![]()
大家好,我们开源了在 NeurIPS-2020 所提出一个,基于蒙特卡洛树搜索(MCTS)的全新黑盒优化算法(命名为 LA-MCTS)。同时也开源了,近 2 年来我们利用 MCTS 在神经网络结构搜索的工作(命名为 LaNAS)。
https://github.com/facebookresearch/LaMCTS
Neural Architecture Search,全网最全的神经网络结构搜索 pipeline。
-
开源 LaNAS on NASBench101:
无需训练网络,在你笔记本上快速评估 LaNAS。
-
开源 LaNAS 搜索出的模型“LaNet”:
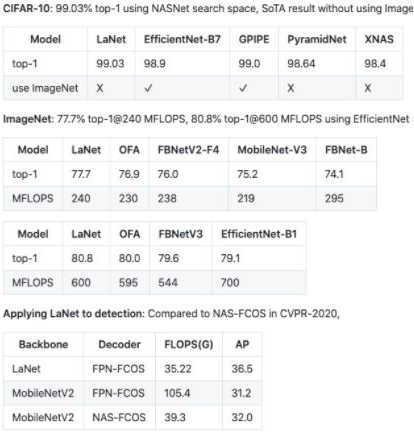
在 CIFAR-10 和 ImageNet 上都取得 SoTA 结果。
-
开源 one-shot/few-shots LaNAS:
只需几个 GPU,快速并且高效完成神经网络结构搜索。含搜索,训练,整套 pipeline。
-
分布式 LaNAS:
让我们用上百个 GPU 来超过最先进的模型。整套 pipeline。
Bag of tricks 模型训练的那些黑科技:我们列出当下训练模型的一些提升点数黑招数。
Black-box optimizations,黑盒优化
-
1 分钟的对比:
只需1分钟,评测 LA-MCTS,和贝叶斯优化及进化算法。
MuJoCo Tasks:应用 LA-MCTS 在机器人,强化学习,并可视化你学出来的策略。
感谢大家,下面是我们这些年在 NAS 的发展方向探索的一个简介,和思考。
![]()
起源:应用蒙特卡洛树搜索在神经网络结构搜索
2017 年初,我的导师从美国国防高级研究计划局的 D3M 项目拿到了一笔项目资金,开启了我们的 AutoML 研究。而我被分配的子任务,就是神经网络结构搜索(NAS)。当时 NAS 研究的 2 篇文章,都是利用强化学习(谷歌的 policy gradients 和 MIT 的 Q-learning)。
我们发现 Q-learning 的 epsilon greedy 非常简单的同等对待了所有的状态(states),并不考虑每个 states 过去探索了多少次,所以并不能很好的去平衡利用(exploitation)和探索(exploration)。
从这点出发,我们考虑对每个状态去建模,来更好的平衡利用和探索,来提高搜索效率。而蒙特卡洛树搜索(MCTS)正是对每一个状态建模,利用 UCT 来动态的平衡利用和探索。同时,AlphaGo 的成功证实 MCTS 在大规模状态空间下效果非常好。在这样的背景下,我们开发第一个基于 MCTS 的 NAS 算法,并命名为 AlphaX。
AlphaX 构建网络和 MIT 的 Q-learning 算法相似。从一个空网络开始,根据动作集,比如添加一个 conv 或者 pooling,逐层构建一个网络架构(s→a→s’)。因为训练一个网络非常慢,AlphaX 提出利用一个价值函数预测器(value function predictor)来预测当下状态下的子网络们的性能。
这个价值函数器输入就是一个网络架构,输出就是预测的该网络的精度。同时我们验证了,NAS 能够提升很多下游的视觉应用,比如风格迁移,目标检测等。详情请见
[1]
。
![]()
学习蒙特卡洛树里的动作集,从LaNAS到LA-MCTS
基于 AlphaX,我 FB 的导师
@田渊栋洞察到动作集在 AlphaX 对搜索效率有着显著的影响。为了证实这个想法,我们设计了动作集 sequential 和 global。
