知识疫图背后的故事之地区风险预测与基于搜索日志疫情预测技术实践
基于多维度信息的新冠肺炎地区风险预测
图一 国内外疫情可视化项目
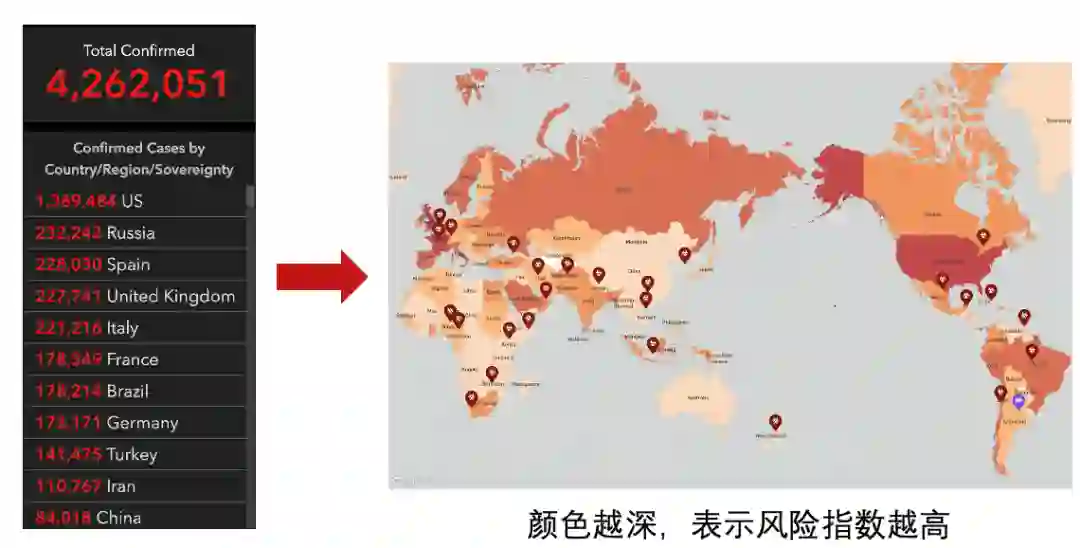
图二 风险指数示例
视频一 知识疫图风险指数动态播放
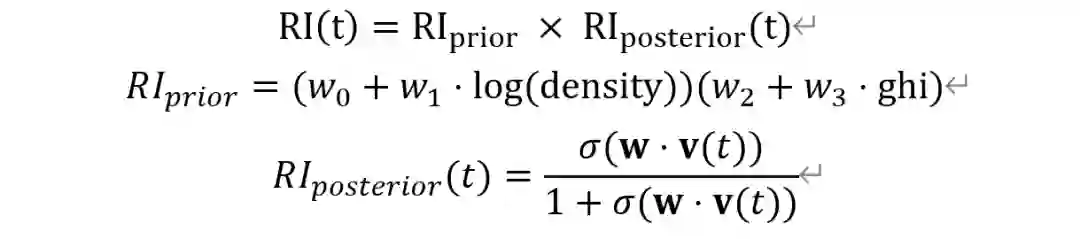
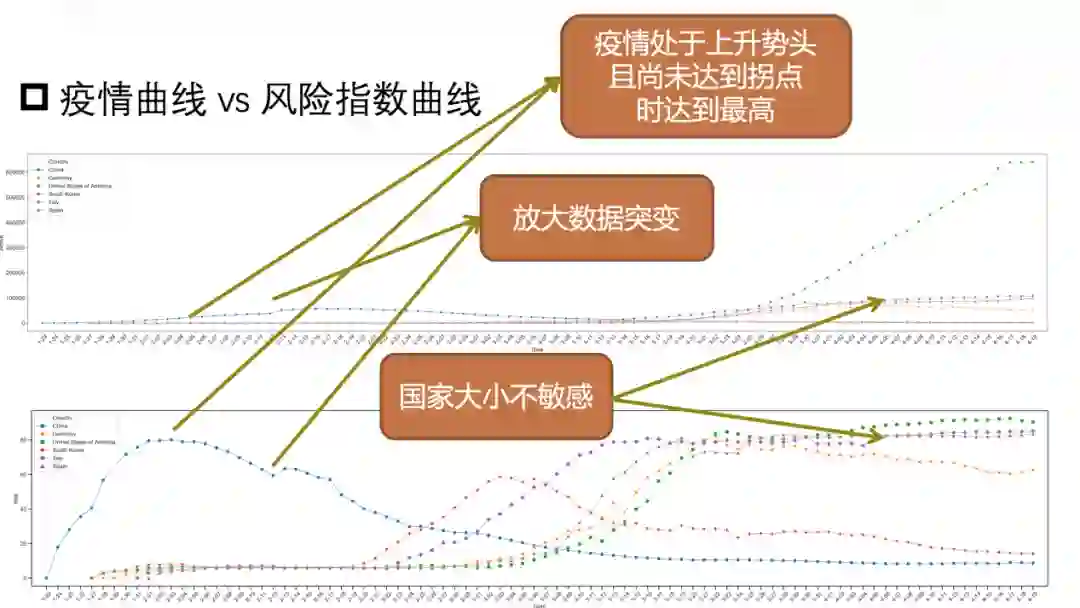
总结来说,知识疫图提出了一种综合多维度信息的地区风险指数评估方法。不需要大量的人工干预,能够基于疫情数据和地区本身的客观情况计算,可以做到与疫情数据同样细粒度的风险评估。从结果上来看,计算得到风险指数能够比较好的反映地区风险情况。下一步的研究目标是希望将新闻事件也考虑进地区风险指数的计算,并将风险指数进一步细化,如出行风险指数,复工风险指数等,同时基于风险指数上线一系列惠及用户的实用功能。
