NeurIPS 2019 | 一种对噪音标注鲁棒的基于信息论的损失函数
机器之心经授权转载
本文是第三十三届神经信息处理系统大会(NeurIPS 2019)入选论文《L_DMI:一种对噪音标注鲁棒的基于信息论的损失函数(L_DMI: A Novel Information-theoretic Loss Function for Training Deep Nets Robust to Label Noise)》的解读。该论文由北京大学前沿计算研究中心助理教授孔雨晴博士和北京大学数字视频编解码技术国家工程实验室教授、前沿计算研究中心副主任王亦洲共同指导,由 2016 级图灵班本科生许逸伦、曹芃(共同一作)合作完成。

论文链接:https://arxiv.org/abs/1909.03388
代码链接:https://github.com/Newbeeer/L_DMI
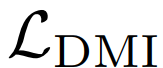 ,它是基于一种新的互信息,DMI(Determinant based Mutual Information)设计的。DMI 是一种对香农互信息(Shannon Mutual Information)的推广,它不仅像香农互信息一样满足信息单调性(information-monotone),还满足相对不变性(relatively-invariant)等性质。是首个不仅对噪音模式没有限制,并且能够无需先验信息而直接应用到任何现存的用于分类的神经网络中的损失函数。实际上,当噪音满足条件独立(conditional independence)假设时,即噪音标签和具体数据条件独立时,我们有下列等式成立:
,它是基于一种新的互信息,DMI(Determinant based Mutual Information)设计的。DMI 是一种对香农互信息(Shannon Mutual Information)的推广,它不仅像香农互信息一样满足信息单调性(information-monotone),还满足相对不变性(relatively-invariant)等性质。