【论文推荐】最新七篇视觉问答(VQA)相关论文—融合算子、问题类型引导注意力、交互环境、可解释性、稠密对称联合注意力
【导读】既昨天推出七篇视觉问答(Visual Question Answering)文章,专知内容组今天又推出最近七篇视觉问答相关文章,为大家进行介绍,欢迎查看!
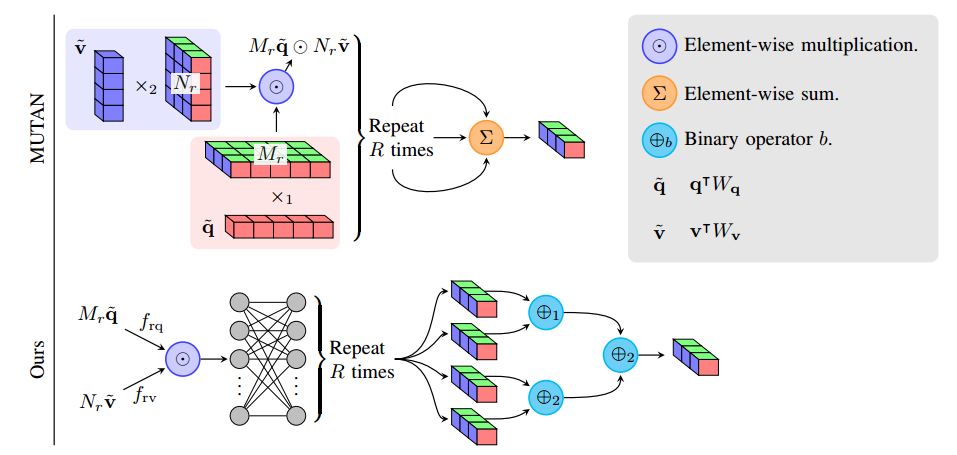
1. Generalized Hadamard-Product Fusion Operators for Visual Question Answering(基于广义Hadamard-Product融合算子的视觉问答)
作者:Brendan Duke,Graham W. Taylor
机构:, University of Guelph
摘要:We propose a generalized class of multimodal fusion operators for the task of visual question answering (VQA). We identify generalizations of existing multimodal fusion operators based on the Hadamard product, and show that specific non-trivial instantiations of this generalized fusion operator exhibit superior performance in terms of OpenEnded accuracy on the VQA task. In particular, we introduce Nonlinearity Ensembling, Feature Gating, and post-fusion neural network layers as fusion operator components, culminating in an absolute percentage point improvement of $1.1\%$ on the VQA 2.0 test-dev set over baseline fusion operators, which use the same features as input. We use our findings as evidence that our generalized class of fusion operators could lead to the discovery of even superior task-specific operators when used as a search space in an architecture search over fusion operators.
期刊:arXiv, 2018年4月6日
网址:
http://www.zhuanzhi.ai/document/444d5e32145432bb8bc7e703d21c237e
2. Fooling Vision and Language Models Despite Localization and Attention Mechanism
作者:Xiaojun Xu,Xinyun Chen,Chang Liu,Anna Rohrbach,Trevor Darrell,Dawn Song
机构:Shanghai Jiao Tong University
摘要:Adversarial attacks are known to succeed on classifiers, but it has been an open question whether more complex vision systems are vulnerable. In this paper, we study adversarial examples for vision and language models, which incorporate natural language understanding and complex structures such as attention, localization, and modular architectures. In particular, we investigate attacks on a dense captioning model and on two visual question answering (VQA) models. Our evaluation shows that we can generate adversarial examples with a high success rate (i.e., > 90%) for these models. Our work sheds new light on understanding adversarial attacks on vision systems which have a language component and shows that attention, bounding box localization, and compositional internal structures are vulnerable to adversarial attacks. These observations will inform future work towards building effective defenses.

