CVPR 2022 | ViT版的Slimming来了,原作者团队打造,参数少,搜索更高效
机器之心专栏
机器之心编辑部
时隔 5 年,network slimming 原作者团队打造出了 ViT 版的 slimming,入选 CVPR 2022。

论文地址:https://arxiv.org/pdf/2201.00814.pdf
代码地址:https://github.com/Arnav0400/ViT-Slim
 正则使得这些系数变得稀疏,同时作者发现由于通常会将卷积核与批量归一(BN)一起使用,因此可以直接使用 BN 层的缩放系数
正则使得这些系数变得稀疏,同时作者发现由于通常会将卷积核与批量归一(BN)一起使用,因此可以直接使用 BN 层的缩放系数
 作为每层卷积的重要性系数,这样就不需要引入额外的参数了。
作为每层卷积的重要性系数,这样就不需要引入额外的参数了。
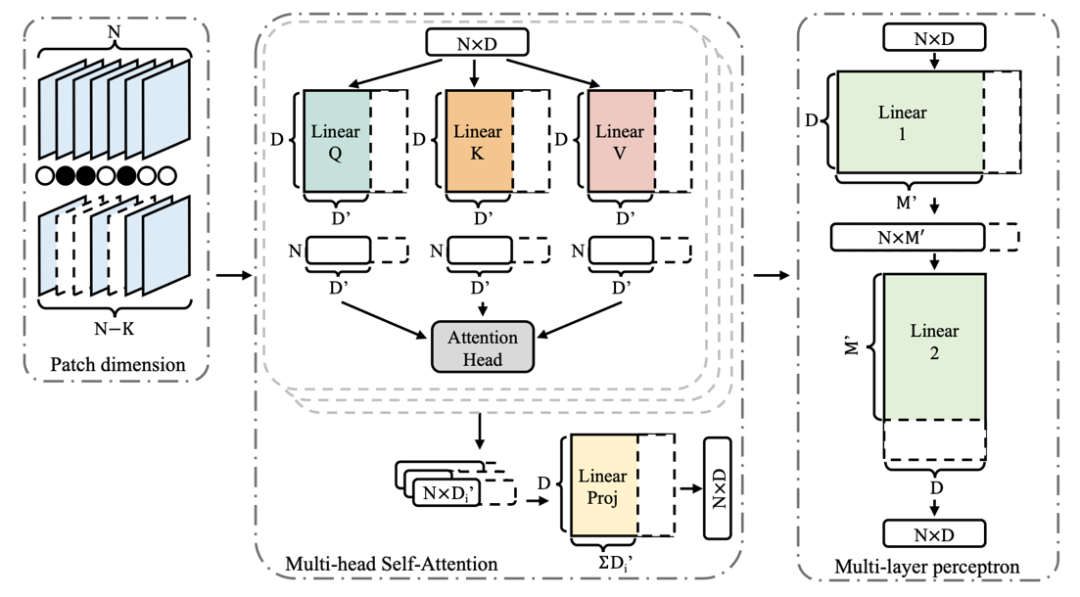
 稀疏正则组成,如下所示:
稀疏正则组成,如下所示:
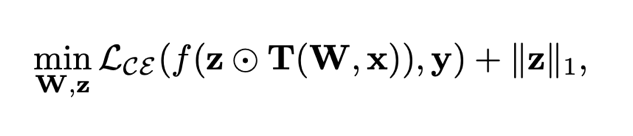
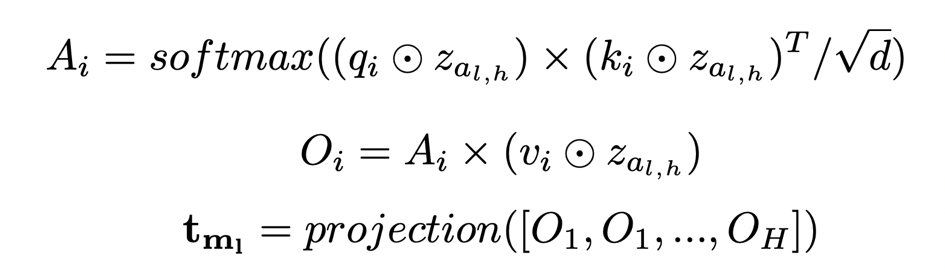
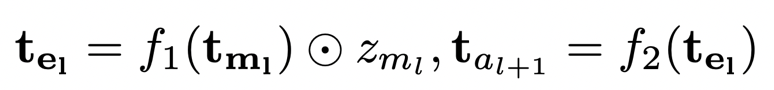

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

Networking:IFIP International Conferences on Networking。
Explanation:国际网络会议。
Publisher:IFIP。
SIT: http://dblp.uni-trier.de/db/conf/networking/index.html
专知会员服务
17+阅读 · 2019年11月17日



相关VIP内容
专知会员服务
17+阅读 · 2019年11月17日
相关资讯
相关论文