动作集 sequential 就是按照逐层构建网络的思路,一步步的增加 conv 或者 pooling,并指定每层的参数;而动作集 global 则首先划定网络的深度,比如 10 层网络。然后同时给这 10 层网络指定每层的种类,参数等。
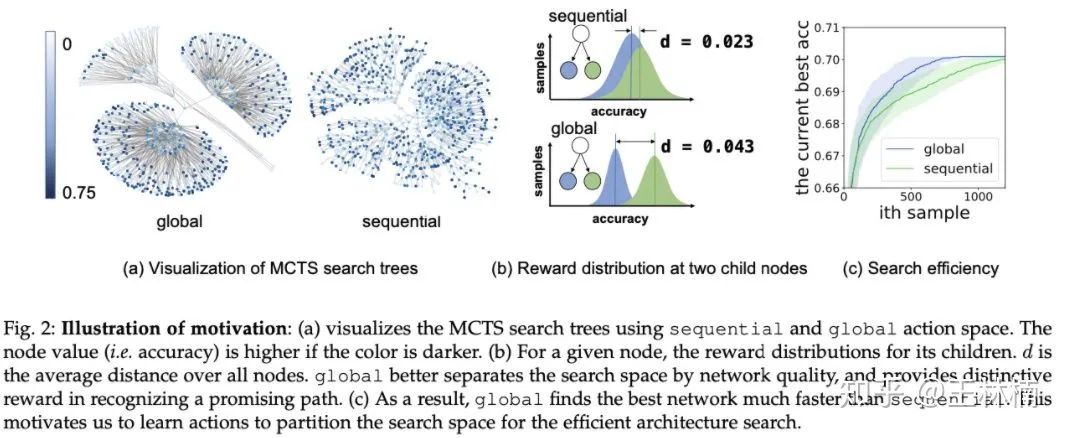
我们发现动作集 global 的搜索效率显著高于动作集 sequential,并且可视化了状态空间,如下图。
![]()
直观上而言,状态空间在 global 的动作集下,好的状态(深色)和差的状态(浅色)区分的很好,不像 sequential 混杂在一起。这样搜索算法可以很快找到一个好的区域,所以效率更高。
基于这个观察,促使我们去给 MCTS 学习动作集,并提出了Latent Action Monte Carlo Tree Search(LA-MCTS)。
![]()
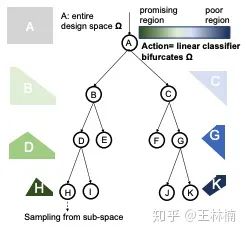
LA-MCTS 的核心思想就是,在每一个树的节点上,我们想学到一个边届,根据当下的采样点(既网络和精度),能够把搜索空间分为一个好的子空间(左节点),和一个坏的子空间(右节点),如上图。
而这里的隐动作集(Latent Action)就是,从当下节点选择去左/右孩子。至于动作的选择,在每个节点是根据 UCT 公式来决定。因为每个节点对应一个搜索空间,这个搜索空间上有相应的样本。
每个孩子上对应搜索空间的样本的个数就是 UCT 里的 n,而这些样本性能的平均值就是 UCT 里的 v。当我们对搜索空间建立这样的一个搜索树,随着树深度的增加,在搜索空间找到好的区域也越来越精确。
我们最初把这个想法应用在了 NAS,并构建了一个 NAS 系统命名为 LaNAS
[2]
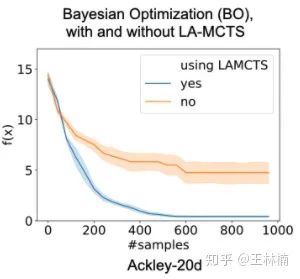
。对比贝叶斯优化和进化算法,LaNAS 在 NAS 的基准数据集 NASBench-101上取得了显著的提升。所以我们又扩展了 LaNAS 成为了 LA-MCTS 去做应用更广的黑盒优化。
从 LaNAS 到 LA-MCTS,核心更新有:1)LA-MCTS 把 LaNAS 里的边界扩展成一个非线性边界,2)LA-MCTS 在采样的时候利用贝叶斯优化来选择样本。最后,LA-MCTS 在各种测试函数和 MuJoCo 上取得了显著的提升,详见
[3]
。
![]()
![]()
早在 2011 年,Rémi Munos(DeepMind)提出利用MCTS来分割搜索空间用来优化一个黑盒函数
[4]
,然后,剑桥大学和MIT,有很多工作把这种切分搜索空间的思想用在了高维贝叶斯优化
[5] [6]
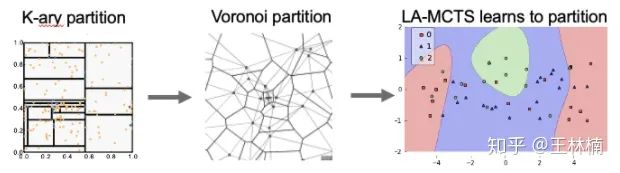
。但是这些工作一般都会采用一个 k-ary 区块切分(如下图)。
2020 年,MIT 的 Beomjoon Kim 在
[7]
展示出利用沃罗诺伊图(Voronoi Graph)去切分搜索空间,结果会更好。我们的工作,LA-MCTS,则是利用了 learning 的法则,根据当下样本来学习分割方法,来提高搜索效率。
![]()
![]()
贝叶斯优化(BO)由一个 surrogate 和一个 acquisition 组成。基于高斯过程的 surrogate 往往因为计算,随样本数(N)呈 N^3 增加,而受限于小规模应用。很多工作已经很好的解决了这个问题,比如利用贝叶斯网络去近似均值和方差。
所以大规模采样在贝叶斯优化已不是问题。但是在连续空间下,往往一个问题的纬度 > 10 后,BO 就会出现过度探索搜索空间边界的问题
[6]
。因为 LA-MCTS 分割了搜索空间,UCT 会动态探索子空间,避免了 BO 上述的问题。
更多细节,及和遗传算法的对比,请见 LA-MCTS 的 related works 章节