是首个不仅对噪音模式没有限制,并且能够无需先验信息而直接应用到任何现存的用于分类的神经网络中的损失函数。实际上,当噪音满足条件独立(conditional independence)假设时,即噪音标签和具体数据条件独立时,我们有下列等式成立:
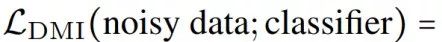
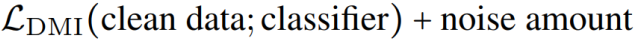 作为损失函数在噪音标注上训练分类器和在正确标注(clean label)上训练分类器没有区别。
作为损失函数在噪音标注上训练分类器和在正确标注(clean label)上训练分类器没有区别。
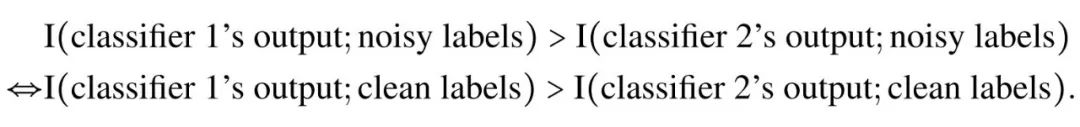
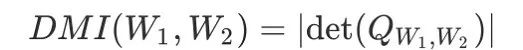
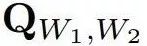 是 W_1,W_2 联合分布的矩阵表示。
是 W_1,W_2 联合分布的矩阵表示。
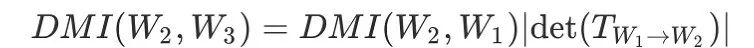
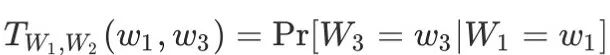 :
:
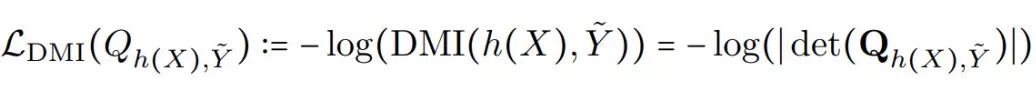
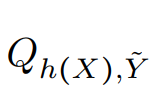 是 h(X) 和
是 h(X) 和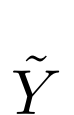 的联合分布;
的联合分布;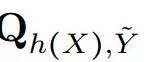 是
是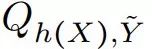 的 C×C 的矩阵形式。h(X) 的的随机性来自于 h 和随机变量 X。
的 C×C 的矩阵形式。h(X) 的的随机性来自于 h 和随机变量 X。