期刊:arXiv, 2018年4月6日
网址:
http://www.zhuanzhi.ai/document/82f0f9c5c92d2529a224eddf8aba4099
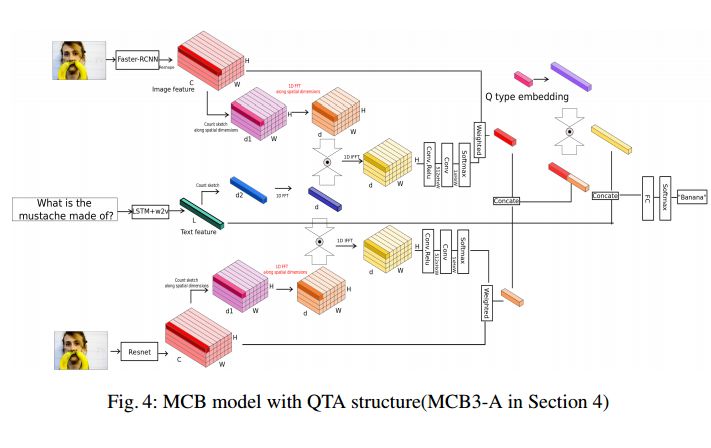
3. Question Type Guided Attention in Visual Question Answering(基于问题类型引导注意力的视觉问答)
作者:Yang Shi,Tommaso Furlanello,Sheng Zha,Animashree Anandkumar
机构:University of California,University of Southern California
摘要:Visual Question Answering (VQA) requires integration of feature maps with drastically different structures and focus of the correct regions. Image descriptors have structures at multiple spatial scales, while lexical inputs inherently follow a temporal sequence and naturally cluster into semantically different question types. A lot of previous works use complex models to extract feature representations but neglect to use high-level information summary such as question types in learning. In this work, we propose Question Type-guided Attention (QTA). It utilizes the information of question type to dynamically balance between bottom-up and top-down visual features, respectively extracted from ResNet and Faster R-CNN networks. We experiment with multiple VQA architectures with extensive input ablation studies over the TDIUC dataset and show that QTA systematically improves the performance by more than 5% across multiple question type categories such as "Activity Recognition", "Utility" and "Counting" on TDIUC dataset. By adding QTA on the state-of-art model MCB, we achieve 3% improvement for overall accuracy. Finally, we propose a multi-task extension to predict question types which generalizes QTA to applications that lack of question type, with minimal performance loss.
期刊:arXiv, 2018年4月6日
网址:
http://www.zhuanzhi.ai/document/d612c4a406f3ae6232b0633c1e6aa433
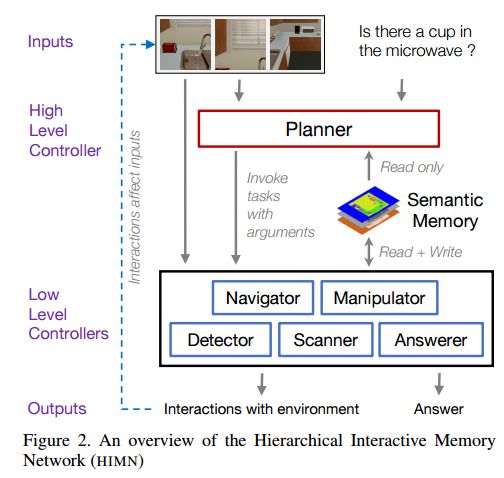
4. IQA: Visual Question Answering in Interactive Environments(IQA:交互环境的视觉问答)
作者:Daniel Gordon,Aniruddha Kembhavi,Mohammad Rastegari,Joseph Redmon,Dieter Fox,Ali Farhadi
机构:, University of Washington
摘要:We introduce Interactive Question Answering (IQA), the task of answering questions that require an autonomous agent to interact with a dynamic visual environment. IQA presents the agent with a scene and a question, like: "Are there any apples in the fridge?" The agent must navigate around the scene, acquire visual understanding of scene elements, interact with objects (e.g. open refrigerators) and plan for a series of actions conditioned on the question. Popular reinforcement learning approaches with a single controller perform poorly on IQA owing to the large and diverse state space. We propose the Hierarchical Interactive Memory Network (HIMN), consisting of a factorized set of controllers, allowing the system to operate at multiple levels of temporal abstraction. To evaluate HIMN, we introduce IQUAD V1, a new dataset built upon AI2-THOR, a simulated photo-realistic environment of configurable indoor scenes with interactive objects. IQUAD V1 has 75,000 questions, each paired with a unique scene configuration. Our experiments show that our proposed model outperforms popular single controller based methods on IQUAD V1. For sample questions and results, please view our video: https://youtu.be/pXd3C-1jr98.