基于搜索日志的新冠肺炎预测
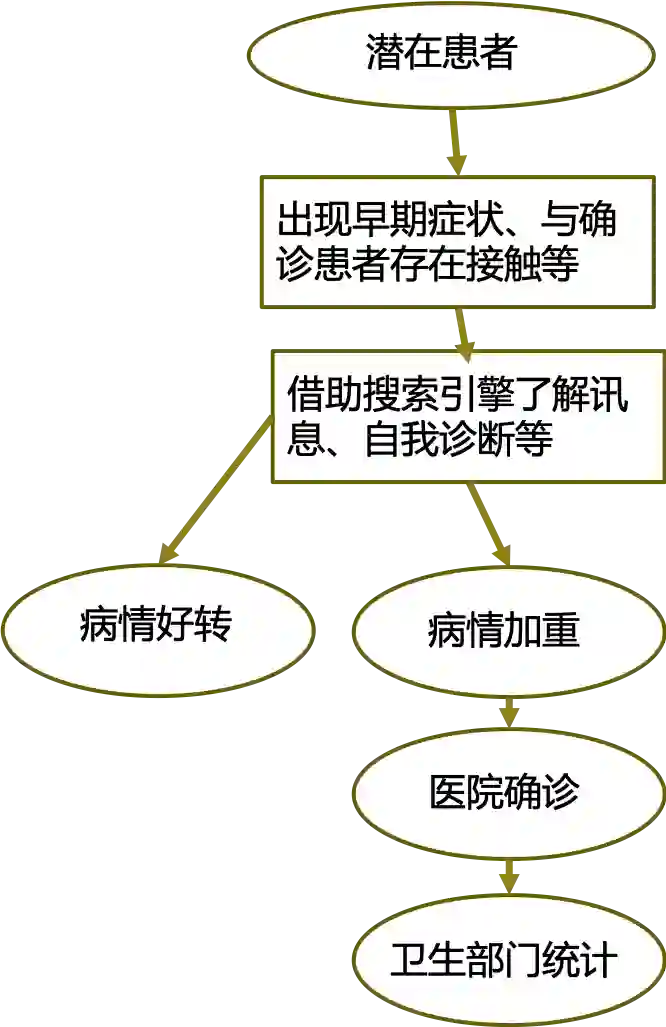
数据筛选
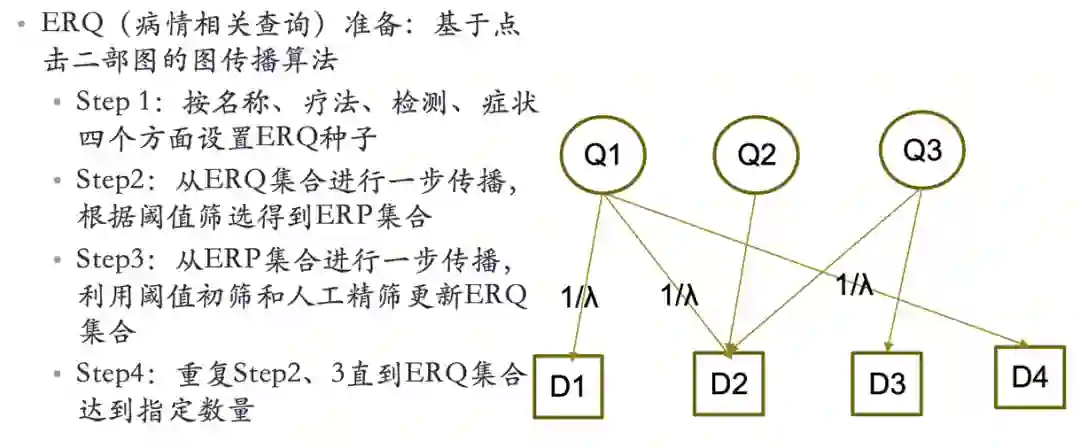
图五 基于点击二部图的图传播算法
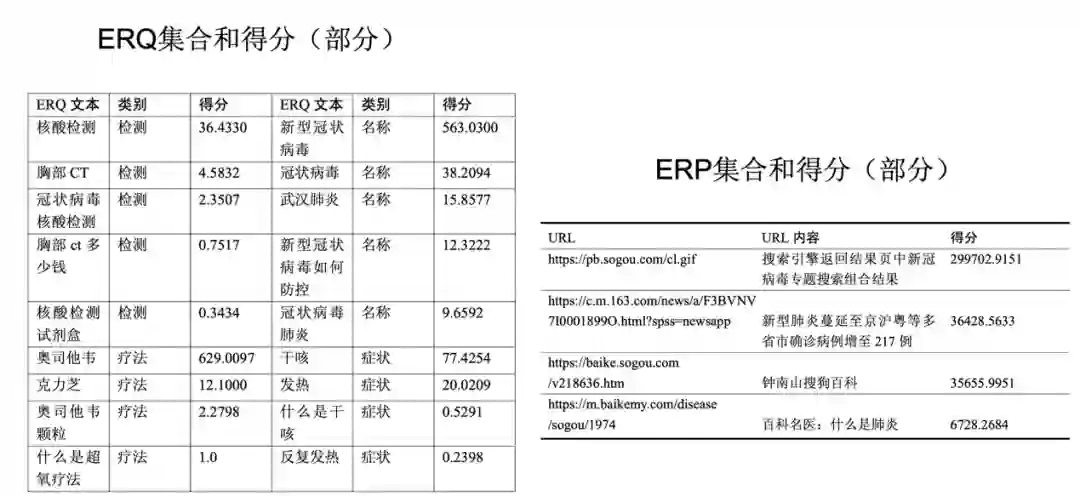
图六 部分 ERQ 集合和得分
数据分布统计
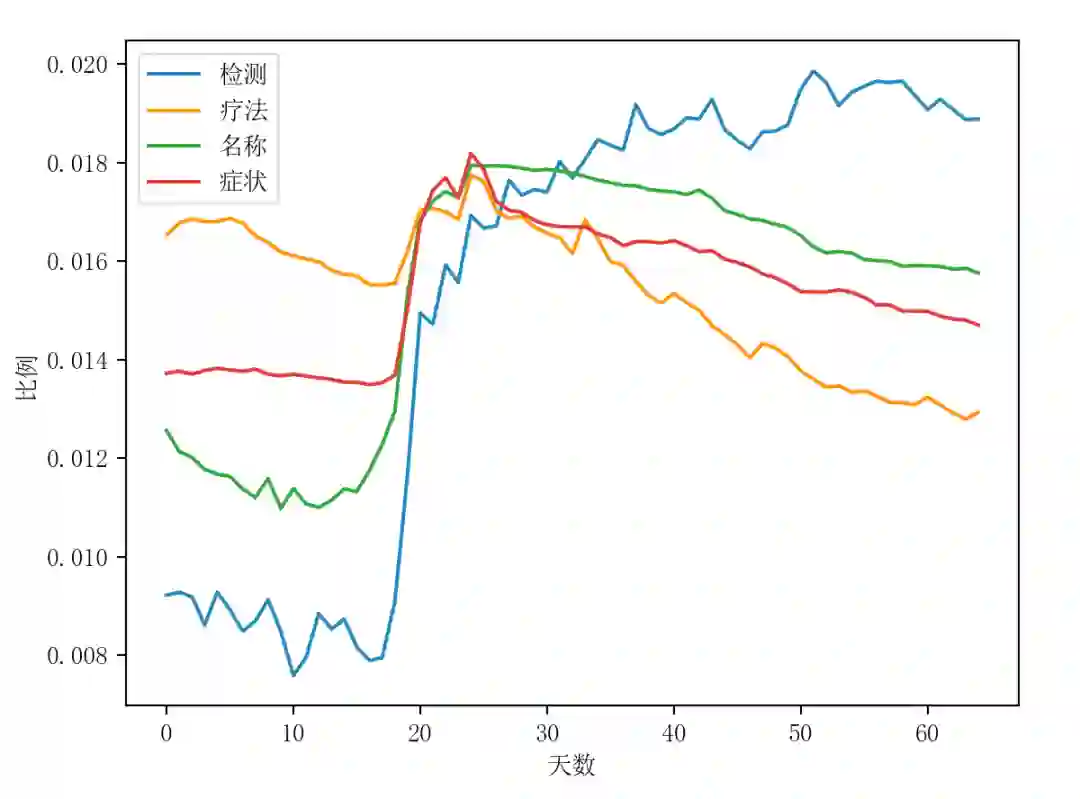
图七 ERQ 种子频率分别
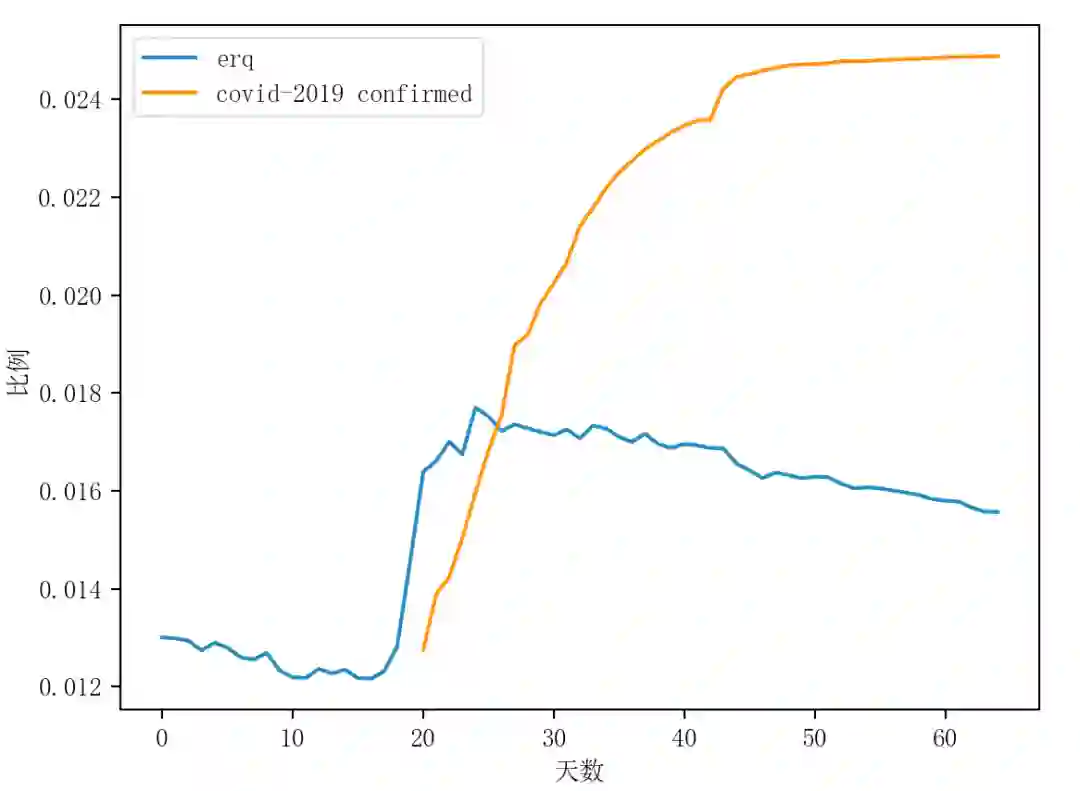
图八 ERQ 集合频率与新冠疫情的趋势对比
结合对实验数据的观察,叶子逸主要考虑了自回归模型(AR,baseline)、长短期记忆网络模型(LSTM,不考虑 ERQ,baseline)、自回归分布滞后模型(ADL,考虑 ERQ)、使用词袋模型和 