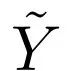 之间的 -log-DMI。在实际中,DMI 可以通过矩阵乘积快速计算,如下图所示:
之间的 -log-DMI。在实际中,DMI 可以通过矩阵乘积快速计算,如下图所示:
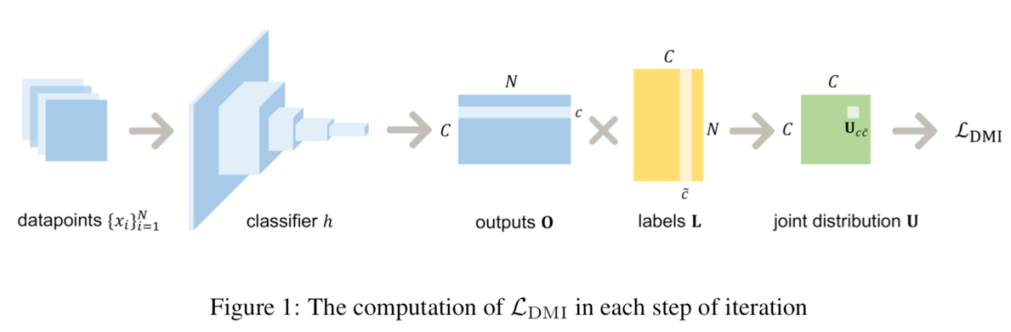
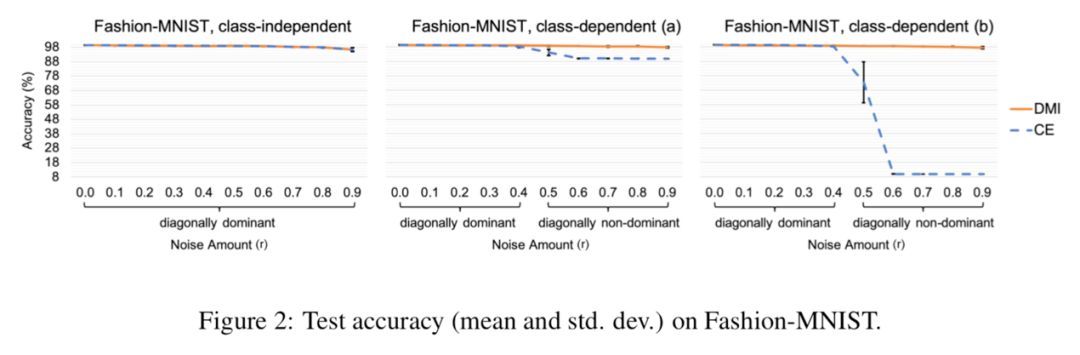
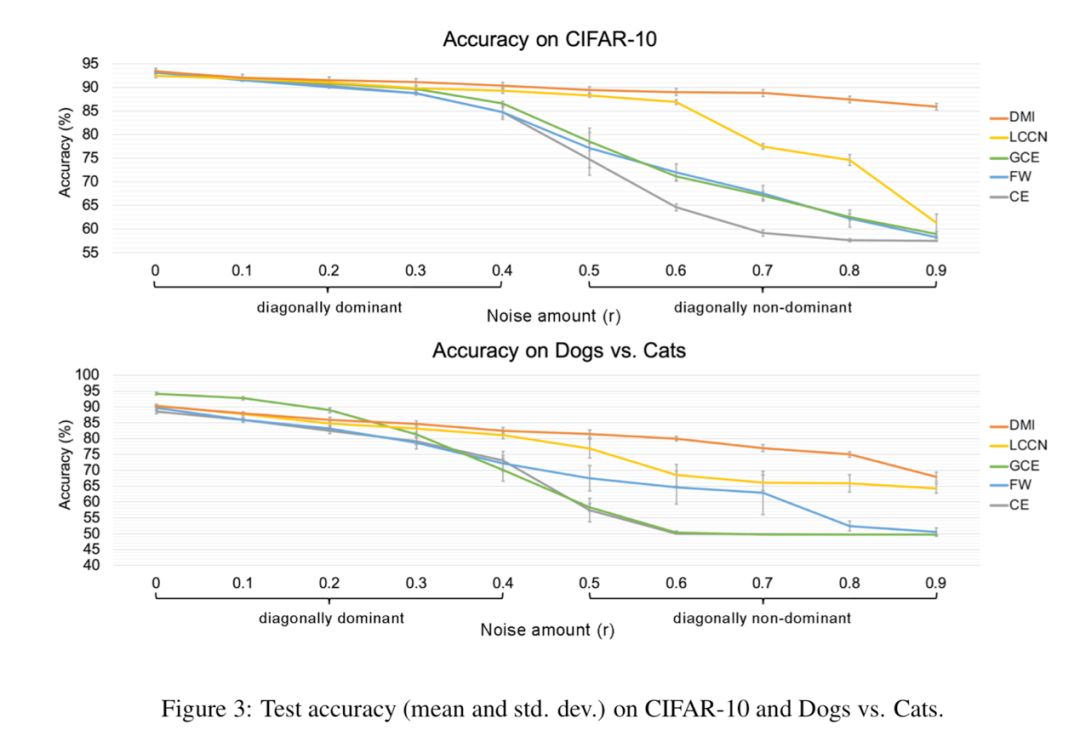
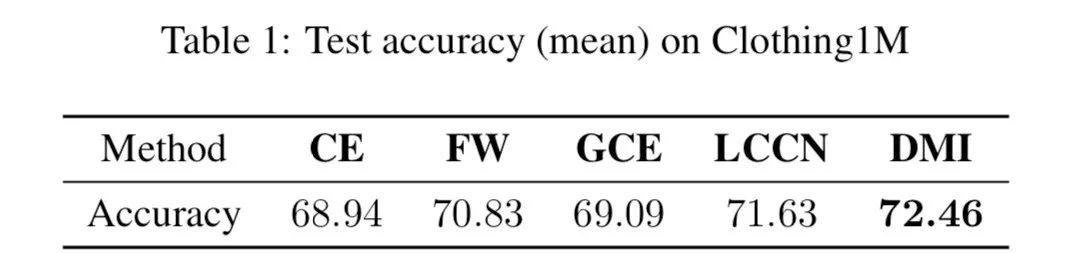
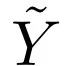 在真实标签 Y 的条件下相互独立和噪音转移矩阵满秩条件下,由上面定理的结论,我们在文章的主定理中证明了 是合理的(legal)、噪音鲁棒的(noise-robust)和信息单调的(information-monotone)。其中噪音鲁棒这一重要性质能够使得我们用作为损失函数时,在带噪音标签和在不带噪音的标签的数据集上训练得到的最优分类器相同,也满足文首所提的性质。
在真实标签 Y 的条件下相互独立和噪音转移矩阵满秩条件下,由上面定理的结论,我们在文章的主定理中证明了 是合理的(legal)、噪音鲁棒的(noise-robust)和信息单调的(information-monotone)。其中噪音鲁棒这一重要性质能够使得我们用作为损失函数时,在带噪音标签和在不带噪音的标签的数据集上训练得到的最优分类器相同,也满足文首所提的性质。

点击阅读原文,立即访问。
登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年3月5日
Arxiv
4+阅读 · 2020年3月5日



相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
相关资讯
相关论文
Arxiv
4+阅读 · 2020年3月5日