期刊:arXiv, 2018年4月6日
网址:
http://www.zhuanzhi.ai/document/9b21295cf8d06b563639339aa7c5ac34
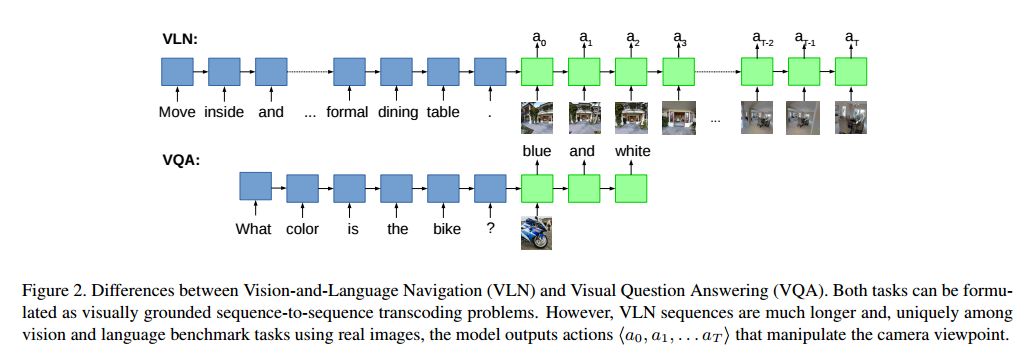
5. Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments(Vision-and-Language Navigation)
作者:Peter Anderson,Qi Wu,Damien Teney,Jake Bruce,Mark Johnson,Niko Sünderhauf,Ian Reid,Stephen Gould,Anton van den Hengel
机构:Macquarie University,Queensland University of Technology,University of Adelaide,Australian National University
摘要:A robot that can carry out a natural-language instruction has been a dream since before the Jetsons cartoon series imagined a life of leisure mediated by a fleet of attentive robot helpers. It is a dream that remains stubbornly distant. However, recent advances in vision and language methods have made incredible progress in closely related areas. This is significant because a robot interpreting a natural-language navigation instruction on the basis of what it sees is carrying out a vision and language process that is similar to Visual Question Answering. Both tasks can be interpreted as visually grounded sequence-to-sequence translation problems, and many of the same methods are applicable. To enable and encourage the application of vision and language methods to the problem of interpreting visually-grounded navigation instructions, we present the Matterport3D Simulator -- a large-scale reinforcement learning environment based on real imagery. Using this simulator, which can in future support a range of embodied vision and language tasks, we provide the first benchmark dataset for visually-grounded natural language navigation in real buildings -- the Room-to-Room (R2R) dataset.
期刊:arXiv, 2018年4月6日
网址:
http://www.zhuanzhi.ai/document/39ff789c654a6703403f697e0e625184
6. Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention for Visual Question Answering(基于稠密对称联合注意力机制视觉语言表示融合的视觉问答)
作者:Duy-Kien Nguyen,Takayuki Okatani
机构:Tohoku University
摘要:A key solution to visual question answering (VQA) exists in how to fuse visual and language features extracted from an input image and question. We show that an attention mechanism that enables dense, bi-directional interactions between the two modalities contributes to boost accuracy of prediction of answers. Specifically, we present a simple architecture that is fully symmetric between visual and language representations, in which each question word attends on image regions and each image region attends on question words. It can be stacked to form a hierarchy for multi-step interactions between an image-question pair. We show through experiments that the proposed architecture achieves a new state-of-the-art on VQA and VQA 2.0 despite its small size. We also present qualitative evaluation, demonstrating how the proposed attention mechanism can generate reasonable attention maps on images and questions, which leads to the correct answer prediction.
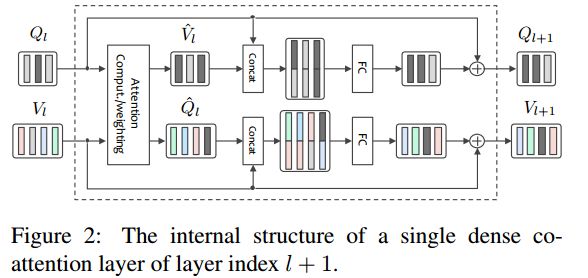
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/c12b18f71fd47e9773e1a66dd45420fb
7. VizWiz Grand Challenge: Answering Visual Questions from Blind People(VizWiz Grand Challenge)
作者:Danna Gurari,Qing Li,Abigale J. Stangl,Anhong Guo,Chi Lin,Kristen Grauman,Jiebo Luo,Jeffrey P. Bigham
机构:University of Texas at Austin,University of Science and Technology of China,University of Colorado Boulder,Carnegie Mellon University,University of Rochester
摘要:The study of algorithms to automatically answer visual questions currently is motivated by visual question answering (VQA) datasets constructed in artificial VQA settings. We propose VizWiz, the first goal-oriented VQA dataset arising from a natural VQA setting. VizWiz consists of over 31,000 visual questions originating from blind people who each took a picture using a mobile phone and recorded a spoken question about it, together with 10 crowdsourced answers per visual question. VizWiz differs from the many existing VQA datasets because (1) images are captured by blind photographers and so are often poor quality, (2) questions are spoken and so are more conversational, and (3) often visual questions cannot be answered. Evaluation of modern algorithms for answering visual questions and deciding if a visual question is answerable reveals that VizWiz is a challenging dataset. We introduce this dataset to encourage a larger community to develop more generalized algorithms that can assist blind people.
期刊:arXiv, 2018年4月2日
网址:
http://www.zhuanzhi.ai/document/710dfb4f5e0a252b6265c8ef05962a86
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知