k-means 聚类融合各类 ERQ 特征的特征聚类的自回归分布滞后模型(ADL,考虑 ERQ)、长短期记忆网络模型(LSTM,考虑 ERQ)等几种不同模型。
为了验证模型的有效性,他将不同模型应用到了预测累计确诊数据(基于历史确诊数据,预测 k 天后的确诊人数)和预测新增与治愈人数(基于疑似数据与新增数据)两项实验任务中,不同模型在两项实验中的结果如图九、图十所示。
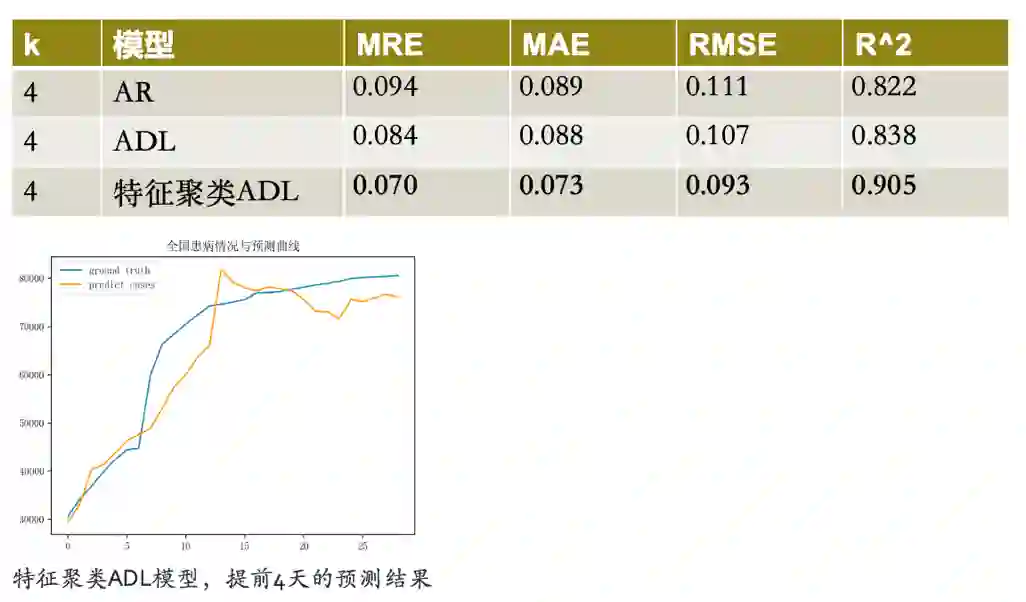
图九 预测累计确诊数据实验结果
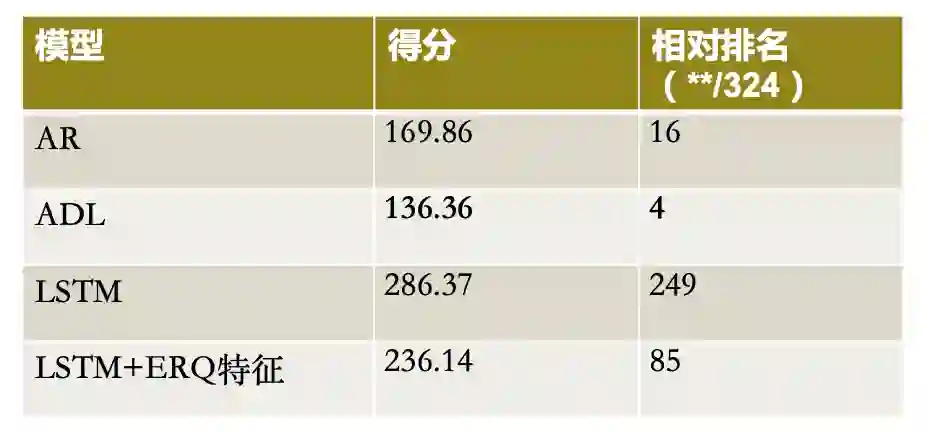
图十 预测新增与治愈人数实验结果
总结
研究发现,引入 ERQ 数据在绝大多数任务中都能够提升病情趋势的预测性能。但引入 ERQ 数据作为传染病预测模型特征时,需要考虑病情趋势相对 ERQ 趋势的滞后效应,滞后天数在 3-5 天,对 ERQ 特征进行聚类后叠加为多个特征比直接叠加效果更好。