干货 | 一文详解隐含狄利克雷分布(LDA)

作者 | 玉龍
一、简介
隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA)是由 David M. Blei、Andrew Y. Ng、Michael I. Jordan 在2003年提出的,是一种词袋模型,它认为文档是一组词构成的集合,词与词之间是无序的。一篇文档可以包含多个主题,文档中的每个词都是由某个主题生成的,LDA给出文档属于每个主题的概率分布,同时给出每个主题上词的概率分布。LDA是一种无监督学习,在文本主题识别、文本分类、文本相似度计算和文章相似推荐等方面都有应用。
本文将从贝叶公式、Gamma函数、二项分布、Beta分布、多项式分布、Dirichlet分布、共轭先验分布、马氏链及其平稳分布、MCMC、Gibbs Sampling、EM算法、Unigram Model、贝叶斯Unigram Model、PLSA、LDA 几方面介绍LDA模型,需要读者具备一定的概率论和微积分知识。
二、基础知识
▌1.1 贝叶公式
贝叶斯学派的最基本的观点是:任一个未知量 θ 都可看作一个随机变量,应该用一个概率分布去描述对 θ 的未知状况,这个概率分布是在抽样前就有关于 θ 的先验信息的概率陈述,这个概率分布被称为先验分布。
从贝叶斯观点看,样本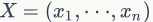

这个联合密度函数是综合了总体信息和样本信息,常称为似然函数,记为 L(θ') 。
由于 θ' 是设想出来的,它仍然是未知的,它是按先验分布 p(θ) 产生的,要把先验信息进行综合,不能只考虑 θ',而应对 θ 的一切可能加以考虑,故要用 p(θ) 参与进一步综合,所以样本 X 和参数 θ 的联合分布(三种可用的信息都综合进去了):

我们的任务是要对未知数 θ 作出统计推断,在没有样本信息时,人们只能根据先验分布对 θ 作出推断。在有样本观察值

其中 p(X) 是 X 的边缘密度函数。
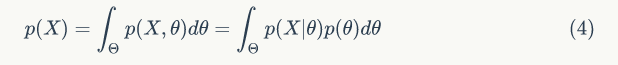
它与 θ 无关,p(X) 中不含 θ 的任何信息。因此能用来对 θ 作出推断的仅是条件分布 p(θ|X):
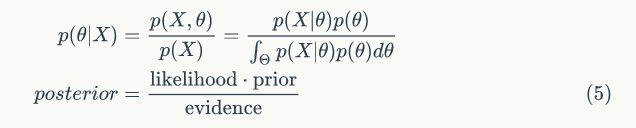
这就是贝叶斯公式的密度函数形式,在样本 X 给定下,θ 的条件分布被称为 θ 的后验分布。它是集中了总体、样本和先验等三种信息中有关 θ 的一切信息,而又是排除一切与 θ 无关的信息之后得到的结果,故基于后验分布 p(θ|X) 对 θ 进行统计推断是更合理的。
一般说来,先验分布 p(θ) 是反映人们在抽样前对 θ 的认识,后验分布 p(θ|X) 是反映人们在抽样后对 θ 的认识,之间的差异是由于样本的出现后人们对 θ 认识的一种调整,所以后验分布 p(θ|X) 可以看作是人们用总体信息和样本信息(抽样信息)对先验分布 p(θ) 作调整的结果。下面我们介绍三种估计方法:
1. 最大似然估计(ML)
最大似然估计是找到参数 θ 使得样本 X 的联合概率最大,并不会考虑先验知识,频率学派和贝叶斯学派都承认似然函数,频率学派认为参数 θ 是客观存在的,只是未知。求参数 θ 使似然函数最大,ML估计问题可以用下面公式表示:
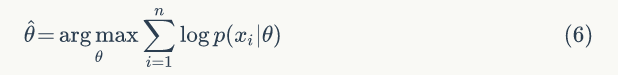
通常可以令导数为 0 求得 θ 的值。ML估计不会把先验知识考虑进去,很容易出现过拟合的现象。我们举个例子,抛一枚硬币,假设正面向上的概率为 p,抛了 N 次,正面出现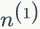
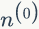
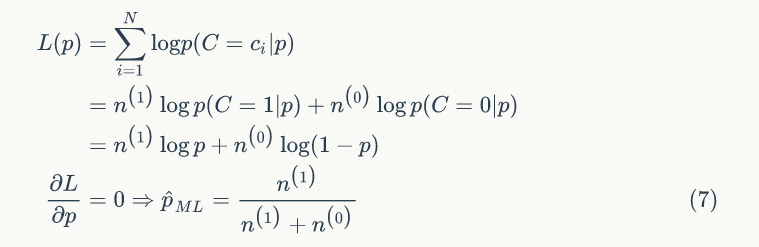
如果 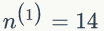
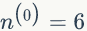

2. 最大后验估计(MAP)
MAP 是为了解决 ML 缺少先验知识的缺点,刚好公式 (5) 后验概率集中了样本信息和先验信息,所以 MAP 估计问题可以用下面公式表示:
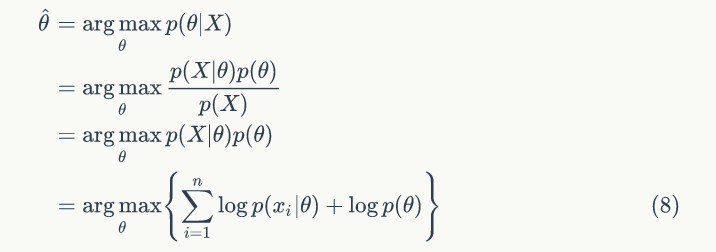
MAP 不仅希望似然函数最大,还希望自己出现的先验概率也最大,加入先验概率,起到正则化的作用,如果 θ 服从高斯分布,相当于加一个 L2 范数正则化,如果 θ 服从拉普拉斯分布,相当于加一个 L1 范数正则化。我们继续前面抛硬币的例子,大部分人认为应该等于0.5,那么还有少数人认为 p 取其他值,我们认为 p 的取值服从 Beta 分布。
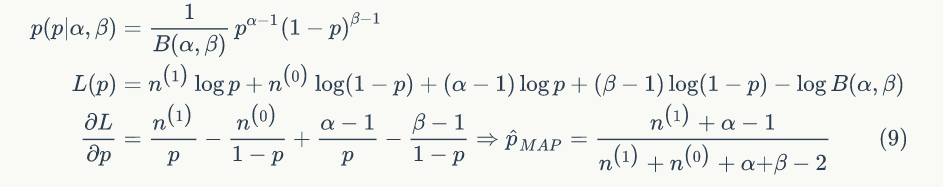
我们取 α=5,β=5,即 p 以最大的概率取0.5,得到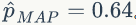
3. 贝叶斯估计
前面介绍的 ML 和 MAP 属于点估计,贝叶斯估计不再把参数 θ 看成一个未知的确定值,而是看成未知的随机变量,利用贝叶斯定理结合新的样本信息和参数 θ 的先验分布,来得到 θ 的新的概率分布(后验分布)。贝叶斯估计的本质是通过贝叶斯决策得到参数 θ 的最优估计 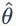
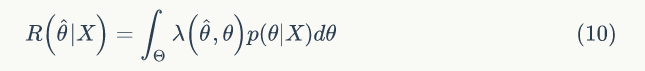
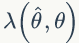
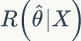
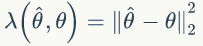
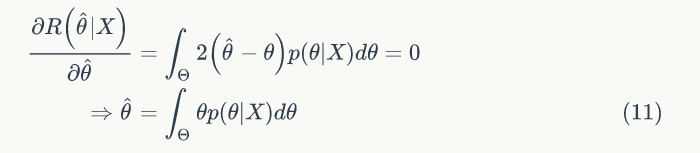
所以贝叶斯估计值为在样本 X 条件下 θ 的期望值,贝叶斯估计的步骤为:
确定参数 θ 的先验分布 P(θ)
利用贝叶斯公式,求 θ 的后验分布:
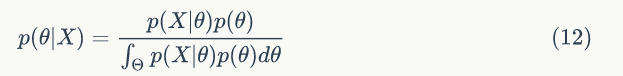
求出贝叶斯的估计值:

我们继续前面的抛硬币的例子,后验概率:
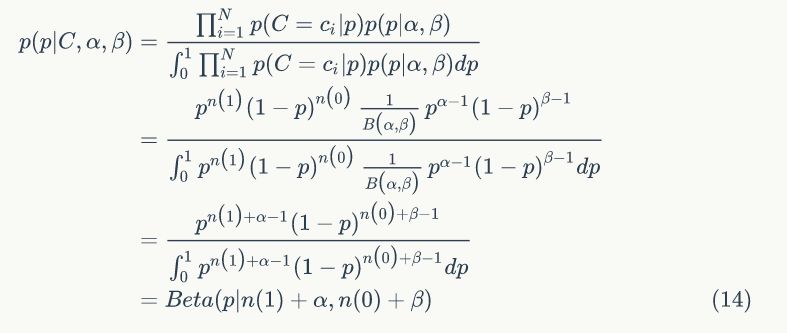
其中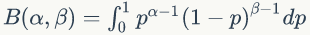
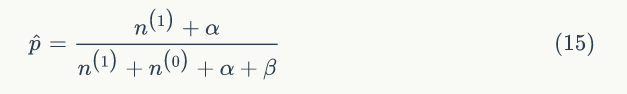
▌1.2 Gamma函数

通过分部积分的方法,可以得到一个递归性质。
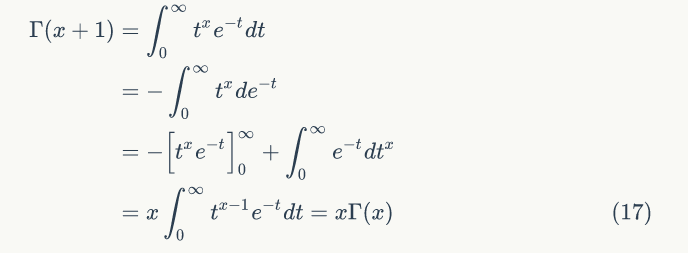
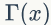
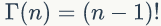
▌1.3 二项分布
在概率论中,试验 E 只有两个可能结果: A 及 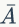
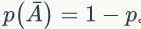
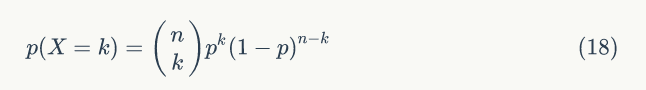
▌1.4 Beta分布
Beta分布是指一组定义在(0,1)区间的连续概率分布,其概率密度函数是:
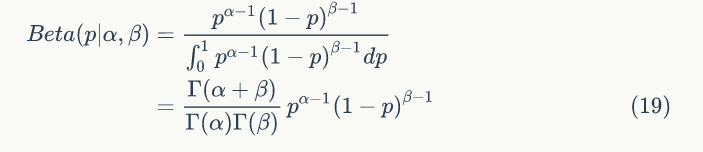
1)
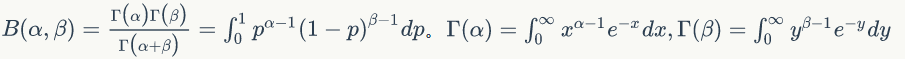
证明:
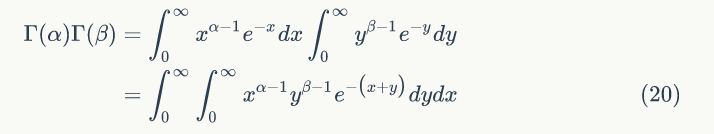
令 t=x+y,当 y=0,t=x ; y=∞,t=∞,可得:
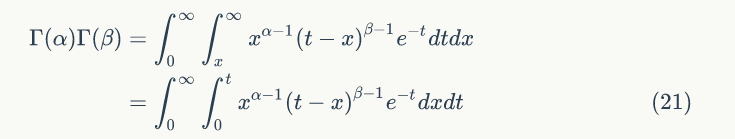
令 x=μt,可得:
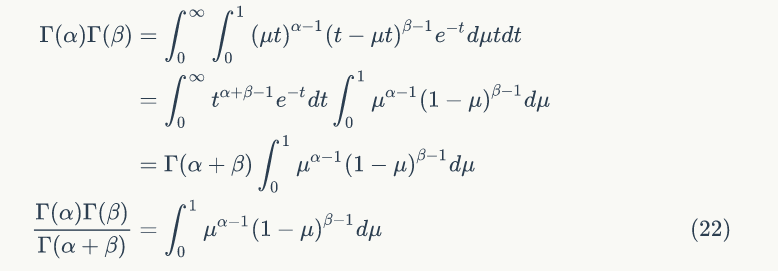
2)期望

