让计算机明白「天天」代表「每一天」之后,如何避免让它认为「爸爸」代表「每个爸」

AI 研习社按:类比推理是反映语言规则的一种高效方式,本文将介绍一种汉语语言推理任务,论文作者来自北京师范大学和中国人民大学,论文题为:汉语形态语义关系的类比推理(论文地址:http://aclweb.org/anthology/P18-2023)。该论文在 ACL 2018大会上发表,相关资源在Github发布后获得了超过2000星好评。AI 科技评论将论文内容概括如下(感谢论文作者对本文的审核和修改)。
类比推理可以很好地刻画语言规则,举例说明,「人」等价于person,「人人」则等价于英文的 every person,那么如果「天」代表 day,我们就可以类比推理「天天」代表 every day。目前类比推理也是评估词嵌入的一个可靠方法。类比推理还可以用于词形转换、语义关系探测和翻译未知词等任务。但是不同语言之间拥有很大的形态差异,类比推理针对各个语言的研究也不尽相同。以汉语来说,汉语是公认的缺乏词形变化的分析性语言。目前汉语类比推理的相关工作也屈指可数,仅有的中文类比数据集也只是英文数据集的部分翻译,且数据规模较小,只包含 134个 中文词,并且不涉及到任何语法知识。因此,作者团队决定深入研究汉语类比推理,并且发布了一个标准 benchmark 用以评估中文词嵌入(地址见文末)。
在词法关系方面,作者主要研究了两个内容,一是重叠(Reduplication),二是半词缀(Semi-affixation)。所谓重叠就是词语中的部分汉字以一定的形式发生重叠,从而引起语法或语义差异,作者总结出六种重叠模式,如下图所示。
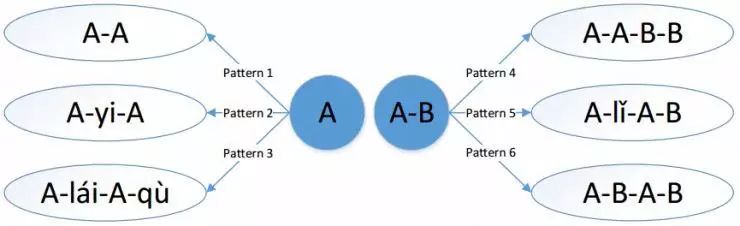
以 A-A 为例,对于汉语中的名词来说,这种结构可以表示“亲属关系”(爸->爸爸)或者表示“每一个”(天->天天),对于动词来说,这种结构可以表示动作时间短暂或尝试(看->看看),这种结构还能将形容词转为副词(深->深深)。
由于汉语缺乏典型的词缀,一些成分既发挥了类似词缀的作用同时又能当作独立使用的语素,这些成分按刘月华老师的观点称之为半词缀。目前作者团队总结了 21 个半前缀,和 41 个半后缀。例如,半前缀可以将数词变为序数词,如「第」(一->第一),半后缀还有将形容词名词化的能力,如「子」(胖->胖子)
在语义关系方面,作者团队从地理、历史、自然和人物四个方面提出了 28 种语义关系。举个地域方面的例子,「浙江」是省名,「浙」是「浙江」简称,「杭州」是「浙江」省会,「越剧」是「浙江」代表戏剧,这就是他们之间的语义关系。通过语义关系可以形成类比问题(如「皖」是「安徽」的省会,那么「浙」是哪个省的省会?)。
为了满足汉语类比推理任务的要求,作者团队自建了 CA8 数据集(共17813 个问题),包含大量的类比问题,对语法和语义都有涉及。CA8 相较于之前翻译自英文数据集的 CA_translated 有很大改进。如下图所示。
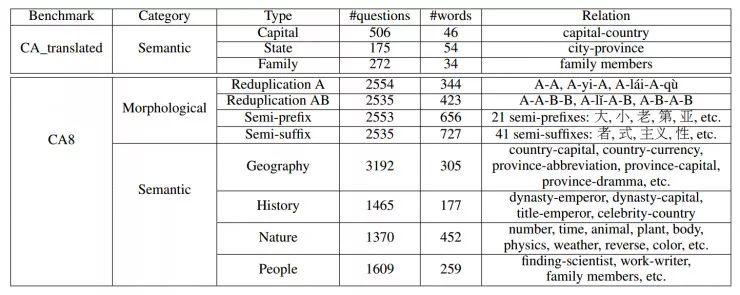
最后,作者的实验基于 68 种形态关系和 28 种语义关系,他们采用基于词向量的计算方法来挑战这个任务。实验结果表明,向量表示模型、上下文特征和训练语料库都对汉语类比推理有重要影响。同时实验也证明了 CA8 的确是评价汉语词嵌入的可靠 benchmark。 CA8 和同期发布的上百种中文词向量资源将成为汉语 NLP 任务的坚实基础。论文相关资源和代码在 Github 发布以来,已获得超过2000星,是今年NLP领域最受欢迎的项目之一。
以上就是 AI 研习社对于这篇论文的全部介绍。
详情请查看论文:
http://aclweb.org/anthology/P18-2023
Github项目:
https://github.com/Embedding/Chinese-Word-Vectors
想知道关于自然语言处理的更多知识?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~



