些收获,又有哪些遗憾?
可能你因为忙,某某事情没来得及做。对,当忙碌成为了主旋律,那高效一词就自然浮出了水面。
作为程序员,该如何高效工作,掌握主动权,忙到点子上?《10x 程序员工作法》专栏里,资深架构师郑晔带你真正掌握高效工作法则。现在订阅,更有以下福利:
福利一:限时优惠¥68,原价¥99,2019 年 1 月 5 日恢复原价
福利二:每邀请一位好友购买,你可获得 24 元现金返现,多邀多得,上不封顶,随时提现。(提现流程:极客时间 App - 我的 - 分享有赏)

扫上图二维码,或点击「阅读原文」,立即试读或订阅。

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得点一下右下角的“好看”哟!