证明:
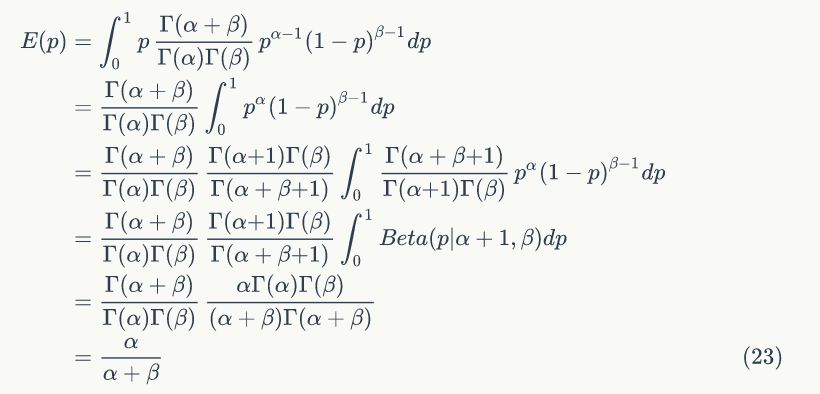
▌1.5 多项式分布
多项式分布是二项式分布的推广,二项式分布做 n 次伯努利试验,规定每次试验的结果只有两个,而多项式分布在 N 次独立试验中结果有 K 种,且每种结果都有一个确定的概率 p,仍骰子是典型的多项式分布。
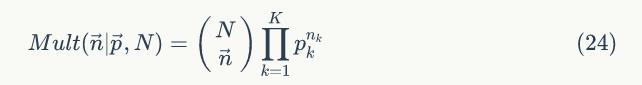
其中
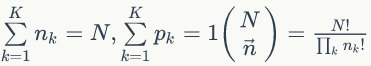
▌1.6 Dirichlet分布
Dirichlet 分布是 Beta 分布在高维度上的推广,概率密度函数是:
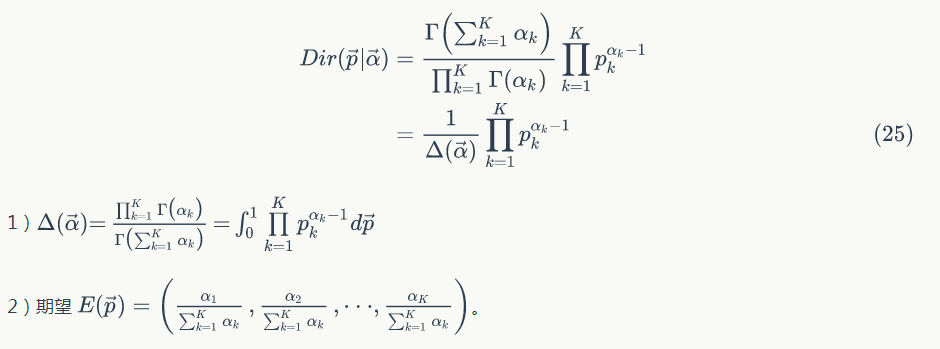
▌1.7 共轭先验分布
在贝叶斯中,如果后验分布与先验分布属于同类分布,则先验分布与后验分布被称为共轭分布,而先验分布被称为似然函数的共轭先验。
1.Beta-Binomial共轭
1)先验分布
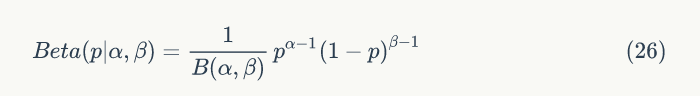
2)二项式似然函数
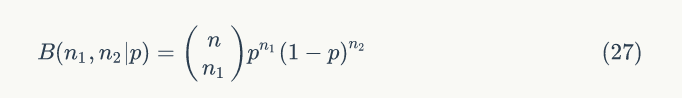
3)后验分布
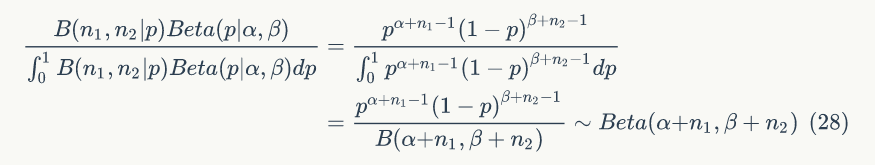
即可以表达为
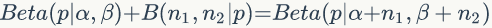
取一个特殊情况理解
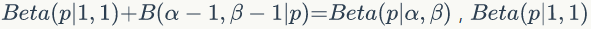
Beta(p|1,1) 恰好是均匀分布 uniform(0,1) ,假设有一个不均匀的硬币抛出正面的概率为 p,抛出 n 次后出现正面和反面的次数分别是 n1 和 n2 ,开始我们对硬币不均匀性一无所知,所以应该假设 p~ uniform(0,1) ,当有了试验样本,我们加入样本信息对 p 的分布进行修正, p 的分布由均匀分布变为 Beta 分布。
2.Dirichlet-Multinomial共轭
1)先验分布
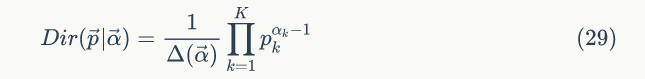
2)多项分布似然函数
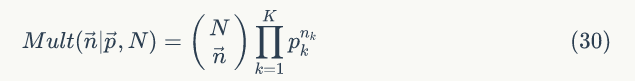
3)后验分布
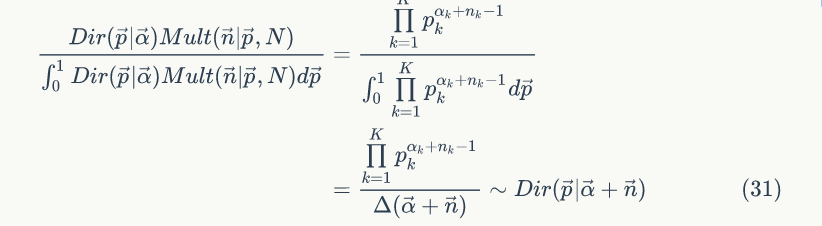
即可以表达为
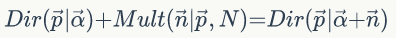
▌1.8 马氏链及其平稳分布
马氏链的数学定义很简单,状态转移的概率只依赖于前一个状态。
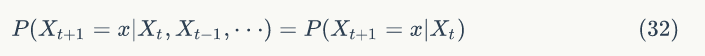
看一个马氏链的具体例子,马氏链表示股市模型,共有三种状态:牛市(Bull market)、熊市(Bear market)、横盘(Stagnant market),每一个转态都以一定的概率转化到下一个状态,如图1.1所示。
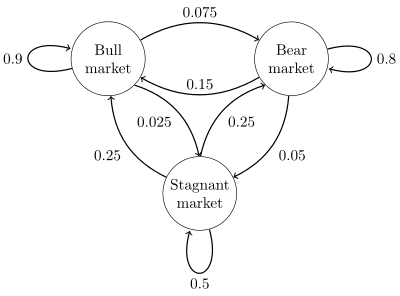
图1.1
这个概率转化图可以以矩阵的形式表示,如果我们定义矩阵 P 某一位置 (i,j) 的值为 P (j|i),表示从状态 i 转化到状态 j 的概率,这样我们可以得到马尔科夫链模型的状态转移矩阵为:
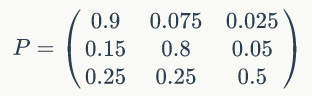
假设初始概率分布为
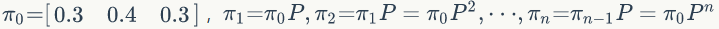
从第60轮开始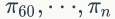

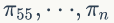
的值保持不变,为[0.625 0.3125 0.0625] 。两次给定不同的初始概率分布,最终都收敛到概率分布 π=[0.625 0.3125 0.0625] ,也就是说收敛的行为和初始概率分布 π0 无关,这个收敛的行为主要是由概率转移矩阵 P 决定的,可以计算下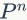
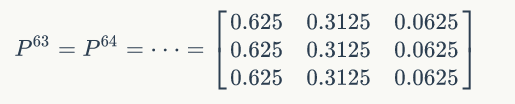
当 n 足够大的时候,
定理1.1 如果一个非周期马氏链具有转移概率矩阵 P,且它的任何两个状态是连通的,那么 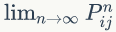

关于上述定理,给出几点解释:
1) 马氏链的状态数可以是有限的,也可以是无限的,因此可以用于连续概率分布和离散概率分布。
2) 非周期马氏链:马氏链的状态转化不是循环的,如果是循环的则永远不会收敛,我们遇到的一般都是非周期马氏链。对于任意某一状态i,d 为集合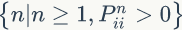
3) 任何两个状态是连通的:从任意一个状态可以通过有限步到达其他的任意状态,不会出现条件概率一直为0导致不可达的情况。
4) π 称为马氏链的平稳分布。
如果从一个具体的初始状态 x0 开始,沿着马氏链按照概率转移矩阵做跳转,那么可以得到一个转移序列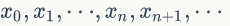
▌1.9 MCMC
1. 接受-拒绝采样
对于不常见的概率分布 π(x) 样本,使用接受-拒绝采样对可采样的分布 q(x) 进行采样得到,如图1.2所示,采样得到 Mq(x) 的一个样本 x0,从均匀分布 (0,Mq(x0) )中采样得到一个值 μ0 ,如果 μ0 落在图中灰色区域则拒绝这次采样,否则接受样本 x0,重复上面过程得到 n 个接受的样本,则这些样本服从 π(x) 分布,具体过程见算法1.1。
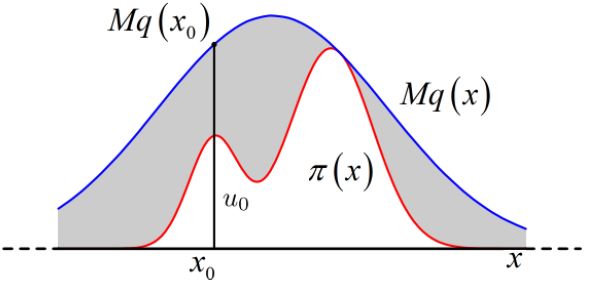
图1.2

下面我们来证明下接受-拒绝方法采样得到的样本服从 π(x) 分布。
证明:accept x 服从 π(x) 分布,即 p(x|accept) =π(x)。

2. MCMC
给定概率分布 p(x),希望能够生成它对应的样本,由于马氏链能收敛到平稳分布,有一个很好的想法:如果我们能构造一个转移矩阵为 P 的马氏链,使得该马氏链的平稳分布恰好是 p(x),那么我们从任何一个初始状态出发沿着马氏链转移,得到一个转移序列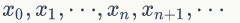
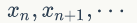
定理1.2(细致平稳条件) 如果非周期马氏链的转移矩阵 P 和分布 π(x) 满足:

则 π(x) 是马氏链的平稳分布。
证明很简单,有公式(34)得:
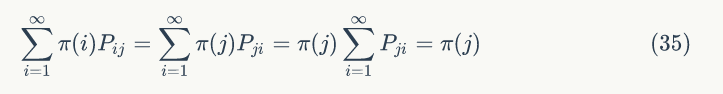
πP=π,满足马氏链的收敛性质。这样我们就有了新的思路寻找转移矩阵 P,即只要我们找到矩阵 P 使得概率分布 π(x) 满足细致平稳条件即可。
假设有一个转移矩阵为 Q 的马氏链(Q(i,j) 表示从状态 i 转移到状态 j 的概率),通常情况下很难满足细致平稳条件的,即:

我们对公式(36)进行改造,使细致平稳条件成立,引入 α (i,j) 。
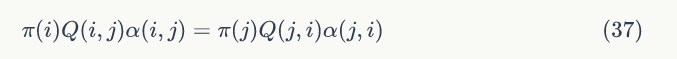
α (i,j) 如何取值才能使公式(37)成立?最简单的我们可以取:

Q' (i,j)=Q (i,j)α (i,j) ,Q' (j,i)=Q (j,i)α (j,i) ,所以我们有:

转移矩阵 Q' 满足细致平稳条件,因此马氏链 Q' 的平稳分布就是 π(x)!
我们可以得到一个非常好的结论,转移矩阵 Q' 可以通过任意一个马氏链转移矩阵 Q 乘以 α (i,j) 得到, α (i,j) 一般称为接受率,其取值范围为[0,1] ,可以理解为一个概率值,在原来的马氏链上,从状态 i 以 Q (i,j) 的概率跳转到状态 j 的时候,我们以一定的概率 α (i,j) 接受这个转移,很像前面介绍的接受-拒绝采样,那里以一个常见的分布通过一定的接受-拒绝概率得到一个不常见的分布,这里以一个常见的马氏链状态转移矩阵 Q 通过一定的接受-拒绝概率得到新的马氏链状态转移矩阵 Q'。
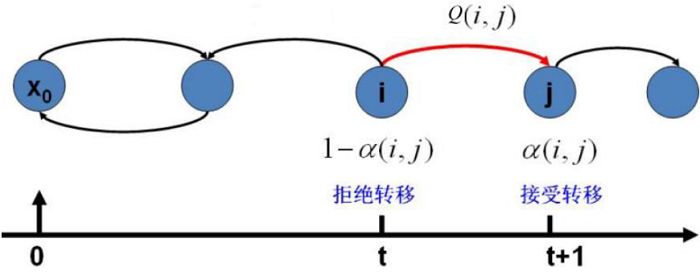
图1.3
总结下MCMC的采样过程。

MCMC采样算法有一个问题,如果接受率 α (xt,x') 比较小,马氏链容易原地踏步,拒绝大量的跳转,收敛到平稳分布 π(x) 的速度很慢,有没有办法可以使 α (xt,x') 变大?
3. M-H采样
M-H采样可以解决MCMC采样接受概率过低问题,回到公式(37),若α (i,j)=0.1,α (j,i)=0.2,即:
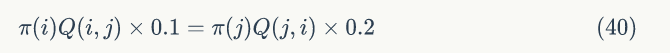
公式(40)两边同时扩大5倍,仍然满足细致平稳条件,即:
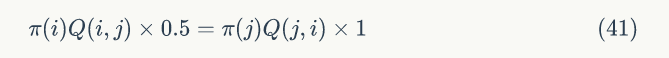
所以我们可以把公式(37)中的 α (i,j) 和 α (j,i) 同比例放大,使得其中最大的放大到 1,这样提高了采样中的接受率,细致平稳条件也没有打破,所以可以取:
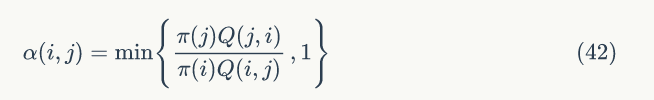

提出一个问题:按照MCMC中介绍的方法把 Q→Q' ,是否可以保证 Q' 每行加和为1?
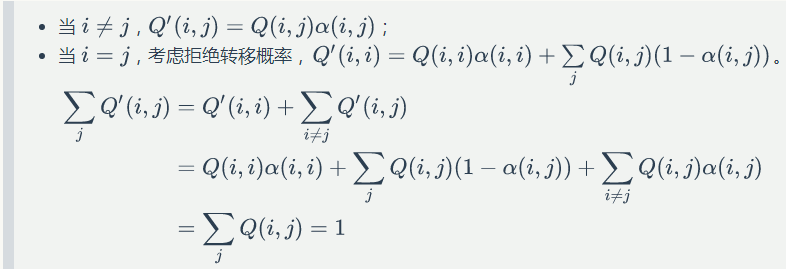
▌1.10 Gibbs Sampling
对于高维的情形,由于接受率 α ≤ 1,M-H 算法效率不够高,我们能否找到一个转移矩阵 Q 使得接受率 α =1 呢?从二维分布开始,假设p(x,y) 是一个二维联合概率分布,考察某个特征维度相同的两个点 A(x1,y1) 和 B(x1,y2) ,容易发现下面等式成立:
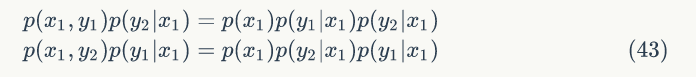
所以可得:
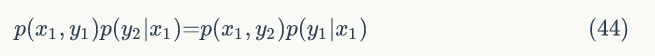
也就是:
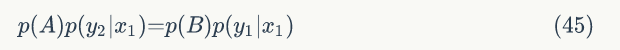
观察细致平稳条件公式,我们发现在 x=x1 这条直线上,如果用条件分布p(y|x1) 作为任何两点之间的转移概率,那么任何两点之间的转移都满足细致平稳条件。同样的,在 y=y1 这条直线上任取两点 A(x1,y1) 和 C(x2,y1) ,我们可以得到:
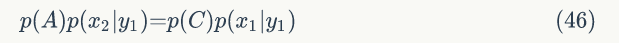
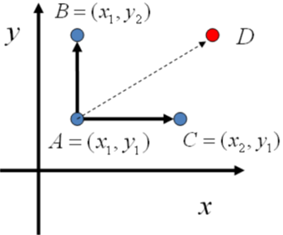
图1.4
基于上面的发现,我们可以构造分布 p(x,y) 的马氏链的状态转移矩阵 Q。
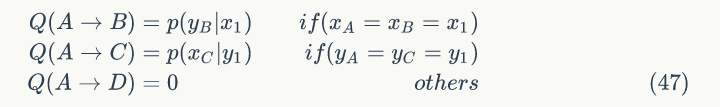
有了上面的转移矩阵 Q ,很容易验证对于平面任意两点 X,Y,都满足细致平稳条件。
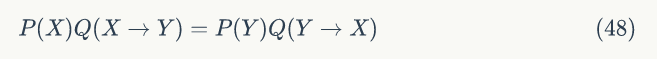
所以这个二维空间上的马氏链将收敛到平稳分布 p(x,y),称为Gibbs Sampling 算法。

整个采样过程中,我们通过轮换坐标轴,得到样本(x0,y0),(x0,y1),(x1,y1),... ,马氏链收敛后,最终得到的样本就是 p(x,y) 的样本。当然坐标轴轮换不是必须的,我们也可以每次随机选择一个坐标轴进行采样,在 t 时刻,可以在 x 轴和 y 轴之间随机的选择一个坐标轴,然后按照条件概率做转移。
图1.5
二维可以很容易推广到高维的情况,在 n 维空间中对于概率分布 p(x1,x2,...xn) 。

▌1.11 EM算法
我们先介绍凸函数的概念,f 的定义域是实数集,若 x∈R 且 f''(x)≥0 ,则 f 是凸函数,若 f''(x)>0,则 f 是严格凸函数;若 x 是向量且 hessian 矩阵 H 是半正定矩阵,则 f 是凸函数,若 H 是正定矩阵,则 f 是严格凸函数。
定理1.3(Jensen不等式) f 的定义域是实数集,且是凸函数,则有:

如果 f 是严格凸函数,只有当 X 是常量,公式(49)等式成立即 E[f(X)]=f(E[X])。
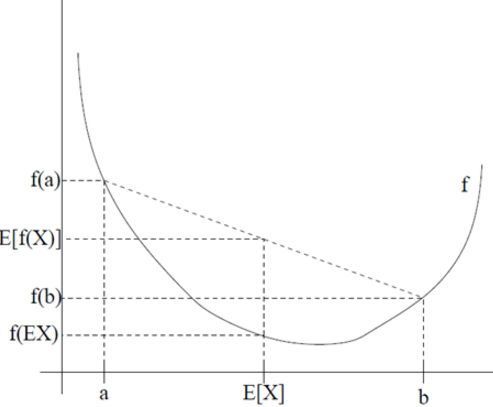
图1.6
假设训练集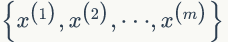