[8]
。
![]()
我认为是重要的。以下是我观测到的一些趋势及我的思考。
1)最近有些文章展示随机搜索都可以达到很好的结果,那么是不是意味着搜索不重要了?
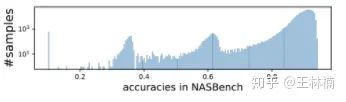
首先这些文章是说随机搜索得到的结果还不错,是一个非常强的对比基准。这个往往因为目前的搜索空间的设计,导致大部分网络结果都很好,比如下图所呈现的 NASBench-101 中 42 万个网络的分布(横轴是精度,纵轴是这个精度下有多少网络)。所以找出一个工作还不错的网络并不难。
![]()
2) 既然搜索空间的设计影响很大,那么是不是更应该把注意力放在设计搜索空间,而不是搜索?
我觉得这个问题应该站在不同的角度。首先,近几年神经网络的高速发展让我们在设计搜索空间的时候有了很多先验经验,所以设计出来的搜索域里的网络都不会太差。在一些传统的视觉应用,搜索的贡献可能就不如加各种 tricks 或者调参数在工程中来的更实际一些。
但是如果当我们遇到一个新的任务,比如设计一个神经网络去调度网络节点。由于先验经验很少,这个时候搜索就可以极大的加速我们设计网络的速度。并且搜索可以提供很多的经验去让我们改进搜索空间。
3)基于搜索方法的 NAS 和 DARTS 类算法的对比。
以 DARTS 为代表的 one-shot NAS 方法跑的很快,是因为利用了一个超级网络(Supernet)去近似每个网络的性能。
在这个过程中,Supernet 相当提供一个网络性能的预测,然后利用 SGD 在 Supernet 上去找一个比较好的结果。这里 Supernet 和 Search 也是可以分开,而且分开后更易分别提高这两个部分。
所以只需要把 Supernet 的概念应用在传统搜索方法上,也是可以很快得到结果。SGD 的问题是很容易卡在一个局部最优,而且目前 SoTA 的结果基本都是利用传统搜索方法直接,或者利用一个 supernet 搜索出来的。
![]()
![]()
[1] Neural Architecture Search using Deep Neural Networks and Monte Carlo Tree Search, AAAI-2020.
[2] Sample-Efficient Neural Architecture Search by Learning Action Space, 2019
[3] Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search, NeurIPS 2020.
[4] Optimistic optimization of a deterministic function without the knowledge of its smoothness, NeurIPS 2011.
[5] Batched Large-scale Bayesian Optimization in High-dimensional Spaces, AISTATS 2018.
[6] Heteroscedastic Treed Bayesian Optimisation, 2014.
[7] Monte Carlo Tree Search in continuous spaces using Voronoi optimistic optimization with regret bounds, AAAI-2020.
[8] Bock: Bayesian optimization with cylindrical kernels
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()