微软亚研提出VL-BERT:通用的视觉-语言预训练模型
机器之心发布
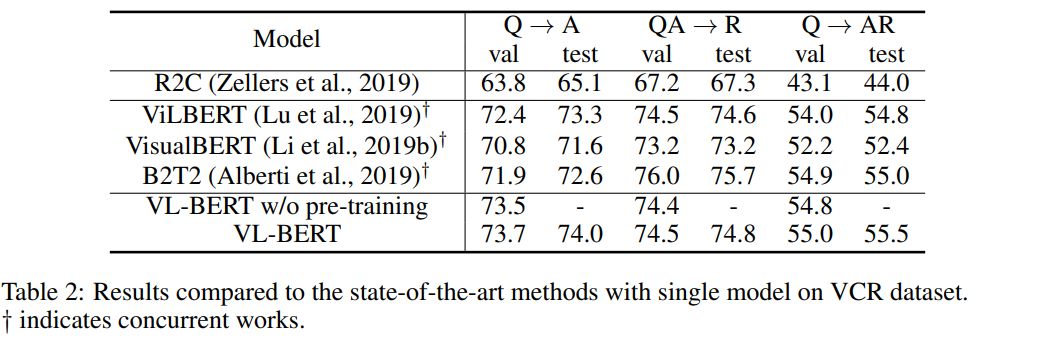
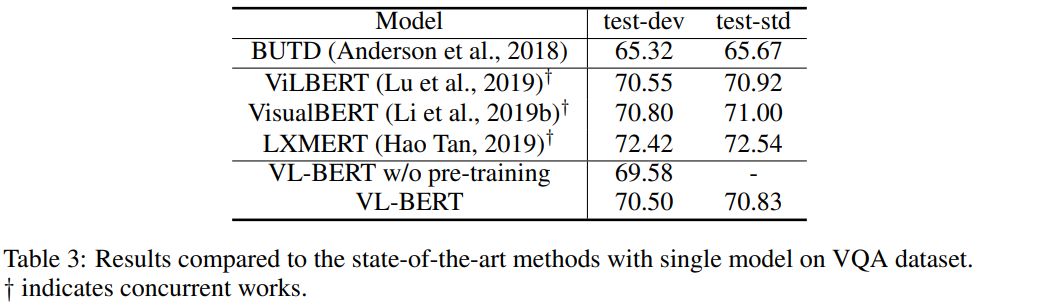
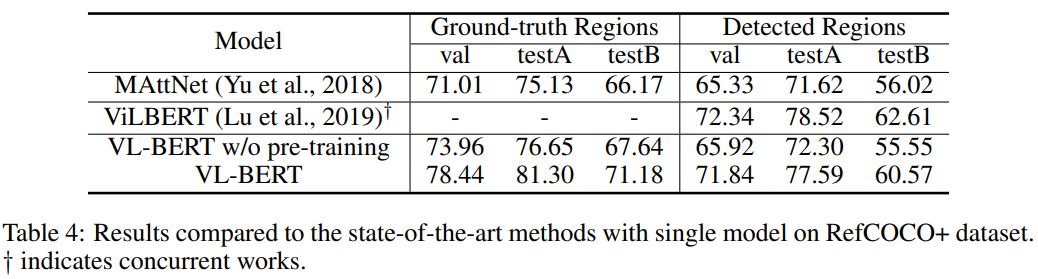
来自中科大、微软亚研院的研究者们提出了一种新型的通用视觉-语言预训练模型(Visual-Linguistic BERT,简称 VL-BERT),该模型采用简单而强大的 Transformer 模型作为主干网络,并将其输入扩展为同时包含视觉与语言输入的多模态形式,适用于绝大多数视觉-语言下游任务。

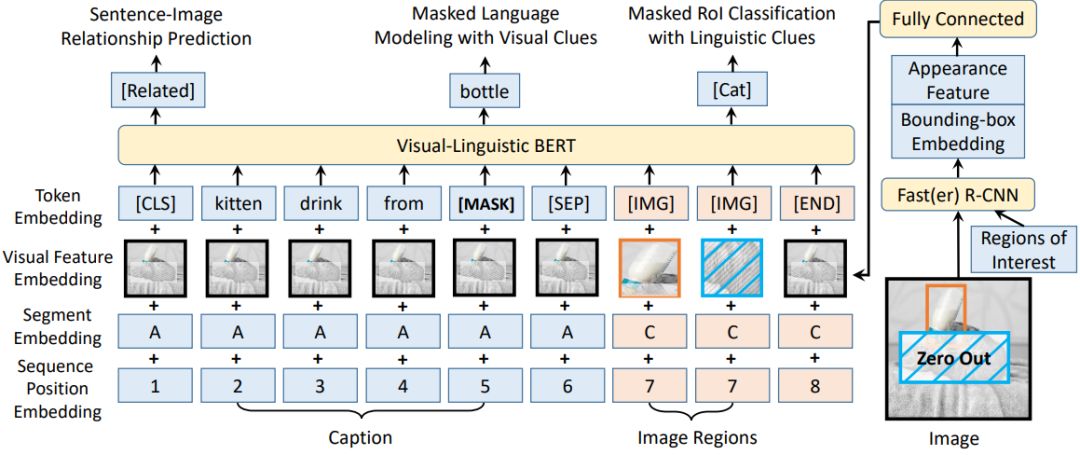
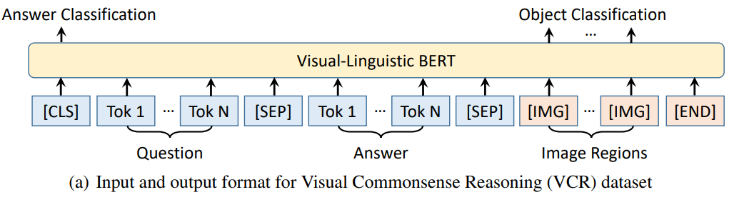
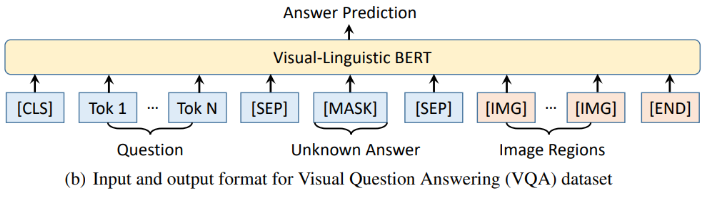
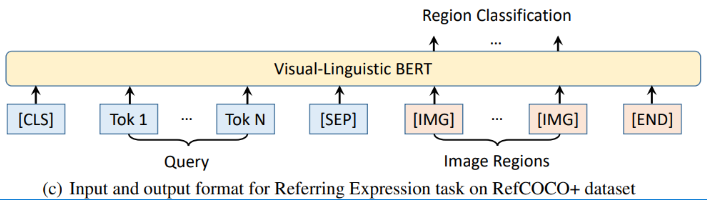
登录查看更多
相关内容
专知会员服务
36+阅读 · 2020年5月20日
专知会员服务
32+阅读 · 2020年2月21日
Arxiv
15+阅读 · 2018年10月11日


相关VIP内容
专知会员服务
36+阅读 · 2020年5月20日
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日