其实我们的目标是找到 z 和 θ 使 l(θ) 最大,也就是分别对 Z 和 θ 求偏导,然后令其为 0,理想是美好的,现实是残酷的,公式(49)求偏导后变的很复杂,求导前要是能把求和符号从对数函数中提出来就好了。EM算法可以有效地解决这个问题,引入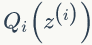
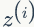
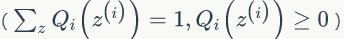
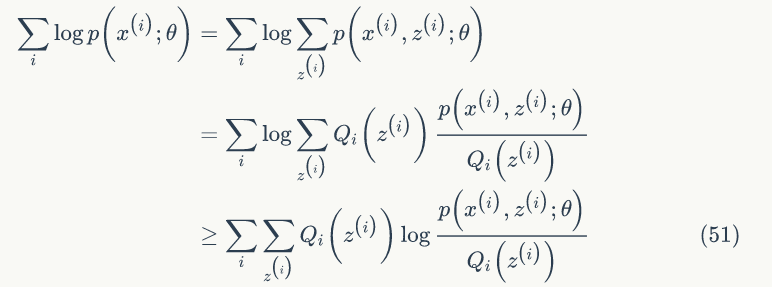
最后一步是利用 Jensen 不等式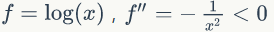
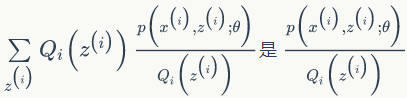
是
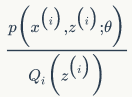
的期望,所以有:
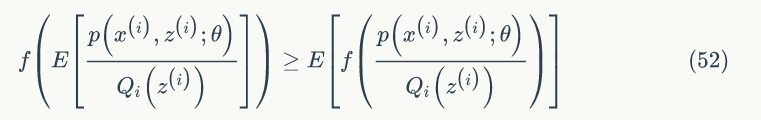
由公式(51)可知,我们可以不断地最大化下界,以提高 l(θ),最终达到最大值。如果固定 θ,那么 l(θ) 的下界就取决于
第一个问题,由Jensen不等式定理中等式成立条件可知,X 为常量,即:

再由 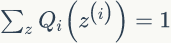
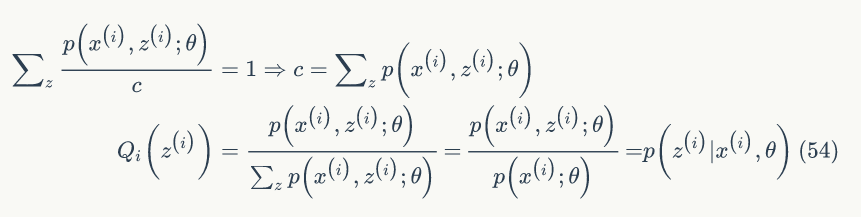
下面我们先给出 EM 算法,然后再讨论第二个问题,E步:固定 θ,根据公式(53)选择 Qi 使得下界等于 l(θ),M步:最大化下界,得到新的 θ 值。EM算法如下:

在我们开始讨论第二个问题,
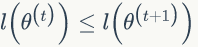
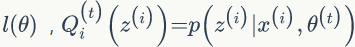
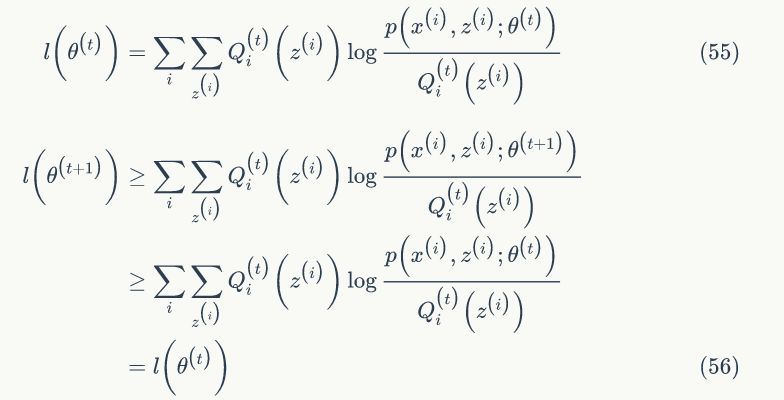
第一个不等式是因为:
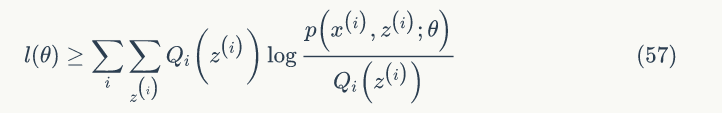
公式(57)中,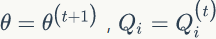
第二个不等式是因为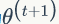
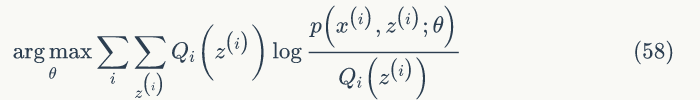
三、LDA
▌2.1 Unigram Model
假设我们的词典中一共有 V 个词,Unigram Model就是认为上帝按照下面游戏规则产生文本的。

Game 2.1 Unigram Model
骰子各个面的概率记为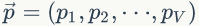
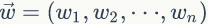

假设我们预料是由 m 篇文档组成即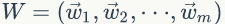

假设预料中总共有 N 个词,每个词 wi 的词频为 ni,那么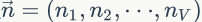
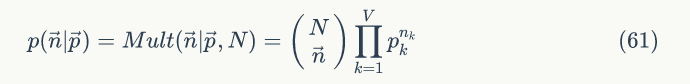
此时公式(60)为:
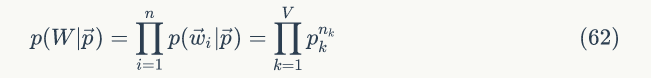
我们需要估计模型中的参数
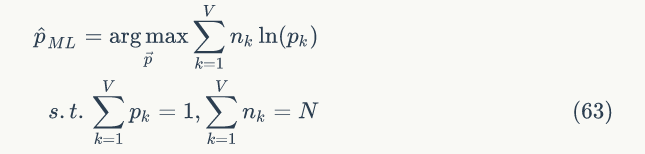
于是参数 pk 的估计值就是:
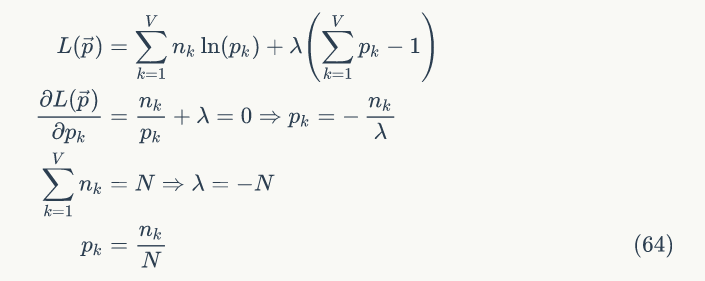
▌2.2 贝叶斯Unigram Model
对于以上模型,统计学家中贝叶斯学派就不同意了,为什么上帝只有一个固定的筛子呢,在贝叶斯学派看来,一切参数都是随机变量,模型中