未来叶子逸将探索分析不同搜索意图下的搜索引擎用户行为,更好地将疫情发展与用户意图、用户行为关联起来。
答疑互动

用基于搜索日志的这种方法预测的时候,不同时期的效果是否会不同呢?

因为舆情的影响,不同时期的效果会有所差别,实验中疫情前中期效果比较好,但到后期新增病例变化不大的时候,效果有一定的下降,这是因为更多的搜索内容是舆情引起的。还有1月21日附近舆情爆发也有一定的影响,需要调整模型。

直播中提到咱们的预测模型中考虑到了疫情数据滞后的问题,那咱们是如何进行补偿和优化的呢?
因为从疑似用户产生搜索行为到确诊存在延迟,所以有一定的滞后现像。需要根据历史的经验和实际疫情与搜索记录的趋势分析来进行确定滞后的时间。其中利用典型症状相关的检索趋势是最为有效的。
请问有将传染病学模型预测结果作为衡量的参考吗?预测结果与传染病学模型的比较结果又怎么样?
这个问题很好,因为传染病学的模型需要的经验参数太多且专业性比较强。即使是网上一些相关基于传染病学模型的预测工作由于参数选取的原因效果差异也比较大,所以我没有实际实现传染病学的模型来进行比较。我觉得设计一个合适的传染病学模型,并尝试引入ERQ特征来进行模型比较是未来可以做的。
请问能不能实现实时或准实时的风险指数预测?
在我们的方法中,风险指数分为与时间无关的先验风险指数和与当前疫情数据有关的后验风险指数两个部分。所以我们的风险指数是随着疫情数据更新的,如果疫情数据是实时的,那么风险指数也是实时的。目前的疫情数据更新是一小时一次,风险指数也是。

那我们是用什么方法来评估风险指数预测结果的可靠性呢?
对于风险指数来说,的确没有一个客观的量化指标来评估可靠性。然而我们认为风险指数更重要的意义是提供在同一标准下一个不同国家和地区的风险状况的对比参考用以指导复产复工。此外,在风险指数的开发过程中,我们也与清华大学医学院、清华大学公共健康研究中心和清华大学社会学系的教授进行了合作,融入了一系列的专家知识,我们认为得到的结果应该是有一定的参考意义的。
风险指数预测的地理尺度最小能到什么程度呢?
理论上与疫情数据的粒度(中国到县/市,美国到 Country,意大利到大区)相同,但是由于地区客观数据(如面积、人口密度)不一定能完全匹配疫情数据的粒度,所以会有所减小,我们也会逐步也会完善这些客观数据的收集。
科学技术的发展为这个时代带来了各方面的进步,无论是我们的日常生活还是面临突发灾难时应对的举措,而在这发展的背后离不开无数科研人员坚持不懈的辛勤探索和研究。在此,除了感谢两位嘉宾带来的精彩分享以外,也感谢他们利用自己的专业知识为疫情做出的贡献,希望大家都可以学有所成、学有所用。之后的 AI TIME 技术专题将继续解密知识疫图智能服务背后的技术实践,学习路漫,下期分享我们不见不散!