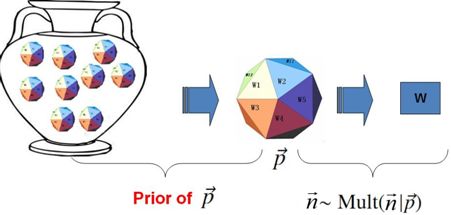
Game 2.2 贝叶斯Unigram Model
上帝这个坛子里面有些骰子数量多,有些骰子数量少,所以从概率分布的角度看,坛子里面的骰子 
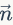
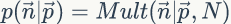
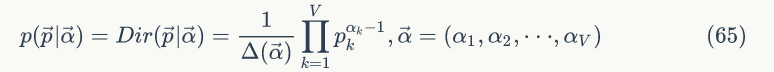
于是,在给定了参数 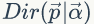
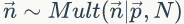
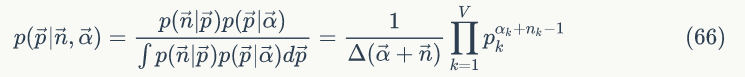
对参数 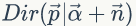
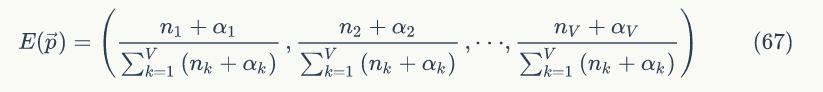
接下来我们计算语料产生的概率,开始并不知道上帝到底用哪个骰子,所以每个骰子都有可能被使用,使用的概率由 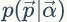
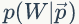
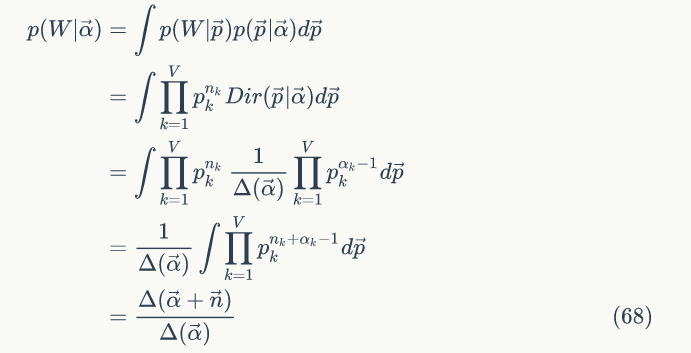
▌2.3 PLSA
1. PLSA Model
概率隐语义分析,是主题模型的一种。上面介绍的Unigram Model相对简单,没有考虑文档有多个主题的情况,一般一篇文档可以由多个主题(Topic)组成,文档中的每个词都是由一个固定的Topic生成的,所以PLSA的游戏规则为:

2. EM算法推导PLSA
PLSA 模型中 doc-topic 和 topic-word 的每个面的概率值是固定的,所以属于点估计,但是PLSA模型既含有观测变量di,wj,又含有隐变量 zk,就不能简单地直接使用极大似然估计法估计模型参数,我们可以采用EM算法估计参数。我们先介绍推导过程用到的符号含义:
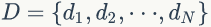
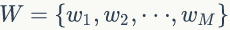
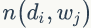
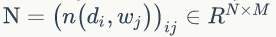
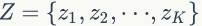
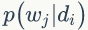
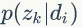
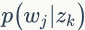
一般给定语料di,wj是可以观测的,zk 是隐变量,不可以直观地观测到。我们定义“doc-word”的生成模型,如图1.8所示。

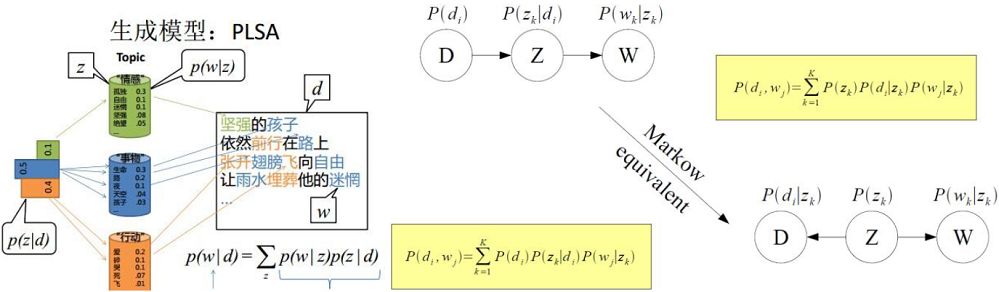
图2.3
下面进入正题,用EM算法进行模型参数估计,似然函数为:
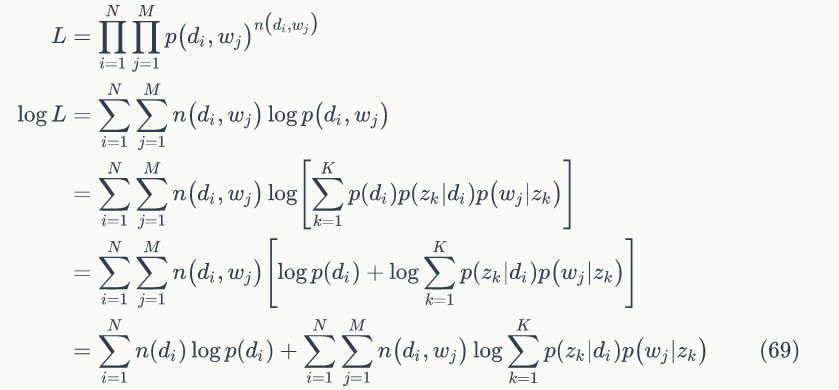
对于给定训练预料,希望公式 (69) 最大化。
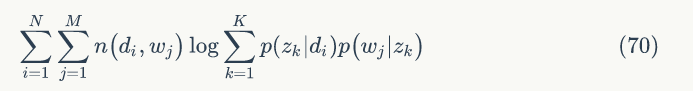
引入 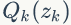
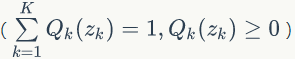
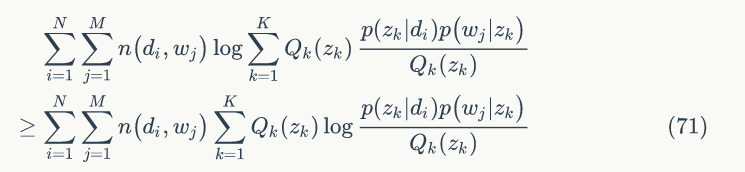
当
时,
公式(71)不等式中等号成立,所以只需要最大化:
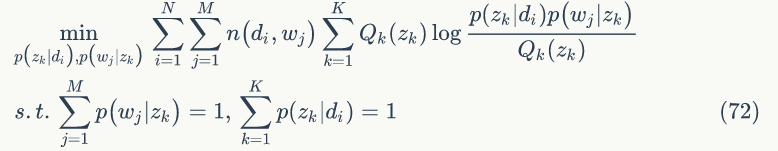
根据拉格朗日乘子法
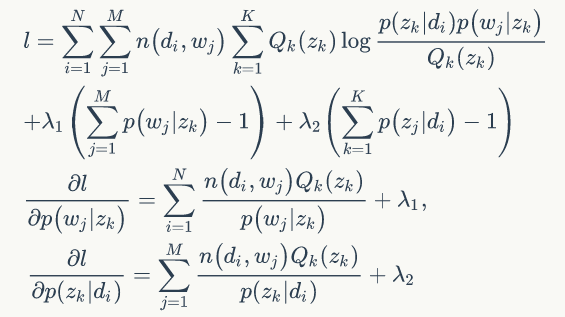
所以可得:
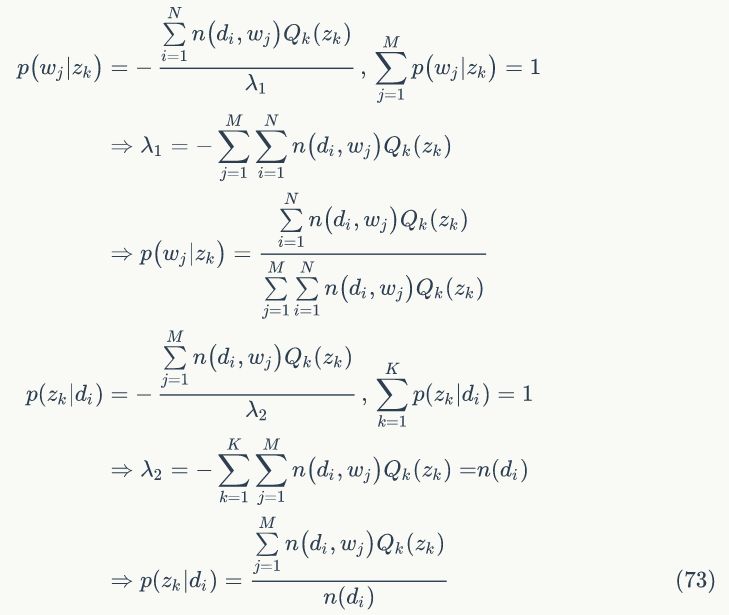
总结EM算法为:
1.E-step 随机初始化变量 ,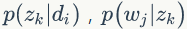
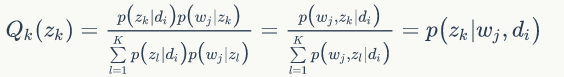
2.M-step 最大化似然函数,更新变量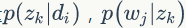
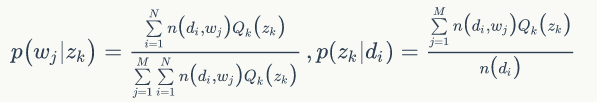
3.重复1、2两步,直到收敛。
▌2.4 LDA
对于 PLSA 模型,贝叶斯学派表示不同意,为什么上帝只有一个 doc-topic 骰子,为什么上帝只有固定 K 个topic-word骰子?

假设我们训练语料有 M 篇 doc,词典中有 V 个word,K 个topic。对于第m 篇文档有 Nm 个词。
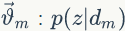
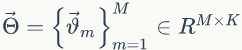
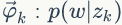
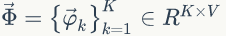
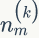
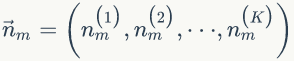
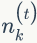
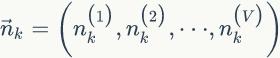

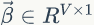
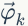
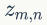
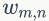
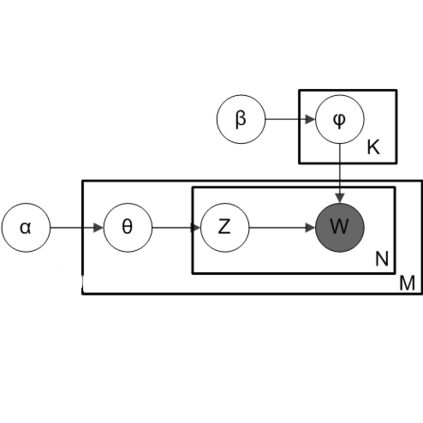
LDA的概率图模型表示如图2.4所示。
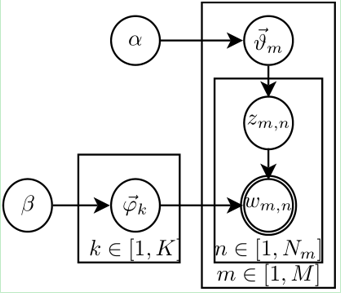
图2.4
1. 联合概率分布

1)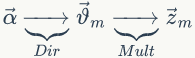
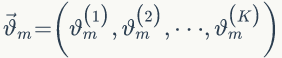
,整篇文档的主题表示为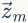
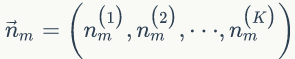
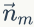
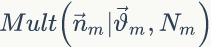
的先验分布为
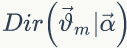
后验分布为(推导过程可以参考1.7节)
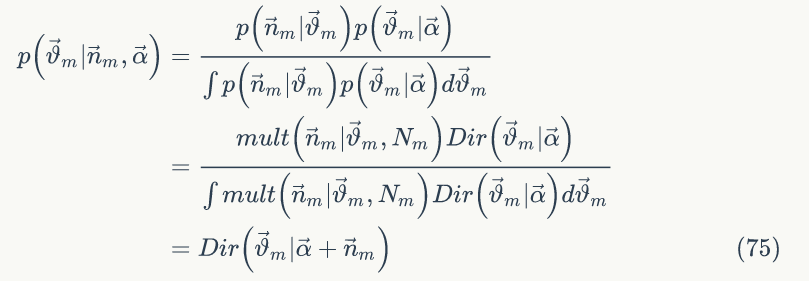
的贝叶斯估计值为
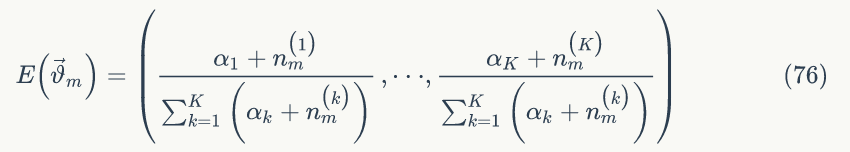
下面我们计算第 m 篇文档的主题概率分布:
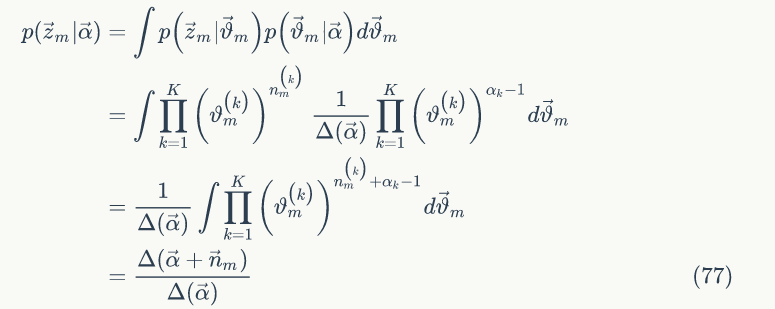
整个语料中的 M 篇文档是相互独立的,所以可以得到语料中主题的概率为:
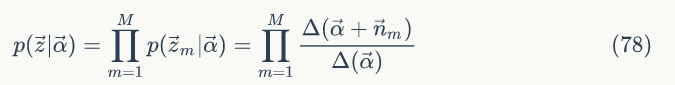
2)
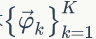
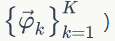
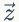
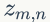
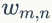
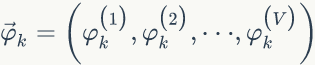
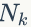
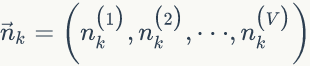
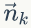
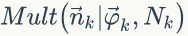
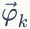
的先验分布为
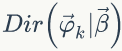
后验分布为(推导过程可以参考1.7节)
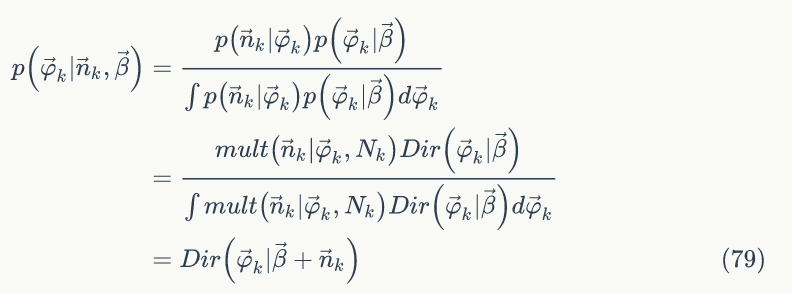
的贝叶斯估计值为
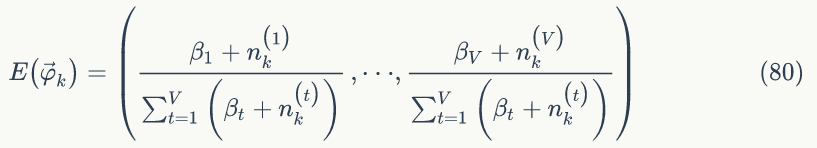
下面我们计算第 k 个主题的词概率分布:
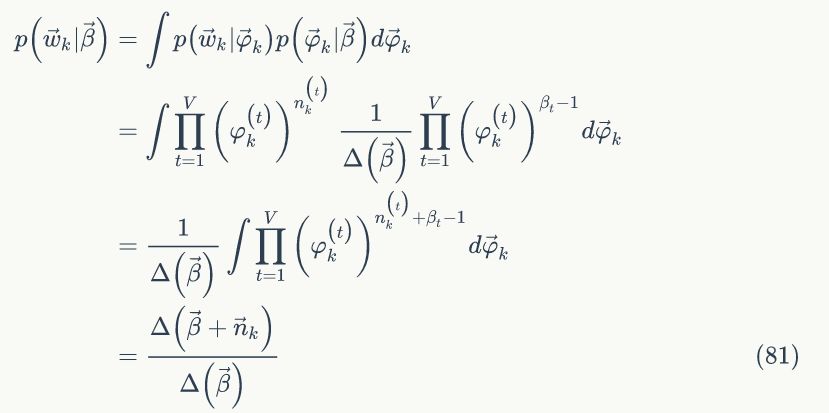
整个语料中的 K 个主题是相互独立的,所以可以得到语料中词的概率为:
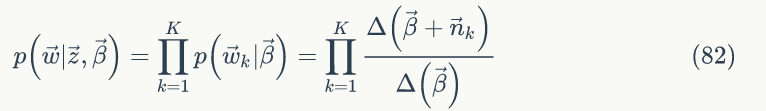
由公式(74)、(78)、(82) 可得联合概率分布为:
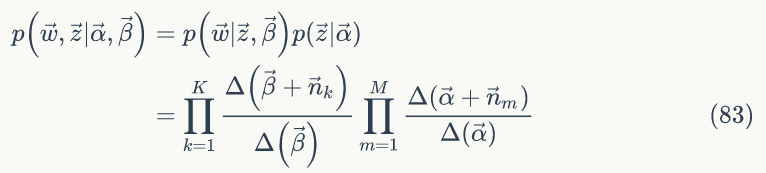
2. Gibbs Sampling
上面我们已经推导出参数的贝叶斯估计公式,但是仍然存在一个问题,公式中的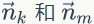
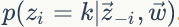
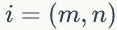
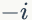
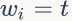
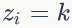
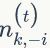

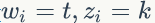
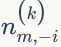
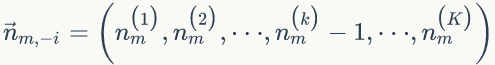
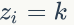

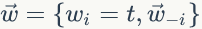
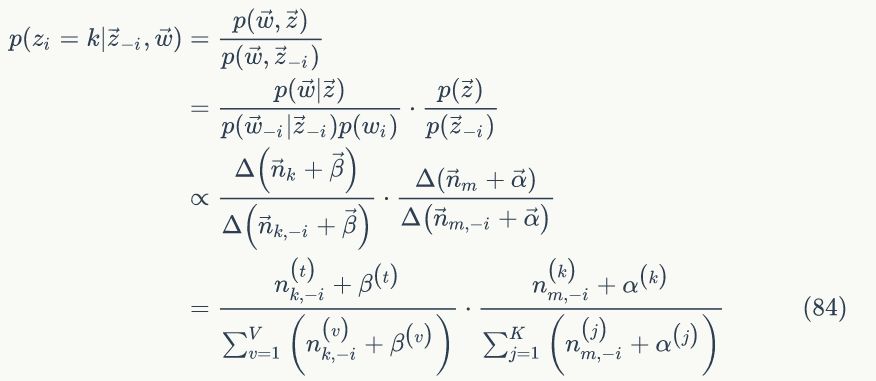
1)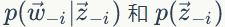
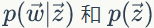
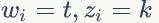
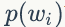
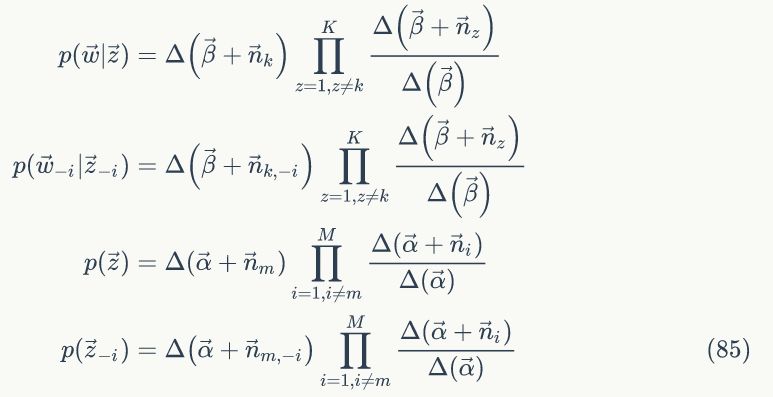
2)我们是推断 i=(m,n) 词 t 的主题为 k 的条件概率
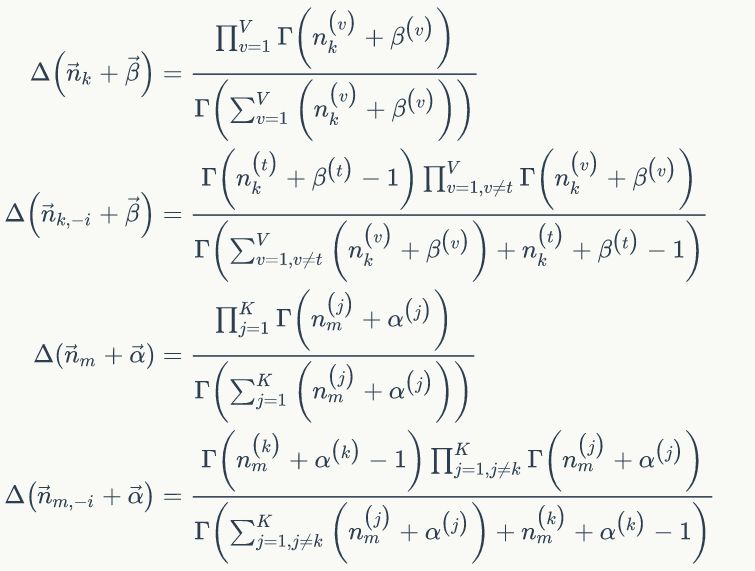
我们再利用另外一种方法推导条件概率:
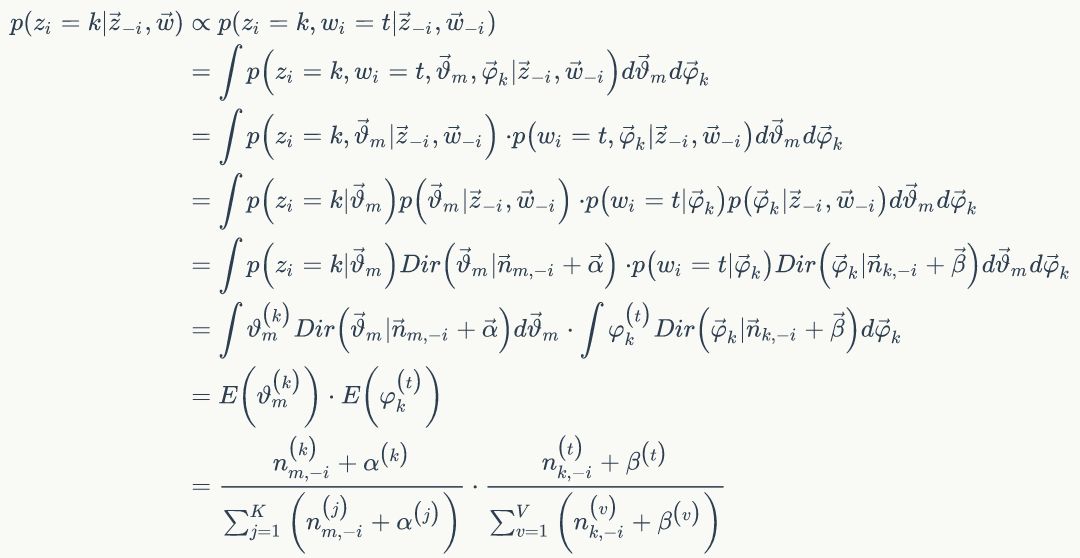
已经推导出条件概率,可以用Gibbs Sampling公式进行采样了。

参考文献
[1] Parameter estimation for text analysis
[2] Probabilistic Latent Semantic Analysis
[3] Latent Dirichlet Allocation
[4] The EM algorithm
作者简介
玉龍,在某知名互联网公司从事技术研发,有深度学习相关研发经验。感兴趣的同学可以关注一下他最近更新的TensorFlow教程:https://cloud.tencent.com/developer/labs/series/10000
原文地址
https://www.zybuluo.com/learning17/note/1167651
注:本文版权归作者所有,转载需获得授权。
——【完】——
在线公开课NLP专场
◆
精彩继续
◆
时间:7月12日 20:00-21:00
扫描海报二维码,免费报名
添加微信csdnai,备注:公开课,加入课程交流群